







自动编码器
Deep Learning最简单的一种方法是利用人工神经网络的特点,人工神经网络(ANN)本身就是具有层次结构的系统,如果给定一个神经网络,我们假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。自然地,我们就得到了输入I的几种不同表示(每一层代表一种表示),这些表示就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
先暂且不谈神经网络、深度学习,仅是自编码器的话,其原理很简单。 自编码器可以理解为一个试图去还原其原始输入的系统 。如下图所示。

图中,虚线蓝色框内就是一个自编码器模型,它由编码器(Encoder)和解码器(Decoder)两部分组成,本质上都是对输入信号做某种变换。编码器将输入信号x变换成编码信号y,而解码器将编码y转换成输出信号~x。即
而自编码器的目的是,让输出~x尽可能复现输入x,即 tries to copy its input to its output 。但是,这样问题就来了——如果f和g都是恒等映射,那不就恒有~x=x了?不错,确实如此,但这样的变换——没有任何卵用啊!因此,我们经常对中间信号y(也叫作“编码”)做一定的约束,这样,系统往往能学出很有趣的编码变换f和编码y。
这里强调一点,对于自编码器,我们往往并不关系输出是啥(不关心解码),我们真正关心的是 中间层的编码 ,或者说是 从输入到编码的映射 。可以这么想,在我们强迫编码y和输入x不同的情况下,系统还能够去复原原始信号x,那么说明 编码y已经承载了原始数据的所有信息,但以一种不同的形式 !这就是 特征提取 啊,而且是自动学出来的!实际上,自动学习原始数据的特征表达也是神经网络和深度学习的核心目的之一。
- 当隐层维度小于输入数据维度。也就是说从输入层→隐含层的变换是一种降维的操作,网络试图以更小的维度去描述原始数据而尽量不损失数据信息。实际上,当每两层之间的变换均为线性,且监督训练的误差是二次型误差时,该网络等价于PCA!
- 当隐层维度大于输入数据维度。这又有什么用呢?其实不好说,但比如我们同时约束h的表达尽量稀疏(有大量维度为0,未被激活),此时的编码器便是大名鼎鼎的“稀疏自编码器”。可为什么稀疏的表达就是好的?这就说来话长了,有人试图从人脑机理对比,即人类神经系统在某一刺激下,大部分神经元是被抑制的。个人觉得,从特征的角度来看更直观些,稀疏的表达意味着系统在尝试去 特征选择 ,找出大量维度中真正重要的若干维。
具体过程简单的说明如下:
1)给定无标签数据,用非监督学习学习特征:
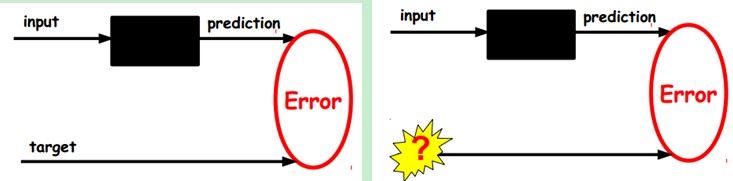
在我们之前的神经网络中,如第一个图,我们输入的样本是有标签的,即(input, target),这样我们根据当前输出和target(label)之间的差去改变前面各层的参数,直到收敛。但现在我们只有无标签数据,也就是右边的图。那么这个误差怎么得到呢?
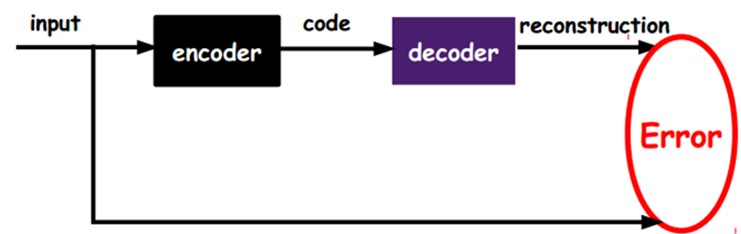
如上图,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?我们加一个decoder解码器,这时候decoder就会输出一个信息,如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。
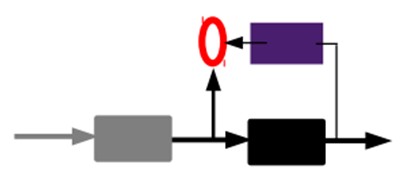
2)通过编码器产生特征,然后训练下一层。这样逐层训练:
那上面我们就得到第一层的code,我们的重构误差最小让我们相信这个code就是原输入信号的良好表达了,或者牵强点说,它和原信号是一模一样的。接着,我们将第一层输出的code当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输出的code,也就是原输入信息的第二个表达了。其他层就同样的方法炮制就行了(训练这一层,前面层的参数都是固定的,并且他们的decoder已经没用了,都不需要了)。
需要注意的是,整个网络的训练不是一蹴而就的,而是逐层进行。如果按n→m→k结构,实际上我们是先训练网络n→m→n,得到n→m的变换,然后再训练m→k→m,得到m→k的变换。最终堆叠成SAE,即为n→m→k的结果,整个过程就像一层层往上盖房子,这便是大名鼎鼎的 layer-wise unsuperwised pre-training (逐层非监督预训练),正是导致深度学习(神经网络)在2006年第3次兴起的核心技术。
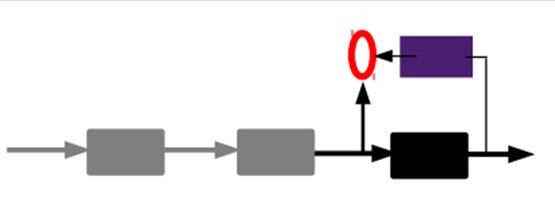
3)有监督微调:
经过上面的方法,我们就可以得到很多层了。至于需要多少层(或者深度需要多少,这个目前本身就没有一个科学的评价方法)需要自己试验调了。每一层都会得到原始输入的不同的表达。当然了,我们觉得它是越抽象越好了,就像人的视觉系统一样。
到这里,这个AutoEncoder还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如罗杰斯特回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)去训练。
也就是说,这时候,我们需要将最后层的特征code输入到最后的分类器,通过有标签样本,通过监督学习进行微调,这也分两种,一个是只调整分类器(黑色部分):
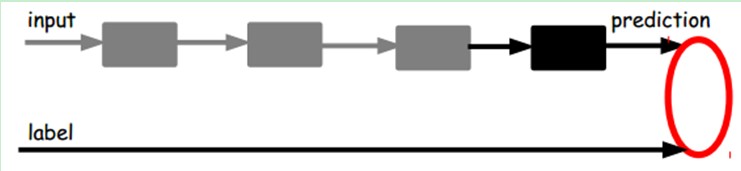
另一种:通过有标签样本,微调整个系统:(如果有足够多的数据,这个是最好的。end-to-end learning端对端学习)
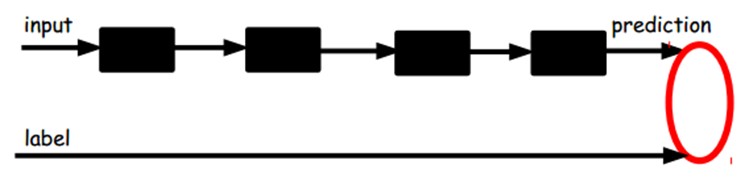
一旦监督训练完成,这个网络就可以用来分类了。神经网络的最顶层可以作为一个线性分类器,然后我们可以用一个更好性能的分类器去取代它。
在研究中可以发现,如果在原有的特征中加入这些自动学习得到的特征可以大大提高精确度,甚至在分类问题中比目前最好的分类算法效果还要好!
一、稀疏编码器
Sparse AutoEncoder稀疏自动编码器:
如前所示,这种模型背后的思想是,高维而稀疏的表达是好的。一般而言,我们不会指定隐层表达h中哪些节点是被抑制的(对于sigmoid单元即输出为0),而是指定一个稀疏性参数ρ,代表隐藏神经元的平均活跃程度(在训练集上取平均)。比如,当ρ=0.05时,可以认为隐层节点在95%的时间里都是被一直的,只有5%的机会被激活。实际上,为了满足这一条件,隐层神经元的活跃度需要接近于0。
那么,怎么从数学模型上做到这点呢?思路也不复杂,既然要求平均激活度为ρ,那么只要引入一个度量,来衡量神经元i的实际激活度^ρi与期望激活度ρ之间的差异即可,然后将这个度量添加到目标函数作为正则,训练整个网络即可。那么,什么样的度量适合这个任务呢?有过概率论、信息论基础的同学应该很容易想到它——相对熵,也就是KL散度(KL divergence)。 在信息论中,KL(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。
这一惩罚因子有如下性质,当  时
时  ,并且随着
,并且随着  与
与  之间的差异增大而单调递增。举例来说,在下图中假设平均激活度ρ=0.2。
之间的差异增大而单调递增。举例来说,在下图中假设平均激活度ρ=0.2。
 时达到它的最小值0,而当
靠近0或者1的时候,相对熵则变得非常大(其实是趋向于
时达到它的最小值0,而当
靠近0或者1的时候,相对熵则变得非常大(其实是趋向于
 )。所以,最小化这一惩罚因子具有使得
靠近
的效果。
)。所以,最小化这一惩罚因子具有使得
靠近
的效果。
如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
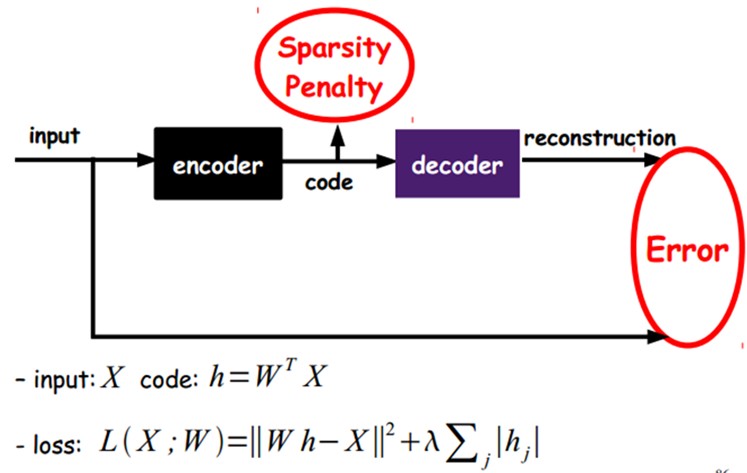
如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)。
Sparse autoencoder的一个网络结构图如下所示:

自编码神经网络尝试学习一个  的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出
的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出  接近于输入
接近于输入  。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张
。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张  图像(共100个像素)的像素灰度值,于是
图像(共100个像素)的像素灰度值,于是  ,其隐藏层
,其隐藏层  中有50个隐藏神经元。注意,输出也是100维的
中有50个隐藏神经元。注意,输出也是100维的  。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量
。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量  中重构出100维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入
中重构出100维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入  都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
我们刚才的论述是基于隐藏神经元数量较小的假设。但是即使隐藏神经元的数量较大(可能比输入像素的个数还要多),我们仍然通过给自编码神经网络施加一些其他的限制条件来发现输入数据中的结构。具体来说,如果我们给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。
稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。这里我们假设的神经元的激活函数是sigmoid函数。如果你使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的。
注意到  表示隐藏神经元
表示隐藏神经元  的激活度,但是这一表示方法中并未明确指出哪一个输入 带来了这一激活度。所以我们将使用
的激活度,但是这一表示方法中并未明确指出哪一个输入 带来了这一激活度。所以我们将使用  来表示在给定输入为 情况下,自编码神经网络隐藏神经元 的激活度。 进一步,让
来表示在给定输入为 情况下,自编码神经网络隐藏神经元 的激活度。 进一步,让
![\begin{align}\hat\rho_j = \frac{1}{m} \sum_{i=1}^m \left[ a^{(2)}_j(x^{(i)}) \right]\end{align}](https://i-blog.csdnimg.cn/blog_migrate/f967513eec9d1741b0561d9bf0a9ff0c.png)
表示隐藏神经元 的平均活跃度(在训练集上取平均)。我们可以近似的加入一条限制

其中, 是稀疏性参数,通常是一个接近于0的较小的值(比如  )。换句话说,我们想要让隐藏神经元 的平均活跃度接近0.05。为了满足这一条件,隐藏神经元的活跃度必须接近于0。
)。换句话说,我们想要让隐藏神经元 的平均活跃度接近0.05。为了满足这一条件,隐藏神经元的活跃度必须接近于0。
为了实现这一限制,我们将会在我们的优化目标函数中加入一个额外的惩罚因子,而这一惩罚因子将惩罚那些 和 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种:

这里,  是隐藏层中隐藏神经元的数量,而索引 依次代表隐藏层中的每一个神经元。如果你对相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是基于它的。于是惩罚因子也可以被表示为
是隐藏层中隐藏神经元的数量,而索引 依次代表隐藏层中的每一个神经元。如果你对相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是基于它的。于是惩罚因子也可以被表示为

其中  是一个以 为均值和一个以 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法。(如果你没有见过相对熵,不用担心,所有你需要知道的内容都会被包含在这份笔记之中。)
是一个以 为均值和一个以 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法。(如果你没有见过相对熵,不用担心,所有你需要知道的内容都会被包含在这份笔记之中。)
这一惩罚因子有如下性质,当 时 ,并且随着 与 之间的差异增大而单调递增。举例来说,在下图中,我们设定  并且画出了相对熵值
并且画出了相对熵值  随着 变化的变化。
随着 变化的变化。

我们可以看出,相对熵在 时达到它的最小值0,而当 靠近0或者1的时候,相对熵则变得非常大(其实是趋向于)。所以,最小化这一惩罚因子具有使得 靠近 的效果。 现在,我们的总体代价函数可以表示为

其中  如之前所定义,而
如之前所定义,而  控制稀疏性惩罚因子的权重。 项则也(间接地)取决于
控制稀疏性惩罚因子的权重。 项则也(间接地)取决于  ,因为它是隐藏神经元 的平均激活度,而隐藏层神经元的激活度取决于 。
,因为它是隐藏神经元 的平均激活度,而隐藏层神经元的激活度取决于 。
为了对相对熵进行导数计算,我们可以使用一个易于实现的技巧,这只需要在你的程序中稍作改动即可。具体来说,前面在后向传播算法中计算第二层(  )更新的时候我们已经计算了
)更新的时候我们已经计算了

现在我们将其换成

就可以了。
有一个需要注意的地方就是我们需要知道  来计算这一项更新。所以在计算任何神经元的后向传播之前,你需要对所有的训练样本计算一遍前向传播,从而获取平均激活度。如果你的训练样本可以小到被整个存到内存之中(对于编程作业来说,通常如此),你可以方便地在你所有的样本上计算前向传播并将得到的激活度存入内存并且计算平均激活度 。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度
来计算这一项更新。所以在计算任何神经元的后向传播之前,你需要对所有的训练样本计算一遍前向传播,从而获取平均激活度。如果你的训练样本可以小到被整个存到内存之中(对于编程作业来说,通常如此),你可以方便地在你所有的样本上计算前向传播并将得到的激活度存入内存并且计算平均激活度 。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度  被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
证明上面算法能达到梯度下降效果的完整推导过程不再本教程的范围之内。不过如果你想要使用经过以上修改的后向传播来实现自编码神经网络,那么你就会对目标函数  做梯度下降。使用梯度验证方法,你可以自己来验证梯度下降算法是否正确。。
做梯度下降。使用梯度验证方法,你可以自己来验证梯度下降算法是否正确。。
损失函数的偏导数的求法:
如果不加入稀疏规则,则正常情况下由损失函数求损失函数偏导数的过程如下:

而加入了稀疏性后,神经元节点的误差表达式由公式:

变成公式:

梯度下降法求解:
有了损失函数及其偏导数后就可以采用梯度下降法来求网络最优化的参数了,整个流程如下所示:

从上面的公式可以看出,损失函数的偏导其实是个累加过程,每来一个样本数据就累加一次。这是因为损失函数本身就是由每个训练样本的损失叠加而成的,而按照加法的求导法则,损失函数的偏导也应该是由各个训练样本所损失的偏导叠加而成。从这里可以看出,训练样本输入网络的顺序并不重要,因为每个训练样本所进行的操作是等价的,后面样本的输入所产生的结果并不依靠前一次输入结果(只是简单的累加而已,而这里的累加是顺序无关的)。
二、降噪编码器
当采用无监督的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在网络的可视层(即数据的输入层)引入随机噪声,这种方法称为Denoise Autoencoder(简称dAE),由Bengio在08年提出,见其文章Extracting and composing robust features with denoising autoencoders.使用dAE时,可以用被破坏的输入数据重构出原始的数据(指没被破坏的数据),所以它训练出来的特征会更鲁棒。本篇博文主要是根据Benigio的那篇文章简单介绍下dAE,然后通过2个简单的实验来说明实际编程中该怎样应用dAE。这2个实验都是网络上现成的工具稍加改变而成,其中一个就是matlab的Deep Learning toolbox,见https://github.com/rasmusbergpalm/DeepLearnToolbox,另一个是与python相关的theano,参考:http://deeplearning.net/tutorial/dA.html.
基础知识:
首先来看看Bengio论文中关于dAE的示意图,如下:

由上图可知,样本x按照qD分布加入随机噪声后变为 ,按照文章的意思,这里并不是加入高斯噪声,而是以一定概率使输入层节点的值清为0,这点与上篇博文介绍的dropout(Deep learning:四十一(Dropout简单理解))很类似,只不过dropout作用在隐含层。此时输入到可视层的数据变为,隐含层输出为y,然后由y重构x的输出z,注意此时这里不是重构 ,而是x.
Bengio对dAE的直观解释为:1.dAE有点类似人体的感官系统,比如人眼看物体时,如果物体某一小部分被遮住了,人依然能够将其识别出来,2.多模态信息输入人体时(比如声音,图像等),少了其中某些模态的信息有时影响也不大。3.普通的autoencoder的本质是学习一个相等函数,即输入和重构后的输出相等,这种相等函数的表示有个缺点就是当测试样本和训练样本不符合同一分布,即相差较大时,效果不好,明显,dAE在这方面的处理有所进步。
当然作者也从数学上给出了一定的解释。
1. 流形学习的观点。一般情况下,高维的数据都处于一个较低维的流形曲面上,而使用dAE得到的特征就基本处于这个曲面上,如下图所示。而普通的autoencoder,即使是加入了稀疏约束,其提取出的特征也不是都在这个低维曲面上(虽然这样也能提取出原始数据的主要信息)。

2.自顶向下的生成模型观点的解释。3.信息论观点的解释。4.随机法观点的解释。这几个观点的解释数学有一部分数学公式,大家具体去仔细看他的paper。
当在训练深度网络时,且采用了无监督方法预训练权值,通常,Dropout和Denoise Autoencoder在使用时有一个小地方不同:Dropout在分层预训练权值的过程中是不参与的,只是后面的微调部分引入;而Denoise Autoencoder是在每层预训练的过程中作为输入层被引入,在进行微调时不参与。另外,一般的重构误差可以采用均方误差的形式,但是如果输入和输出的向量元素都是位变量,则一般采用交叉熵来表示两者的差异。
三、收缩自动编码器
Contractive autoencoder是autoencoder的一个变种,其实就是在autoencoder上加入了一个规则项,它简称CAE(对应中文翻译为?)。通常情况下,对权值进行惩罚后的autoencoder数学表达形式为:

这是直接对W的值进行惩罚的,而今天要讲的CAE其数学表达式同样非常简单,如下:

其中的![]() 是隐含层输出值关于权重的雅克比矩阵,而
是隐含层输出值关于权重的雅克比矩阵,而 ![]() 表示的是该雅克比矩阵的F范数的平方,即雅克比矩阵中每个元素求平方
表示的是该雅克比矩阵的F范数的平方,即雅克比矩阵中每个元素求平方

然后求和,更具体的数学表达式为:

关于雅克比矩阵的介绍可参考雅克比矩阵&行列式——单纯的矩阵和算子,关于F范数可参考我前面的博文Sparse coding中关于矩阵的范数求导中的内容。
有了loss函数的表达式,采用常见的mini-batch随机梯度下降法训练即可。
关于为什么contrative autoencoder效果这么好?paper中作者解释了好几页,好吧,我真没完全明白,希望懂的朋友能简单通俗的介绍下。下面是读完文章中的一些理解:
好的特征表示大致有2个衡量标准:1. 可以很好的重构出输入数据; 2.对输入数据一定程度下的扰动具有不变形。普通的autoencoder和sparse autoencoder主要是符合第一个标准。而deniose autoencoder和contractive autoencoder则主要体现在第二个。而作为分类任务来说,第二个标准显得更重要。
雅克比矩阵包含数据在各种方向上的信息,可以对雅克比矩阵进行奇异值分解,同时画出奇异值数目和奇异值的曲线图,大的奇异值对应着学习到的局部方向可允许的变化量,并且曲线越抖越好(这个图没看明白,所以这里的解释基本上是直接翻译原文中某些观点)。
另一个曲线图是contractive ratio图,contractive ratio定义为:原空间中2个样本直接的距离比上特征空间(指映射后的空间)中对应2个样本点之间的距离。某个点x处局部映射的contraction值是指该点处雅克比矩阵的F范数。按照作者的观点,contractive ration曲线呈上升趋势的话更好(why?),而CAE刚好符合。
总之Contractive autoencoder主要是抑制训练样本(处在低维流形曲面上)在所有方向上的扰动。
四、栈式自动编码器
单自动编码器,充其量也就是个强化补丁版PCA,只用一次好不过瘾。
于是Bengio等人在2007年的 Greedy Layer-Wise Training of Deep Networks 中,
仿照stacked RBM构成的DBN,提出Stacked AutoEncoder,为非监督学习在深度网络的应用又添了猛将。
这里就不得不提 “逐层初始化”(Layer-wise Pre-training),目的是通过逐层非监督学习的预训练,
来初始化深度网络的参数,替代传统的随机小值方法。预训练完毕后,利用训练参数,再进行监督学习训练。
Part I 原理

非监督学习网络训练方式和监督学习网络的方式是相反的。
在监督学习网络当中,各个Layer的参数W受制于输出层的误差函数,因而Layeri参数的梯度依赖于Layeri+1的梯度,形成了"一次迭代-更新全网络"反向传播。
但是在非监督学习中,各个Encoder的参数W只受制于当前层的输入,因而可以训练完Encoderi,把参数转给Layeri,利用优势参数传播到Layeri+1,再开始训练。
形成"全部迭代-更新单层"的新训练方式。这样,Layeri+1效益非常高,因为它吸收的是Layeri完全训练奉献出的精华Input。
Part II 代码与实现
主要参考 http://deeplearning.net/tutorial/SdA.html
栈式机在构造函数中,构造出各个Layer、Encoder,并且存起来。
Theano在构建栈式机中,易错点是Encoder、Layer的参数转移。
我们知道,Python的列表有深浅拷贝一说。Theano所有被shared标记的变量都是浅拷贝。
因而首先有这样的错误写法:
def __init__(self,rng,input,n_in,n_out,layerSize):
......
for i in xrange(len(layerSize)):
......
da.W=hidenlayer.W
da.bout=hidenlayer.b
然后你在外部为da做grad求梯度的时候就报错了,提示说params和cost函数不符合。
这是因为cost函数的Tensor表达式在写cost函数时就确定了,这时候da这个对象刚好构造完,因而Tensor表达式中的da.W是构造随机值。
然后我们在da构造完了之后,手贱把da.W指向的内存改变了(浅拷贝相当于引用),这样算出的grad根本就不对。
其实这样写反了,又改成了这样
def __init__(self,rng,input,n_in,n_out,layerSize):
......
for i in xrange(len(layerSize)):
......
hidenlayer.W=da.W
hidenlayer.b=da.bout
好吧,这样不会报错了,而且每训练一个Encoder,用get_value查看Layer的值确实改变了。但是,训练Encoderi+1的时候,怎么感觉没效果?
其实是真的没效果,因为Layeri的参数根本没有传播到Layeri+1去。
Theano采用Python、C双内存区设计,在C代码中训练完Encoderi时,参数并没有转到Layeri中。但是我们明明建立了浅拷贝啊?
原来updates函数在C内存区中,根本没有觉察到浅拷贝关系,因为它在Python内存区中。
正确做法是像教程这样,在da构造时建立浅拷贝关系,当编译成C代码之后,所有Python对象要在C内存区重新构造,自然就在C内存区触发了浅拷贝。
da=dA(rng,layerInput,InputSize,self.layerSize[i],hidenlayer.W,hidenlayer.b)
或者训练完Encoderi,强制把Encoderi参数注入到C内存区的Layeri里。
updateModel=function(inputs=[],outputs=[],updates=[(....)],
updateModel()
Theano的写法风格近似于函数式语言,对象、函数中全是数学模型。一旦构造完了之后,就无法显式赋值。
所以,在Python非构造函数里为对象赋值是愚蠢的,效果仅限于Python内存区。但是大部分计算都在C内存区,所以需要updates手动把值打进C内存区。
updates是沟通两区的桥梁,一旦发现Python内存区中有建立浅拷贝关系,就会把C内存区中值更新到Python内存区。(有利于Python中保存参数)
但是绝对不会自动把Python内存区值,更新到C内存区当中。(这点必须小心)
这种做法可以扩展到,监督训练完之后,参数的保存与导入。
五、变分自动编码器
1. 神秘变量与数据集
现在有一个数据集DX(dataset, 也可以叫datapoints),每个数据也称为数据点。
X是一个实际的样本集合,我们假定这个样本受某种神秘力量操控,但是我们也无从知道这些神秘力量是什么?那么我们假定这股神秘力量有n个,起名字叫power1,power2,…,powern吧,他们的大小分别是z1,z2,…,zn,称之为神秘变量表示成一个向量就是
z=⎛⎝⎜⎜⎜⎜z1z2⋮zn⎞⎠⎟⎟⎟⎟
z也起个名字叫神秘组合。
一言以蔽之:神秘变量代表了神秘力量的神秘组合关系。
用正经的话说就是:隐变量(latent variable)代表了隐因子(latent factor)的组合关系。
这里我们澄清一下隶属空间,假设数据集DX是m个点,这m个点也应该隶属于一个空间,比如一维的情况,假如每个点是一个实数,那么他的隶属空间就是实数集,所以我们这里定义一个DX每个点都属于的空间称为XS,我们在后面提到的时候,你就不再感到陌生了。
神秘变量z可以肯定他们也有一个归属空间称为ZS。
下面我们就要形式化地构造X与Z的神秘关系了,这个关系就是我们前面说的神秘力量,直观上我们已经非常清楚,假设我们的数据集就是完全由这n个神秘变量全权操控的,那么对于X中每一个点都应该有一个n个神秘变量的神秘组合zj来神秘决定。
接下来我们要将这个关系再简化一下,我们假设这n个神秘变量不是能够操控X的全部,还有一些其他的神秘力量,我们暂时不考虑,那么就可以用概率来弥补这个缺失,为什么呢?举个例子,假设我们制造了一个机器可以向一个固定的目标发射子弹,我们精确的计算好了打击的力量和角度,但由于某些难以控制的因素,比如空气的流动,地球的转动导致命中的目标无法达到精准的目的,而这些因素可能十分巨大和繁多,但是他们并不是形成DX的主因素,根据大数定理,这些所有因素产生的影响可以用高斯分布的概率密度函数来表示。它长这样:
p(x|μ,σ2)=12π√σe−12(x−μσ)2
当μ=0时,就变成了这样:
p(x|σ2)=12π√σe−x22σ2
这是一维高斯分布的公式,那么多维的呢?比较复杂,推导过程见知乎,长这样:
不管怎样,你只要记住我们现在没有能力关注全部的神秘变量,我们只关心若干个可能重要的因素,这些因素的分布状况可以有各种假设,我们回头再讨论他们的概率分布问题,我们现在假定我们对他们的具体分布情况也是一无所知,我们只是知道他们处于ZS空间内。
前面说到了一个神秘组合,如果一个数据集X对应的神秘组合完全一样,那么这个数据集就是一个单一的分类数据集,如果是多个,那么就是多分类数据集,但如果是一个连续的组合数据,那么就是一个有点分不清界限的复杂数据集,就好比,我们这个数据集是一条线段的集合,线段的长度是唯一的神秘变量,那么只要长度在一个范围内连续变化,那么这个集合里的线段你就会发现分散的很均匀,你几乎没有办法区分开他们,也没法给他们分成几类,但如果这个长度值只能选择1,3,5,那么当你观察这个数据集的时候,你会发现他们会聚在三堆儿里。如果这个线段的生成完全依靠的是计算机,那么每一堆儿都是完全重合的,但如果是人画的,就可能因为误差,没法完全重合,这没法重合的部分就是我们说的其他复杂因素,我们通常用一个高斯分布来把它代表了。好,我们已经基本清晰了,我们该给这个神秘组合一个形式化的描述了。
假设有两个变量,z∈ZS 和 x∈XS,存在一个确定性函数族f(z;θ),族中的每个函数由θ∈Θ唯一确定,f:ZS×Θ→XS,当θ固定,z是一个随机变量(概率密度函数为Pz(z))时,那么f(z;θ)就是定义在XS上的随机变量x,对应的概率密度函数可以写成g(x)。
那么我们的目标就是优化θ从而寻找到一个f,能够是随机变量x的采样和X非常的像。这里需要注意一下,x是一个变量,DX是已经现成的数据集,x不属于DX,我特意将名字起的有区分度。
这样,f就是那个神秘力量通道,他把这些神秘力量的力度,通过f变成了x变量,而这个x变量就是与数据集DX具有直接关系的随机变量。
设一个数据集为DX,那么这个数据集存在的概率为Pt(DX),则根据贝叶斯公式有:
其中,Pxz(DX|z;θ)是我们新定义的概率密度函数,我们前面知道f是将z映射成x,而x又与DX有某种直接的关系,这个直接关系可以表示成Px(DX|x),那么Pt(DX)=∫Px(DX|x)g(x)dx
这样我们就直接定义个Pxz(DX|z;θ) 来替换Px(DX|x)g(x),从而表示z与DX的关系了。
好了,其实公式(1)就是我们的神秘力量与观察到的数据集之间的神秘关系,这个关系的意思我们直白的说就是:当隐秘变量按照某种规律存在时,就非常容易产生现在我们看到的这个数据集。那么,我们要做的工作就是当我们假定有n个神秘力量时,我们能够找到一个神奇的函数f,将神秘力量的变化转化成神奇的x的变化,这个x能够轻而易举地生成数据集DX。
从上面的描述里面我们看到,f是生成转换函数,公式(1)不表示这种转换关系,而是这种关系的最大似然估计(maximum likelihood),它的意思是找到最有可能生成DX这个数据集的主导函数f。
接下来我们回到讨论Pxz(DX|z;θ)这个概率密度函数上来,我们前面说过,如果z是全部的神秘力量,那么它产生的变量x就一定固定的,即当z取值固定时,x取值固定,但是现实中还有很多其他的因素,因而x的取值还与他们有关,他们的影响力,最终反映成了高斯函数,所以我们大胆假定Pxz是一个高斯分布的概率密度函数,即Pxz(DX|z;θ)=N(DX|f(x;θ),σ2∗I)
注意z的分布我们依然是未知的。
假定我们知道z现在取某一个或几个特定值,那么我们就可以通过Gradient Descent来找到一个θ尽量满足z能够以极高的概率生成我们希望的数据集DX。再一推广,就变成了,z取值某一范围,但去几个特定值或某一取值范围是就面临z各种取值的概率问题,我们回头再讨论这个棘手的问题,你现在只要知道冥冥之中,我们似乎可以通过学习参数θ寻找最优解就行了。
OK,我们还要说一个关键问题,就是我们确信f是存在的,我们认为变量与神秘变量之间的关系一定可以用一个函数来表示。
2. 变分自编码器(VAE)
本节,我们探讨如何最大化公式(1)。首先,我们要讨论怎样确定神秘变量z,即z应该有几个维度,每个维度的作用域是什么?更为较真的,我们可能甚至要追究每一维度都代表什么?他们之间是不是独立的?每个维度的概率分布是什么样的?
如果我们沿着这个思路进行下去,就会陷入泥潭,我们可以巧妙地避开这些问题,关键就在于让他们继续保持“神秘”!
我们不关心每一个维度代表什么含义,我们只假定存在这么一群相互独立的变量,维度我们也回到之前的讨论,我们虽然不知道有多少,我们可以假定有n个主要因素,n可以定的大一点,比如假设有4个主因素,而我们假定有10个,那么最后训练出来,可能有6个长期是0。最后的问题需要详细讨论一下,比较复杂,就是z的概率分布和取值问题。
既然z是什么都不知道,我们是不是可以寻找一组新的神秘变量w,让这个w服从标准正态分布N(0,I)。I是单位矩阵,然后这个w可以通过n个复杂函数,转换成z呢?有了神经网络这些也是可行的,假设这些复杂函数分别是h1,h2,…,hn,那么有z1=h1(w1),…,zn=hn(wn)。而z的具体分布是什么,取值范围是多少我们也不用关心了,反正由一个神经网络去算。回想一下P(DX|z;θ)=N(DX|f(z;θ),σ2×I),我们可以想象,如果f(z;θ)是一个多层神经网络,那么前几层就用来将标准正态分布的w变成真正的隐变量z,后面几层才是将z映射成x,但由于w和z是一一对应关系,所以w某种意义上说也是一股神秘力量。就演化成w和x的关系了,既然w也是神秘变量,我们就还是叫回z,把那个之前我们认为的神秘变量z忘掉吧。
好,更加波澜壮阔的历程要开始了,请坐好。
我们现在已经有了
Pz(z)=N(0,I),
Pxz(DX|z;θ)=N(DX|f(x;θ),σ2∗I),
Pt(DX)=∫Pxz(DX|z;θ)Pz(z)dz,
我们现在就可以专心攻击f了,由于f是一个神经网络,我们就可以梯度下降了。但是另一个关键点在于我们怎么知道这个f生成的样本,和DX更加像呢?如果这个问题解决不了,我们根本都不知道我们的目标函数是什么。
3. 设定目标函数
我们先来定义个函数 Q(z|DX),数据集DX的发生,z的概率密度函数,即如果DX发生,Q(z|DX)就是z的概率密度函数,比如一个数字图像0,z隐式代表0的概率就很大,而那些代表1的概率就很小。如果我们有办法搞到这个Q的函数表示,我们就可以直接使用DX算出z的最佳值了。为什么会引入Q呢?其实道理很简单,如果DX是x这个变量直接生成的,要想找回x的模型,就要引入一个概率密度函数T(x|DX),亦即针对DX,我们要找到一个x的最佳概率密度函数。
现在的问题就变成了,我们可以根据DX计算出Q(z|DX)来让他尽量与理想的Pz(z|DX)尽量的趋同,这就要引入更加高深的功夫了——相对熵,也叫KL散度(Kullback-Leibler divergence,用 D表示)。
离散概率分布的KL公式
KL(p∥q)=∑p(x)logp(x)q(x)
连续概率分布的KL公式
KL(p∥q)=∫p(x)logp(x)q(x)dx
Pz(z|DX)和Q(z|DX)的KL散度为
D[Q(z|DX)∥Pz(z|DX)]=∫Q(z|DX)[logQ(z|DX)–logPz(z|DX)]
也可写成
D[Q(z|DX)∥Pz(z|DX)]=Ez∼Q[logQ(z|DX)–logPz(z|DX)]
通过贝叶斯公式
Pz(z|DX)=P(DX|z)P(z)P(DX)
这里不再给P起名,其实Pz(z)直接写成P(z)也是没有任何问题的,前面只是为了区分概念,括号中的内容已经足以表意。
D[Q(z|DX)∥Pz(z|DX)]=Ez∼Q[logQ(z|DX)–logP(DX|z)–logP(z)]+logP(DX)
因为logP(DX)与z变量无关,直接就可以提出来了,进而得到闪闪发光的公式(2):
公式(2)是VAE的核心公式,我们接下来分析一个这个公式。
公式的左边有我们的优化目标P(DX),同时携带了一个误差项,这个误差项反映了给定DX的情况下的真实分布Q与理想分布P的相对熵,当Q完全符合理想分布时,这个误差项就为0,而等式右边就是我们可以使用梯度下降进行优化的,这里面的Q(z|DX)特别像一个DX->z的编码器,P(DX|z)特别像z->DX的解码器,这就是VAE架构也被称为自编码器的原因。
由于DX早已不再有分歧,我们在这里把所有的DX都换成了X。
我们现在有公式(2)的拆分:
– 左侧第一项:logP(X)
– 左侧第二项:D(Q(z|X∥P(z|X))
– 右边第一项:Ez∼Q[logP(X|z)]
– 右边第二项:D[Q(z|X)∥P(z)]
还有下面这些:
– P(z)=N(0,I),
– P(X|z)=N(X|f(z),σ2∗I),
– Q(z|X)=N(z|μ(X),Σ(X))
我们再明确一下每个概率的含义:
– P(X)——当前这个数据集发生的概率,但是他的概率分布我们是不知道,比如,X的空间是一个一维有限空间,比如只能取值0-9的整数,而我们的 X = { 0, 1, 2, 3, 4 },那么当概率分布是均匀的时候,P(X)就是0.5,但是如果不是这个分布,就不好说是什么了,没准是0.1, 0.01,都有可能。P(X)是一个函数,就好像是一个人,当你问他X=某个值的时候,他能告诉发生的概率。
– P(z) —— 这个z是我们后来引入的那个w,还记得吗?他们都已经归顺了正态分布,如果z是一维的,那他就是标准正态分布N(0, I)。
– P(X|z) —— 这个函数的含义是如果z给定一个取值,那么就知道X取某个值的概率,还是举个例子,z是一个神奇的变量,可以控制在计算机屏幕上出现整个屏幕的红色并且控制其灰度,z服从N(0,1)分布,当z=0时代表纯正的红色,z越偏离0,屏幕的红色就越深,那么P(X|z)就表示z等于某个值时X=另一值的概率,由于计算机是精确控制的,没有额外的随机因素,所以如果z=0能够导致X取一个固定色值0xFF0000,那么P(X=0xFF0000|z=0)=1,P(x!=0xFF0000|z=0) = 0,但如果现实世界比较复杂附加其他的随机因素,那么就可能在z确定出来的X基础值之上做随机了。这就是我们之前讨论的,大数定理,P(X|z)=N(X|f(x),σ2∗I)。f(z)就是X与z直接关系的写照。
– P(z|X) —— 当X发生时,z的概率是多少呢?回到刚才计算机屏幕的例子,就非常简单了P(z=0|X=0xFF0000) = 1, P(z!=0|X=0xFF0000) = 0,但是由于概率的引入,X|z可以简化成高斯关系,相反,也可以简化高斯关系。这个解释对下面的Q同样适用。
– Q(z) —— 对于Q的分析和P的分析是一样的,只不过Q和P的不同时,我们假定P是那个理想中的分布,是真正决定X的最终构成的背后真实力量,而Q是我们的亲儿子,试着弄出来的赝品,并且希望在现实世界通过神经网络,让这个赝品能够尝试控制产生X。当这个Q真的行为和我们理想中的P一模一样的时候,Q就是上等的赝品了,甚至可以打出如假包换的招牌。我们的P已经简化成N(0,I),就意味着Q只能向N(0, I)靠拢。
– Q(z|X) —— 根据现实中X和Q的关系推导出的概率函数, 当X发生时,对应的z取值的概率分布情况。
– Q(X|z) —— 现实中z发生时,取值X的概率。
我们的目标是优化P(X),但是我们不知道他的分布,所以根本没法优化,这就是我们没有任何先验知识。所以有了公式(2),左边第二项是P(z|X)和Q(z|X)的相对熵,意味着X发生时现实的分布应该与我们理想的分布趋同才对,所以整个左边都是我们的优化目标,只要左边越大就越好,那么右边的目标就是越大越好。
右边第一项:Ez∼Q[logP(X|z)]就是针对面对真实的z的分布情况(依赖Q(z|X),由X->z的映射关系决定),算出来的X的分布,类似于根据z重建X的过程。
右边第二项:D[Q(z|X)∥P(z)] 就是让根据X重建的z与真实的z尽量趋近,由于P(z)是明确的N(0, I),而Q(z|X)是也是正态分布,其实就是要让Q(z|X)趋近与标准正态分布。
现在我们对这个公式的理解更加深入了。接下来,我们要进行实现的工作。
4. 实现
针对右边两项分别实现
第二项是Q(z|X)与N(0, I)的相对熵,X->z构成了编码器部分。
Q(z|x)是正态分布,两个正态分布的KL计算公式如下(太复杂了,我也推不出来,感兴趣的看[1]):
KL(N(μ,Σ)∥N(0,I))=12[−log[det(Σ)]−d+tr(Σ)+μTμ]
det是行列式,tr是算矩阵的秩,d是I的秩即d=tr(I)。
变成具体的神经网络和矩阵运算,还需要进一步变化该式:
KL(N(μ,Σ)∥N(0,I))=12∑i[−log(Σi)+Σi+μ2i–1]
OK,这个KL我们也会计算了,还有一个事情就是编码器网络,μ(X)和Σ(X)都使用神经网络来编码就可以了。
第一项是Ez∼Q[logP(X|z)]代表依赖z重建出来的数据与X尽量地相同,z->X重建X构成了解码器部分,整个重建的关键就是f函数,对我们来说就是建立一个解码器神经网络。
到此,整个实现的细节就全都展现在下面这张图里了
由于这个网络传递结构的一个环节是随机采样,导致无法反向传播,所以聪明的前辈又将这个结构优化成了这样:
这样就可以对整个网络进行反向传播训练了。
具体的实现代码,我实现在了这里:
https://github.com/vaxin/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/variational_autoencoder.py
里面的每一步,都有配合本文章的对照解释。
5. 延伸思考
之所以关注VAE,是从文献[4]引发的,由于视觉早期的概念形成对于之后的视觉认知起了十分关键的作用,我们有理由相信,在神经网络训练时,利用这种递进关系,先构建具有基础认知能力的神经网络,再做高级认知任务时会有极大的效果提升。但通过前面神秘变量的分析,我们发现,为了充分利用高斯分布,我们将w替换成了z,也就是说真正的隐变量隐藏在f的神经网络里面,而现在的z反而容易变成说不清楚的东西,这一不利于后续的时候,二来我们需要思考,是否应该还原真实的z,从而在层次化递进上有更大的发挥空间。















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









