







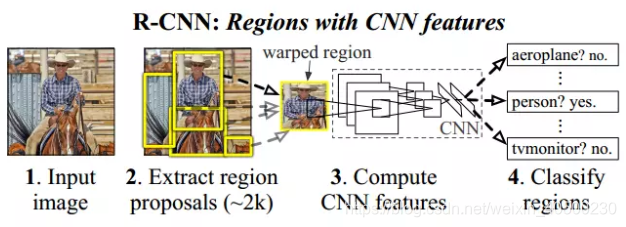
该文是目标检测领域的里程碑论文,是fast-rcnn、faster-rcnn等系列的基础。它首次用深度学习CNN的方式进行目标检测的尝试。取得了性能、准确度均大幅高于传统提取特征方式的结果。
一.算法模块
1.Region Proposals区域推荐
在目标检测时,为了定位到目标的具体位置,通常会把图像分成许多子块,然后把子块作为输入,送到目标识别的模型中。分子块的最直接方法叫滑动窗口法(Sliding Window Approach)。滑动窗口的方法就是按照子块的大小在整幅图像上穷举所有子图像块。
而论文中使用的Selective Search方法是则是基于区域推荐的,目的是为了改善传统提取特征方法中机从左到右、从上到下穷举式带来的低效。R-CNN不关心特定的区域推荐算法,选择Selective Search只是为了与需要对比的前任论文保持一致。R-CNN一张图片选出约2000个候选区域。
2.CNN提取特征
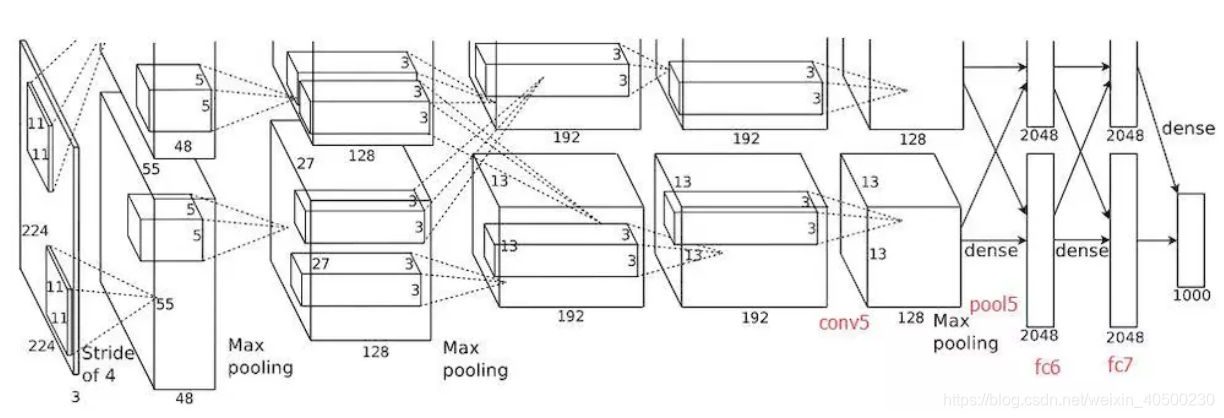

RCNN使用的CNN网络是AlexNet,该网络的具体结构见上图。AlexNet原本是为做图像分类任务,RCNN是为做目标检测任务,故替换掉了AlexNet的最后一层的全连接层(4096*1000)。故RCNN的结构实际是5个卷积层、2个全连接层。输入是Region Proposal计算的推荐区域的图像,由于该CNN网络输入限定为2000*227*227*3(RGB)的输入,故在RCNN中将Region Proposal的推荐区域仿射变形到227*227的格式上,网络输出是2000*4096*1的特征向量。
3.SVM判别类别
使用训练过的对应类别的SVM给特征向量中的每个类进行打分,每个类别对应一个二分类SVM,CNN输出2000*4096,SVM输出2000*N(N是数据集中目标的类别),然后为了减少重复的bounding box,使用了非极大值抑制法:如果一个区域的得分与大于它得分的区域有很大程度的交叉(intersection-overunion(IoU))根据score进行排序,把score最大的bounding box作为选定的框,计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box。然后重复上面的过程,直至候选bounding box为空,然后再将score小于一定阈值的选定框删除得到一类的结果。
4.Bounding Box Regression选定框回归

如上图所示,通过selective search得到的region proposal可能与ground truth相差较大,尽管这个region proposal可能有很高的分类评分,但对于检测来说,它依然是不合格的。
为了进一步提高定位的准确度,作者在对各个region proposal打分后,利用回归的方法重新预测了一个新的矩形框,借此来进一步修正bounding box的大小和位置。
二.训练过程
由于在实际检测中,训练的样本肯定是缺少的。作者给出pre-training和fine-tuning结合的方法:
1、先预训练AlexNet使用imagenet数据集,按分类任务pre-training,得到模型。
2、fine-tune。将模型的最后一层修改类别数。使用pascal voc 数据集fine-tune。
输入为warped region proposal,输出为21维类向量。(与pre-training网络的唯一改变是由输出1000类改为输出21类)。包括20类目标和背景。把与ground truth的IOU>0.5的region proposal作为正例,其余为负例,即背景。每个batch里包含32个正例,96个负例共128个。学习率为0.001,是pre-training的1/10,为了不破坏与训练的结果。
3、训练SVM
训练某类别的SVM,与该类目标的groud-truth的IoU>0.3的region proposal的特征向量作为正例,其余作为负例。为了减小内存使用,采用standard hard negative mining method。
4、训练bounding box regression
受DPM (Object detection with discriminatively trained part based models)的灵感,训练一个线性回归模型,给定pool5层的特征预测一个新的检测窗口。
三.小结:
R-CNN将CNN运用到了目标检测任务中,使得mAP有了很大的提高,在VOC 2012上达到53.3%。存在的问题是速度慢一张图片需要几十秒,训练过程繁琐,分四个步骤,不够优雅。
参考文章:
https://www.cnblogs.com/louyihang-loves-baiyan/p/4839869.html















 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









