







最近敲代码总感觉有点迷,很多东西直接使用Tensorflow或者Pytorch封装好的模块总感觉不得劲儿,算了还是恶补一下李老师的课吧,把该弄懂的东西都搞清楚。
正则化:为了减小噪声数据带来的预测偏差,λ越大,曲线越趋向于平滑(水平)。

Bias and Variance:没瞄准和打不准
偏差过大:redesign model
方差大:collect data(数据变换)、regularization

Cross validation:保证public testing set 与 private Testing set一致,因为你的test也只是样本,而不是真实的数据分布。
Gradient Decent:梯度是函数值增加最快的方向,所以要取反,且梯度越大,斜率越大。
Adaptive learning rate: 各个参数应该不同,且应该随着t的增大而缩小
Adagrad:

SGD:针对loss做文章,随机取一个样本进行loss计算

Momentum:


Adam:

Feature Scaling:求微分的时候会偏向于输入大的部分(x),所以需要进行归一化

Maximum Likelihood:求导可得

Sigmod Function:

Logistics Function:公式推导




判别模型和生成模型:判别模型在大数据量的情况下较优

链式法则:

Backpropagation:

梯度消失:层数过多,后层根据前层已经下降(sigmod )到local minimal

Early Stopping:

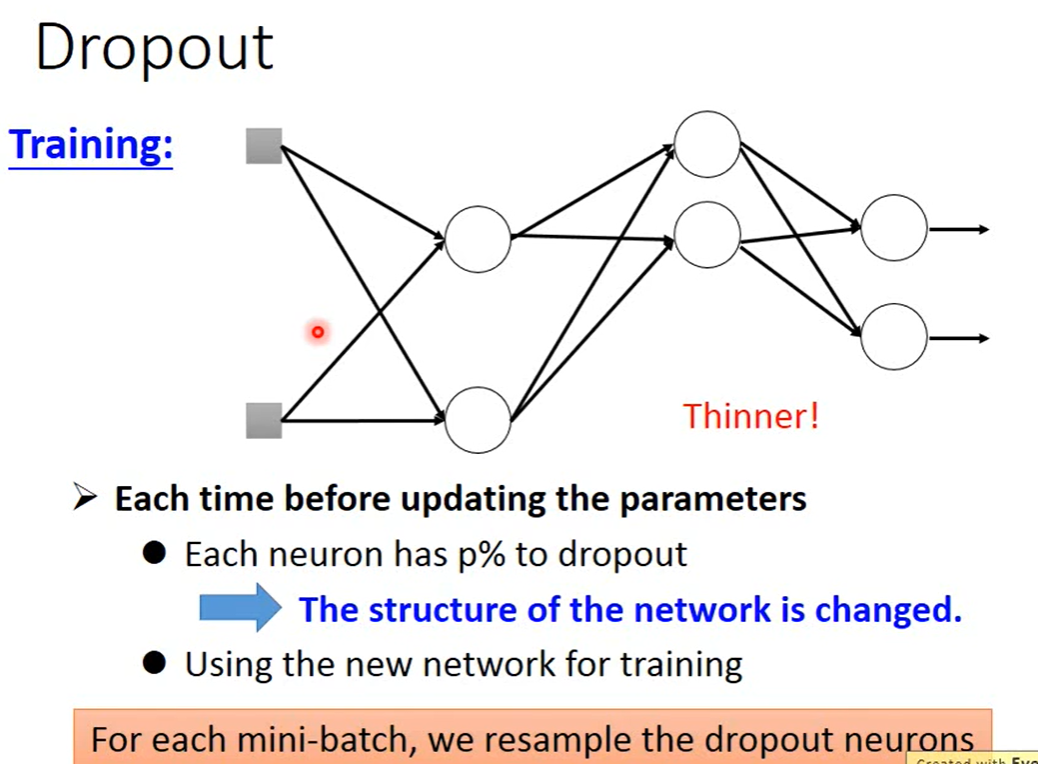
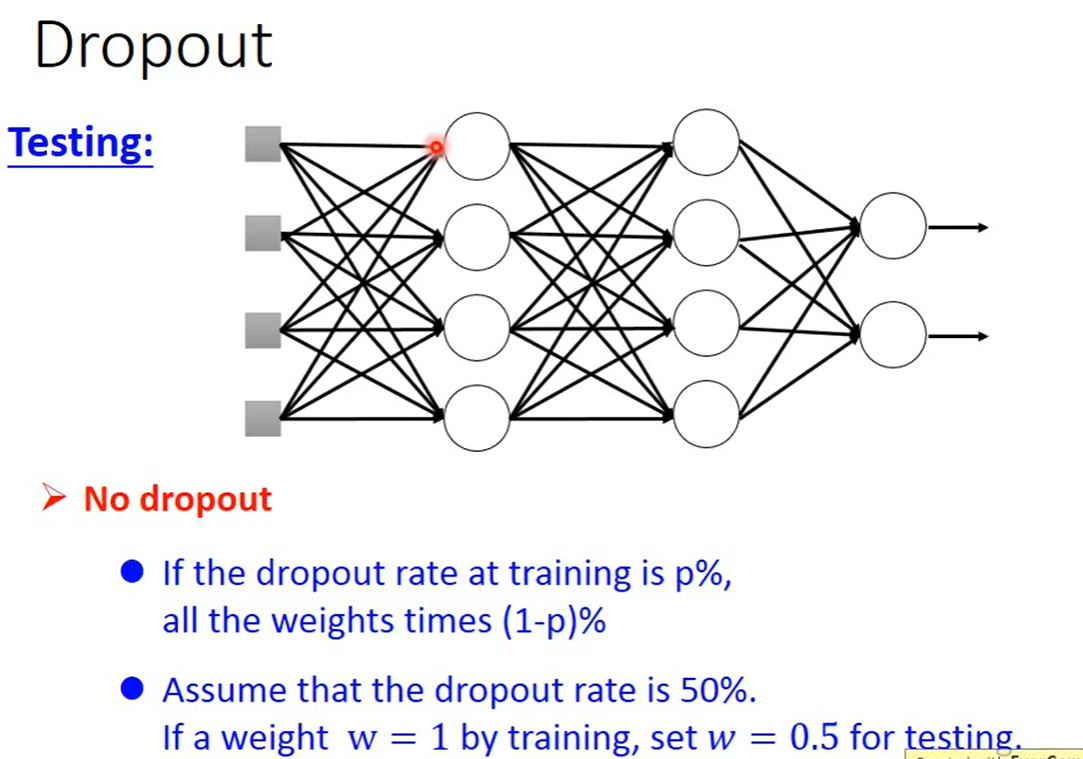
Dropout:
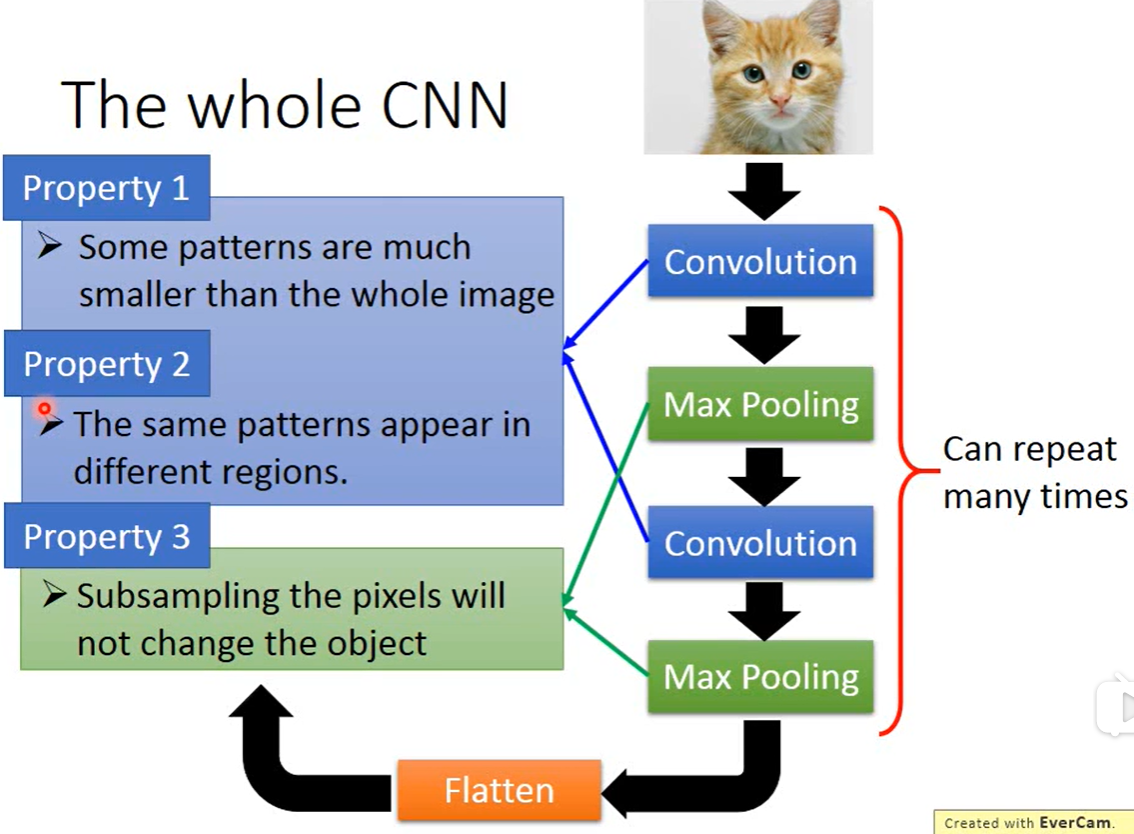
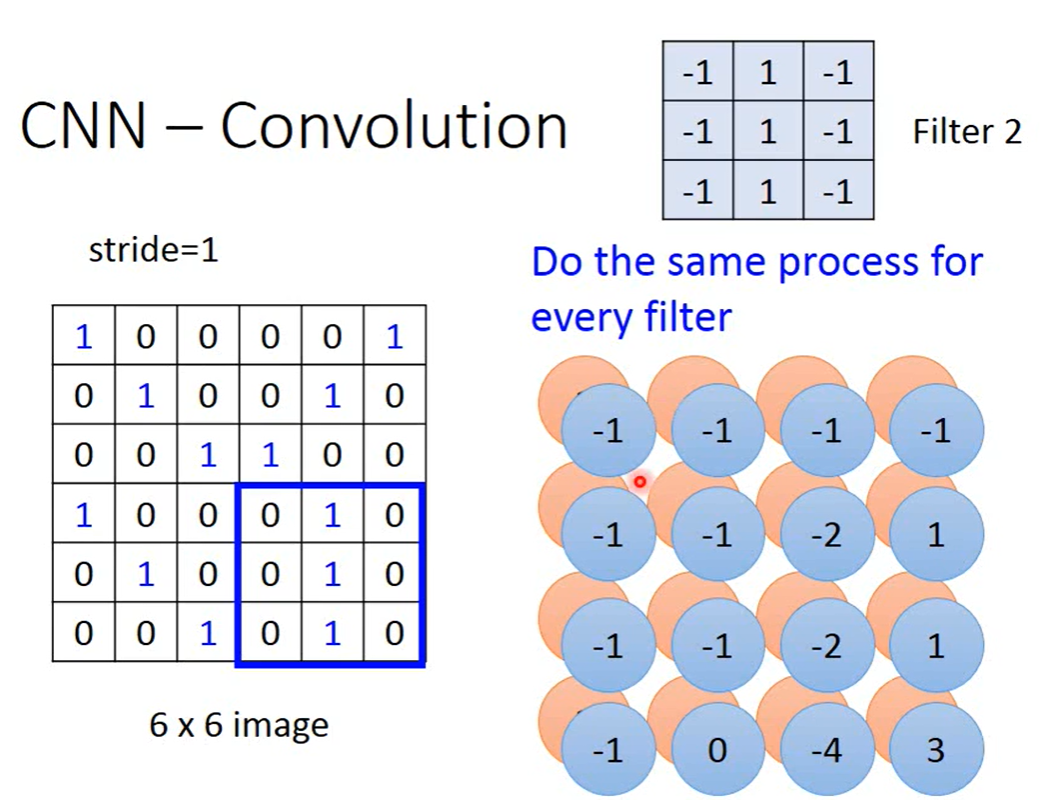
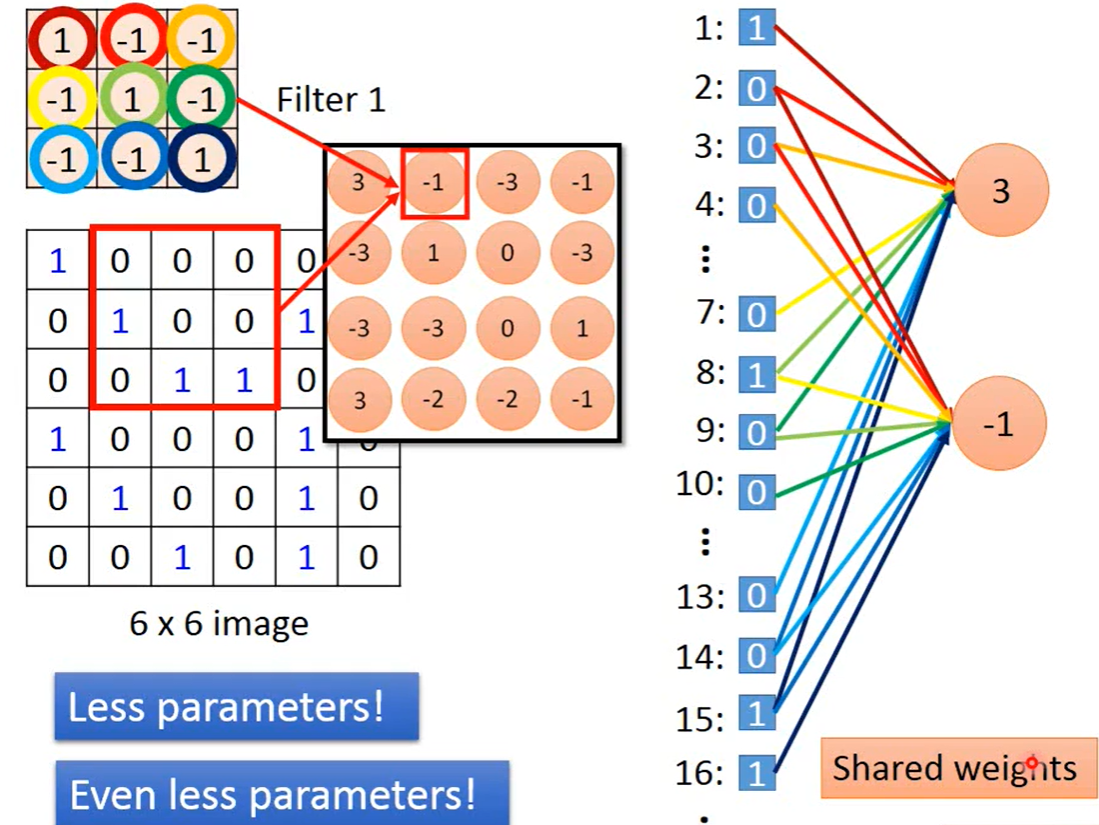
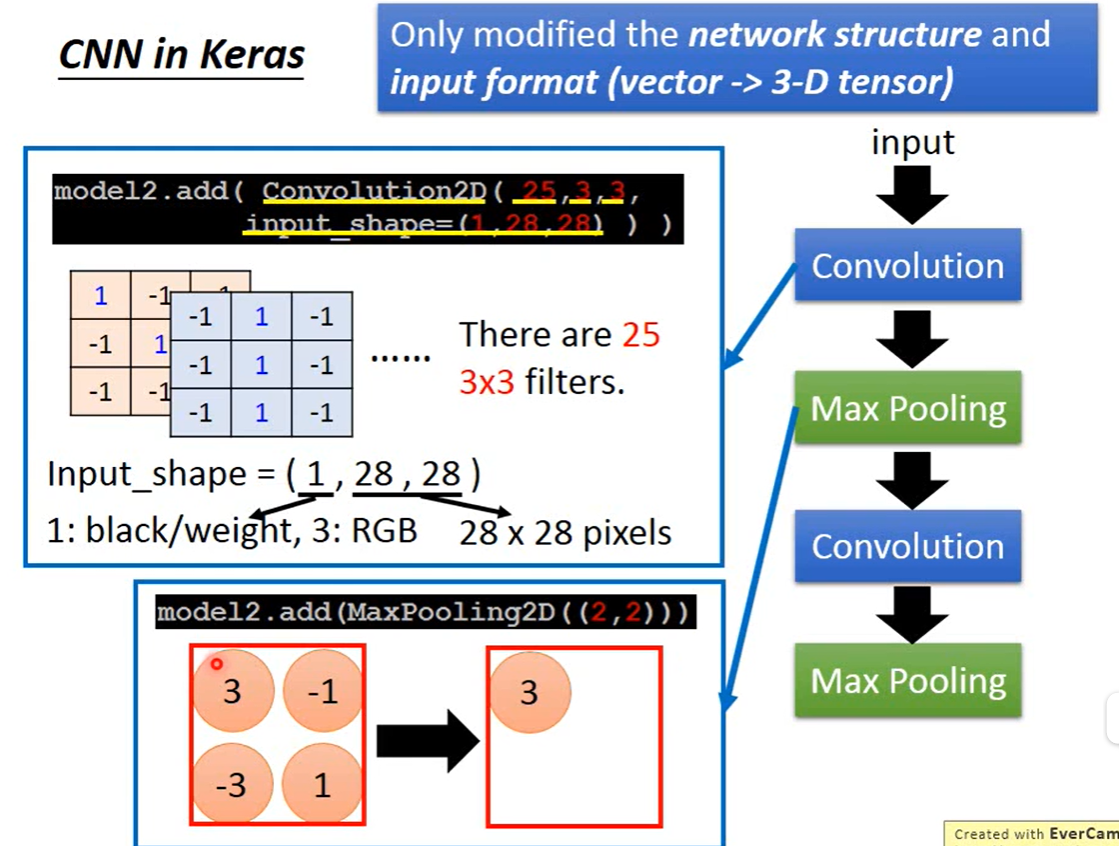
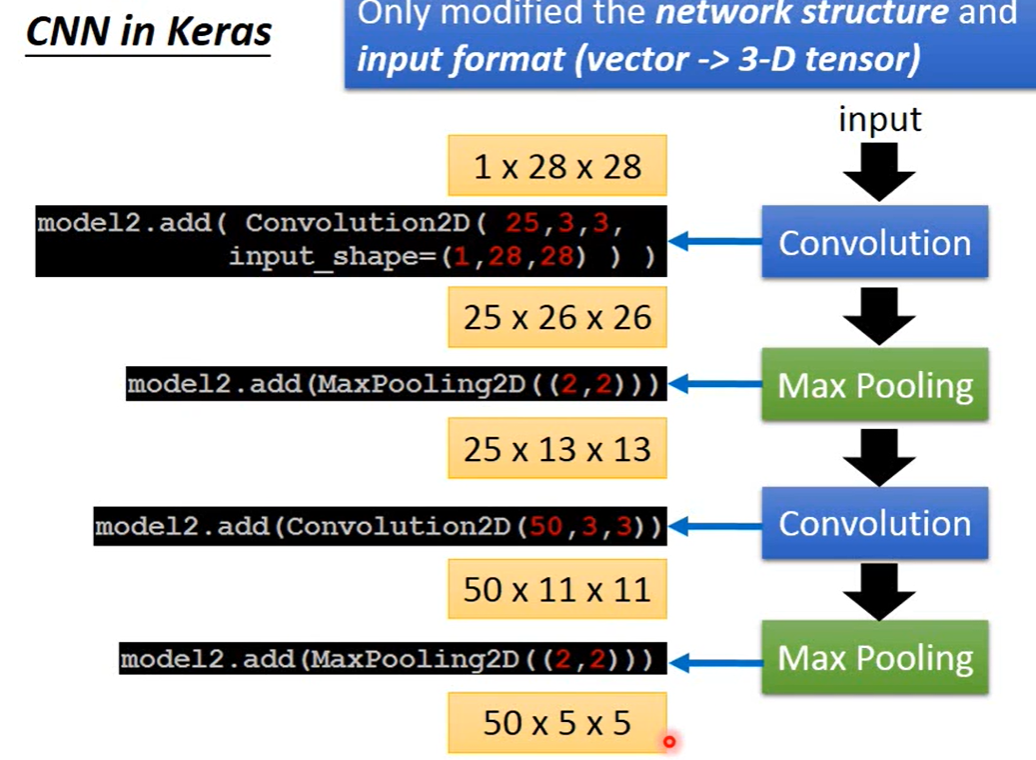
CNN:单个Filter可以实现Property2,单个Filter中相同的feature,share同一组Weight,可以看图三理解一下。多个Conv_maxpool输出还是out_filter的数目,不是指数增长。

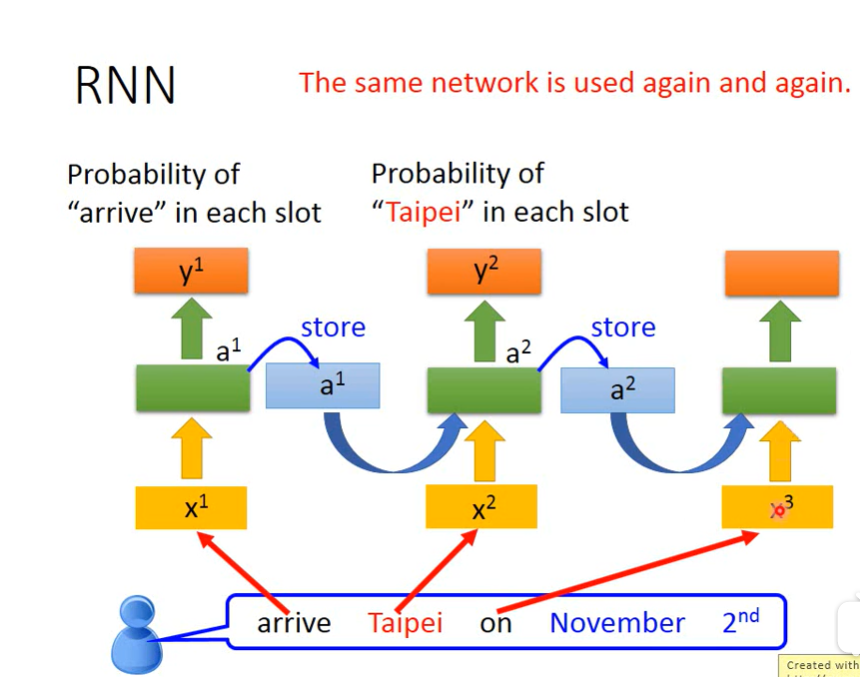
RNN:当然memory中存入output也可以;LSTM中的Linear weight是训练出来的scalar,LSTM对照于DNN仅仅是将一个Neuro换成一个LSTM cell,4倍于RNN的参数。GRU相比于LSTM少了一个门,但效果类似且不容易Overfitting;LSTM可以解决Gradient vanishing的问题。
simple rnn:

lstm:



lstm简单形态,C就是C,H就是H,不会影响输入。

lstm最终形态,每层的C和H都会于下一个X一起影响输入。

Word Embedding:类似于映射到更高的dimention追寻词根(class),需要共享参数。


Encoder and Decoder: 如果train的时候输入下一个的输入是reference,会存在bias,test时候会无法预期,可以采用scheduled sampling decide。



**Attention-based-model:**a是计算得到的z和h的相似度,具体相似度的计算方法可以自己选择。其实C是一个信息抽取的集合。




















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











