









 本文详述了智能客服领域语料准备的重要性,包括数据来源、清洗与预处理流程,以及知识库构建、问答系统设计与数据运营的闭环优化策略。
本文详述了智能客服领域语料准备的重要性,包括数据来源、清洗与预处理流程,以及知识库构建、问答系统设计与数据运营的闭环优化策略。
语料准备:
智能客服语料在实际生产,语料一般是需要自己爬取,或者垂直领域的语料由客户提供的,这些数据都是需要清洗、预处理的。
智能客服中一般工作中的语料准备:
1)智能客服领域服务的客户主要涉及领域一般是垂直领域,包括银行、证券、保险、汽车和零售等;
2)语料主要是客户客服部门的日志及电话录音;比如对于银行行业的信用卡业务中掌上生活的智能客服,里面的语料积累就是通过人工客服得到的;再比如拨打10086查询话费时的电话录音,银行电话办理信用卡的录音等,都可以转为文本作为语料问答对;
3)数据清洗步骤:
a) 先将客户的log整理成符合数据分析平台格式的文件 --- analysis_file ;
b) 将analysis_file上传到数据分析平台(一般进行统计、聚类等分析及可视化、按类别划分等), 人工分析结果, 编写标准问答对, 再请客户确认标准问 ;
c) 然后对标准问进行语料扩写,形成相似问列表, 并将相似问结果发给客户确认 ;
b-c 在知识库构建过程中是不断重复迭代进行的。
一般对话是搜索式的,生成式的一般应用于闲聊、寒暄等。现行业大多数用的搜索式的(搜索+深度学习)。小艾实现主要是rule_based的,小度(搜索+深度学习的),其架构模型肯定是业界领先的。
对于检索匹配容易出现的问题:比如有这三种情况:1)结婚10年了;2)我去年结的婚;3)接了20年婚了。
这里需要主要1.看语块的组成形式 2.给语块构建规则 (例如:结+时间段+婚)
NLP中文数据语料链接
智能客服(对话)系统主要分为三部分:
1、知识库的构建
2、问答系统的构建
3、上线后的数据运营
具体如下图所示:
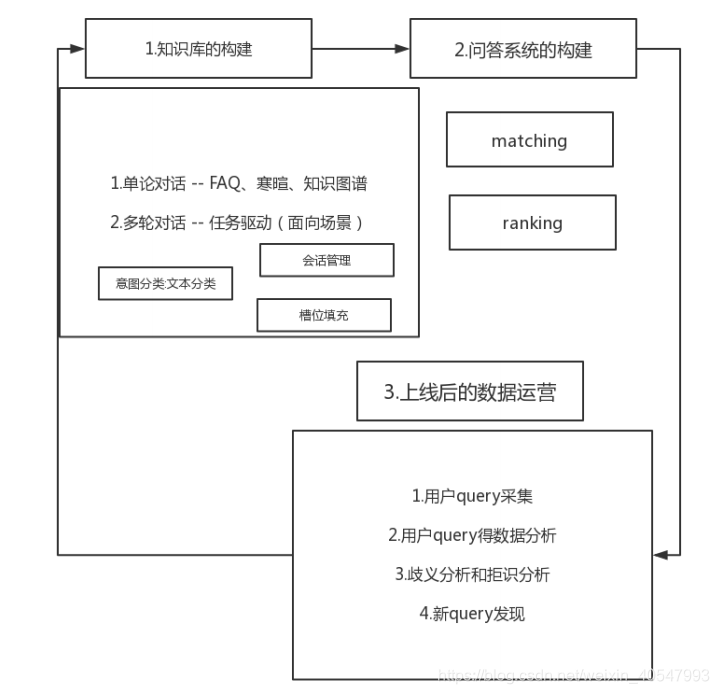
将这三部分连接形成一个闭环,不断进行迭代优化。
1、知识库的构建:分为单轮对话和多轮对话(目前主要是任务驱动的)
单轮对话:
FAQ:FAQ知识库。比如question:我买股票的手续费是多少? answer:有印花税、购入成本等等
寒暄:例如你好啊! 今天天气怎么样?
知识图谱:可能特殊一点,是实体属性链接关系。
多轮对话:比如你打电话给美团点评订餐,
A:我今天要预定位置
B:你们多少人?
A:我们一共三个人
B:现在客满,没有位置了
A:那需要等多久
B:您确定要等吗?
A:OK,大概等半个小时
B:行,那好,我帮您下单了。
当然这里主要涉及用户输入问题的意图识别,怎么进行意图分类的问题(可以理解为文本分类)。当用户输入一个问题,需要判断是寒暄还是知识图谱模块,或者FAQ模块,如果都不在这些模块中,则推荐几个相似的问题。
比如,A:我想买保险 B:您是想买财产险还是车险还是健康险呢? A:我想买健康险。
实际上这也是一种单轮对话。
在单轮对话种一般都是question与question进行匹配的 ,进而得到最佳question对应的answer,这种qq匹配泛化能力较好。因为如果采用QA匹配,难度较大,准确度低,难以应用;另一个就是answer随着时间、政策是不断变化的。
多轮对话是应用场景驱动的:主要涉及会话管理、槽位填充。
2、问答系统构建:主要分为matching,ranking
matching:主要是做一个召回,进行粗排序。
ranking:对matching找回的数据进行精排序,得到top1,并返回结果。
3、上线后的数据运营
a) 用户query的采集,主要是通过日志采集;
b) 用户query的数据分析;
c) 歧义分析和拒识分析;
d) 新query的发现。
e) ……
将这三部分连接形成一个闭环,不断进行迭代优化。


















 2815
2815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











