







最近终于实现了darknet(yolov4)与repulsion的结合。但是结果奇差无比。仔细阅读论文,发现repulsion loss基本上是为了提升数据集的指标而设计的。实际中很难应用,并且局限于两阶段检测器(个人猜想。)
题目:Repulsion Loss: Detecting Pedestrians in a Crowd
原文章地址:Repulsion Loss: Detecting Pedestrians in a Crowd
1.引言
我们来分析一下论文。
作者设计此函数的启发是由于在现实世界中行人经常聚在一起并相互遮挡,因此在人群中检测单个行人仍然是一个具有挑战性的问题。 在本文中,我们首先通过实验探索最先进的行人检测器如何受到人群遮挡的伤害,从而提供有关人群遮挡问题的见解。 然后,我们提出了一种专门针对人群场景设计的新颖的边界框回归损失,称为排斥力。 这种损失是由两个动机驱动的:目标的吸引和周围其他物体的排斥。 排斥词可防止提案转移到周围的物体上,从而导致人群拥挤的本地化。 经过排斥损失训练的我们的探测器性能优于最新方法,在遮挡情况方面有显着改善。
在标准边界框回归损失中,当预测框移动到周围对象时,没有其他惩罚。 这种观察使我们想知道,如果我们想在人群中检测目标,是否可以考虑其周围物体的位置?
whether the locations of its surrounding objects could be taken into account if we want to detect a target in a crowd?
2.Repulsion loss
Reulsion loss完整公式如下:
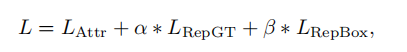
分为三部分。
第一部分为预测框与真实目标框所产生的损失值(attraction term);第二部分为预测框与相邻真实目标框所产生的损失值(repulsion term(RepGT));第三部分为预测框与相邻不是预测同一真实目标的预测框所产生的损失值(repulsion Box(RepBox))。通过两个相关系数alpha和beta来平衡两部分repulsion损失值。
(1)Attraction term:

目的使预测框与真实目标框更加接近,沿用 Smooth_L1 构造吸引项。给定一个 proposal P ∈ P_+(所有的正样本),为每个proposal匹配一个与之有最大IoU值的真实目标框:
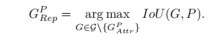
这个Grep对应YOLOv4中的cell中三个锚框中具有最大IoU的那个anchor box。这一部分不需要加入YOLOv4
(2)Repulsion Term(RepGT):

目的使预测框远离与之相邻的真实目标框。(没有实际意义,因为密集人群数据集中的人存在大量的遮挡,所以真实目标框会相邻,但这是一种假定预测框一定会与真实目标框相邻的情况,即只针对论文中的数据集有效)
(3)Repulsion Term(RepBox):
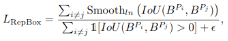
3.我的分析
损失函数的第三部分的目的是,使预测框远离相邻不是预测同一真实目标的预测框。很绕口。简单理解,就是让A目标的预测框远离B目标的预测框。因为当两个GT(ground truth)框离得很近的时候,必定会在此位置产生不同的预测框,如果没有这部分,通常都会将两个人检测成一个人。但是现在基本都是通过NMS来保留一个或几个得分较高的预测框。
这意味着:这一步是必须已经得出确定的预测框或者建议框才能进行。
官方选用的是fast-rcnn,两阶段检测器,先生成一堆建议框,然后再用repulsion loss训练。如果用fast-rcnn,我觉得是可以实现的。因为两阶段检测器先生成一堆建议框,repulsion loss直接插在RPN网络后,对RPN网络生成的建议框计算loss,这样应该是可以的。对每一个目标都会生成一堆框。对这些框去训练损失函数。
正如原论文中所展示的这种:

先得生成一堆框,然后再计算边界框损失。
但是呢,在YOLO中,这种一阶段检测器是直接得到了边界框和概率值的,结果都有了,网络已经结束了,怎么计算repulsion loss呢。所以我的改进必然是成功不了的。
如果我没改进,没有得出结果。也不会理解这么透彻了。至少知道这样是不对了。😃
而且论文中也没有给出伪代码,或者算法流程图之类的。也不知道是不是在RPN之后进行边界框损失计算。不过我觉得应该是这样。
附上我的结果:
github地址:https://github.com/SpongeBab/darknet
给我标个星吧~
1000张图片,3000个iteration。

可以看到对同一个位置保留了两个预测框,如果是对密集人群数据集,自然指标会提高。
对于一阶段检测器来说,直接得到了检测结果,除非再这一步后面再加一个NMS处理步骤。也许可行?不知道。
更多结果:


更新,评论区大佬@unknown_ocean说的很对,个人感觉,因为yolo预测物体是每个格子独立的。是一种把图像划分成了很多块,所以不需要像论文中考虑那么复杂。按照论文的思路,就是增加格子数量,使格子更密集,这样自然能够对拥挤在一起的物体预测更准确,应该是这样的。
增加格子数量:
1)增加输入图像的尺寸,224尺寸32倍下采样,最后一层7x7的格子,448/32 = 14, 最后一层14x14的格子数量。输入尺寸增大一倍,格子数量增大4倍!
2)还有就是增加FPN层数。待更。














 1394
1394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









