







目录
2. BN方法的作用,与数据预处理的区别,有没有可训练的参数?
4. Dropout的作用和原理,在训练和测试时是如何运行?
1. 说说你的项目,数据构成,网络架构,建模过程遇到哪些问题及如何解决的
2. 医学影像多人标注出现不一致情况怎么解决?如何用算法的方式减少误差
2. tensorflow和pytorch哪个是动态图哪个是静态图,实现原理上有什么区别
Part1:ML和DL基础
1. 生成模型和判别模型都有哪些?区别是什么?
- 生成式模型:朴素贝叶斯、混合高斯、隐马尔可夫、贝叶斯网络、Sigmoid Belief Networks、马尔科夫随机场、深度信念网络
- 判别式模型:K近邻、线性回归、感知机、逻辑斯蒂回归、最大熵模型、SVM、神经网络、高斯过程、条件随机场、boosting方法、CART(classification and regression tree)
- 区别:
- 公式上看,生成模型由训练数据学习联合概率分布P(x,y),然后求得后验概率分布P(y|x)。预测时应用最大后验概率法(MAP)得到预测类别y。判别模型直接学习得到P(y|x),利用MAP得到y。或者直接学得一个映射函数y=f(x)。
- 直观上看,生成模型,源头导向,尝试去找到底这个数据是怎么产生的,然后再对一个信号进行分类。基于你学习到的生成假设,判断哪个类别最有可能产生这个信号,这个样本就属于那个类别。判别模型,结果导向,并不关心样本数据是怎么生成的,它只关心样本之间的差别,然后用差别来简单对给定的一个样本进行分类。
2. BN方法的作用,与数据预处理的区别,有没有可训练的参数?
💡 独立同分布假设:训练数据和测试数据的分布相同是训练的模型能够在测试集上获得好效果的保障。而BN就是使得在训练过程中每一层的输入都保持相同的分布。再者,随着网络的加深,训练变得更加困难,收敛越来越慢,而BN、ReLU、残差结构本质上都是为了解决这个问题的
- 简而言之,对每一层网络的输出规范为均值和方差一致的方法,使其服从标准的正态分布,这样后一层网络的输入也是一个标准的正态分布。作用:①收敛过程加快,提升训练速度;②同时消除权重参数放大缩小带来的影响,解决梯度消失和爆炸问题;③简化调参过程,对初始化要求没那么高,而且可以使用大的学习率
- 数据预处理是对原始输入网络数据的操作,而BN是对网络中每一层输出的操作
- 有可学习的参数,因为均值方差归一化后,会导致网络表达能力下降,因此,增加两个参数,用来对变换后的激活反变换(作为还原参数,在一定程度上保留原数据的分布)使得网络表达能力增强。
3. SVM相关内容
补充基础:SVM【统计学习第七章】
- 原理:
- 函数间隔是什么?物理意义,起点终点
- 如何处理非线性问题
- 可以处理类别不平衡的样本吗
4. Dropout的作用和原理,在训练和测试时是如何运行?
补充基础:深度学习中的正则化【花书第七章】
- 原理:对于每个神经元,都有一定的概率被舍弃,也就是让其输出置零,进而不更新权重。最早dropout是在全连接层使用的,后来在卷积层中也增加了dropout功能
- 作用:为缓解CNN过拟合而被提出的一种正则化方法
- 缺点:Dropout带来的缺点就是可能会减缓模型收敛的速度,因为每次迭代只有一部分参数更新,可能导致梯度下降变慢
- 训练时前向传播只使用没有失活的那部分神经元,而测试时使用的是全部的神经元,那么训练和测试阶段就会出现数据尺度不同的问题。所以测试时,所有权重参数
都要乘以
,以保证训练和测试时尺度变化一致
5. 如何判断过拟合和欠拟合?怎么解决
补充基础:机器学习基础【花书第五章】
- 通过学习曲线的形态来判断。欠拟合情况:随着训练样本数增大,训练集得分和验证集得分收敛,并且两者的收敛值很接近。过拟合情况:随着训练样本数增大,训练集得分和验证集得分相差还是很大。
- 例如:d为多项式次数,当d很小的时候,训练误差和验证误差都很大,并且很接近,此时模型存在欠拟合问题;当d较大时,训练误差很小,但验证误差还是很大,此时模型存在过拟合问题。

- 过拟合产生原因:①神经网络的学习能力过强,复杂度过高;②训练时间太久;③激活函数不合适;④数据量太少
- 解决办法:①提前终止(当验证集的效果变差的时候);②L1和L2正则化加权;③数据增强;④降低模型复杂度,dropout
- 欠拟合产生原因:①数据上,特征不足或特征与目标的相关性不强;②模型过于简单
- 解决办法:①数据上,可以通过特征工程,例如上下文特征、组合特征等;②模型上,增加模型的复杂度,例如增加神经元、网络层数、高阶项等;③减少正则项
6. 说说Alexnet,VGG和ResNet的原理
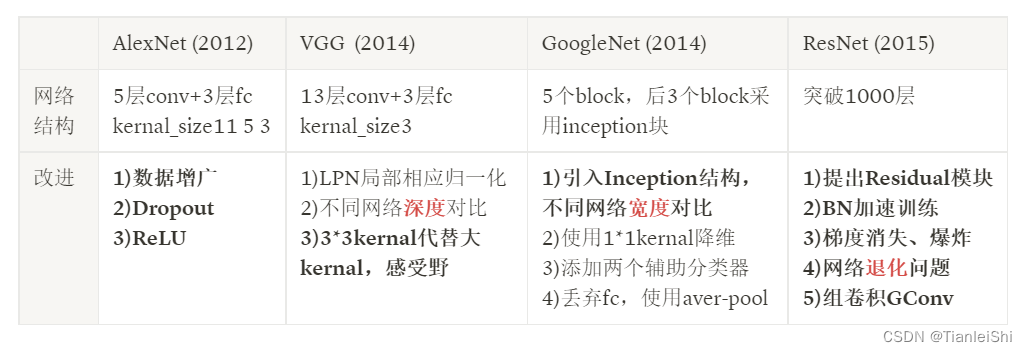
- AlexNet是一个较早应用在ImageNet上的深度网络,其准确度相比传统方法有一个很大的提升。它首先是5个卷积层,然后紧跟着是3个全连接层。AlexNet在卷积层和全连接层后面都使用ReLU激活函数。另外在每个全连接层后面加上Dropout层减少模型过拟合。还有数据增广
- ⏳顺势会问:不像传统神经网络早期所采用的Tanh或Sigmoid激活函数,ReLU的优势是其训练速度更快,因为Sigmoid的导数在稳定区会非常小,从而权重基本上不再更新。这就是梯度消失问题。
- VGG16是牛津大学VGG组提出的。VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,5x5)。但是由于卷积层的通道数过大,VGG并不高效,比如一个3x3的卷积核,如果其输入和输出的通道数均为512,那么需要的计算量为9x512x512
- ⏳顺势会问:对于给定的感受野,采用堆积的小卷积核是优于采用大的卷积核,首先因为3x3卷积核有利于更好地保持图像性质,其次多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)
GoogleNet理念:在深度网路中大部分的激活值是不必要的(为0),或者由于相关性是冗余。因此,最高效的深度网路架构应该是激活值之间是稀疏连接的,这意味着512个输出特征图是没有必要与所有的512输入特征图相连。存在一些技术可以对网络进行剪枝来得到稀疏权重或者连接。但是稀疏卷积核的乘法在BLAS和CuBlas中并没有优化,这反而造成稀疏连接结构比密集结构更慢。
- GoogLeNet设计了更高效的Inception的模块,使用了1x1卷积来降低计算量。同时使用不同大小的卷积核来抓取不同大小的感受野,另外一个设计是最后的卷积层后使用全局均值池化层替换了全连接层。
- ⏳顺势会问:Inception模块,(googlenet理念介绍)这个模块使用密集结构来近似一个稀疏的CNN,前面说过,只有很少一部分神经元是真正有效的,所以特定大小的卷积核数量设置得非常小
- ⏳顺势会问:所谓全局池化就是在整个2D特征图上取均值。这大大减少了模型的总参数量。在AlexNet中,全连接层参数占整个网络总参数的90%。使用一个更深更大的网络使得GoogLeNet移除全连接层之后还不影响准确度。其在ImageNet上的top-5准确度为93.3%,但是速度还比VGG还快
- ResNet设计一种残差模块,可以训练更深的网络。利用残差模块,可以训练152层的残差网络。与GoogLeNet类似,ResNet也最后使用了全局均值池化层。同时使用BN来加速训练,丢弃了dropout层
- ⏳顺势会问:梯度消失、爆炸问题,退化问题
- 补充解决梯度消失或爆炸问题的方法:①预训练+微调;②梯度剪切;③权重正则化;④ReLU激活;⑤BN层;⑥短链接;⑦LSTM中的门结构
在GoogLeNet和ResNet中可以看到,这是一种很好的设计典范,采用模块化结构可以减少我们网络的设计空间,另外一个点是模块里面使用瓶颈层可以降低计算量,这也是一个优势
7. 残差模块如何缓解梯度消失
- 残差网络的精妙之处在于它把对于完整的输出的学习问题归结于对于残差的学习(Residual Learning)问题。因为“短路”机制的存在,高层的梯度可以直接传递到低层,防止梯度消失,同时也提高了计算效率
残差单元可以解决退化问题的背后逻辑在于此:想象一个网络A,其训练误差为x。现在通过在A上面堆积更多的层来构建网络B,这些新增的层什么也不做,仅仅复制前面A的输出。这些新增的层称为C。这意味着网络B应该和A的训练误差一样。那么,如果训练网络B其训练误差应该不会差于A。但是实际上却是更差,唯一的原因是让增加的层C学习恒等映射并不容易。为了解决这个退化问题,残差模块在输入和输出之间建立了一个直接连接,这样新增的层C仅仅需要在原来的输入层基础上学习新的特征,即学习残差,会比较容易。
8. 目标检测和分割网络了解到什么程度
9. UNet的跳连接作用
Part2:项目相关
1. 说说你的项目,数据构成,网络架构,建模过程遇到哪些问题及如何解决的
2. 医学影像多人标注出现不一致情况怎么解决?如何用算法的方式减少误差
3. 如何处理医学影像数据类别不均衡的问题?
Part3:Coding基础
1. python深拷贝和浅拷贝的区别
2. tensorflow和pytorch哪个是动态图哪个是静态图,实现原理上有什么区别
参考来源:
深睿医疗算法岗:初试面经_笔经面经_牛客网 (nowcoder.com)
Dropout原理及作用_CV技术指南的博客-CSDN博客_dropout的原理
ResNet, AlexNet, VGG, Inception: 理解各种各样的CNN架构 - 知乎 (zhihu.com)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









