






 文章详细介绍了如何搭建AudioCraft项目,包括安装ffmpeg,创建并激活Python虚拟环境,安装torch及相关依赖库,特别是处理xformers的版本问题。此外,还讲解了如何更改huggingface和PyTorch的模型缓存目录,以及在遇到自动下载模型失败时的手动下载步骤,最后提到了在运行项目时遇到的模型加载错误及其解决方法。
文章详细介绍了如何搭建AudioCraft项目,包括安装ffmpeg,创建并激活Python虚拟环境,安装torch及相关依赖库,特别是处理xformers的版本问题。此外,还讲解了如何更改huggingface和PyTorch的模型缓存目录,以及在遇到自动下载模型失败时的手动下载步骤,最后提到了在运行项目时遇到的模型加载错误及其解决方法。
所需环境
- ffmpeg
- python>=3.9
- git
- cuda118(torch>=2.0)
安装ffmpeg
下载地址
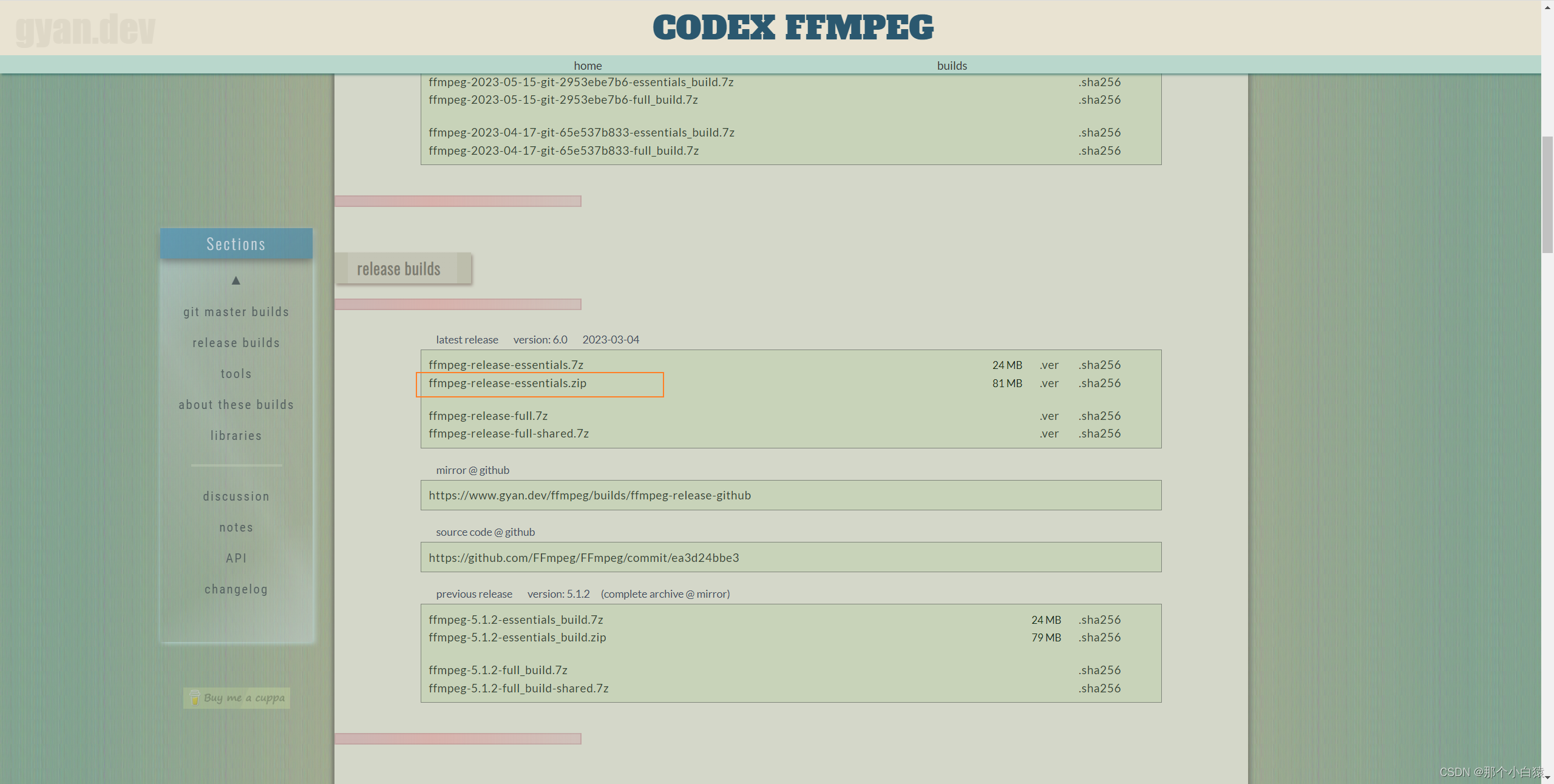
下载后解压,然后将解压后的目录配置到系统PATH环境变量中
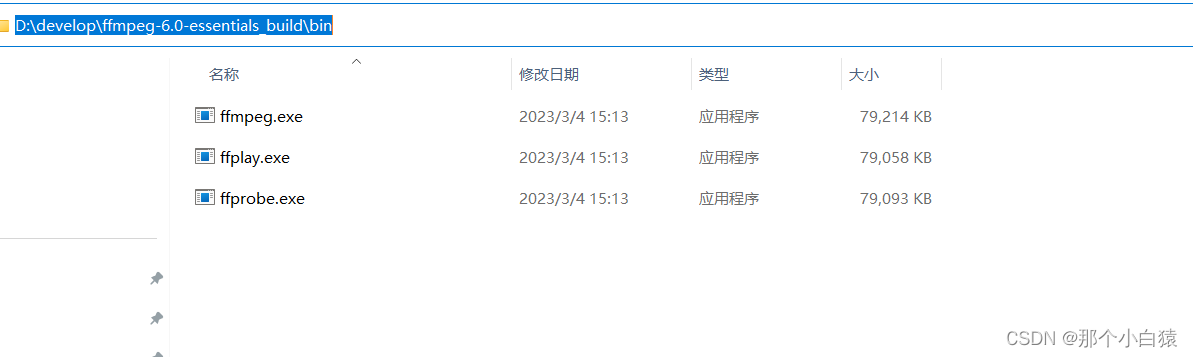
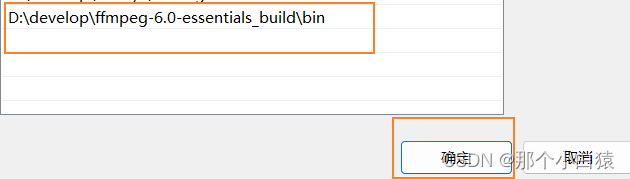
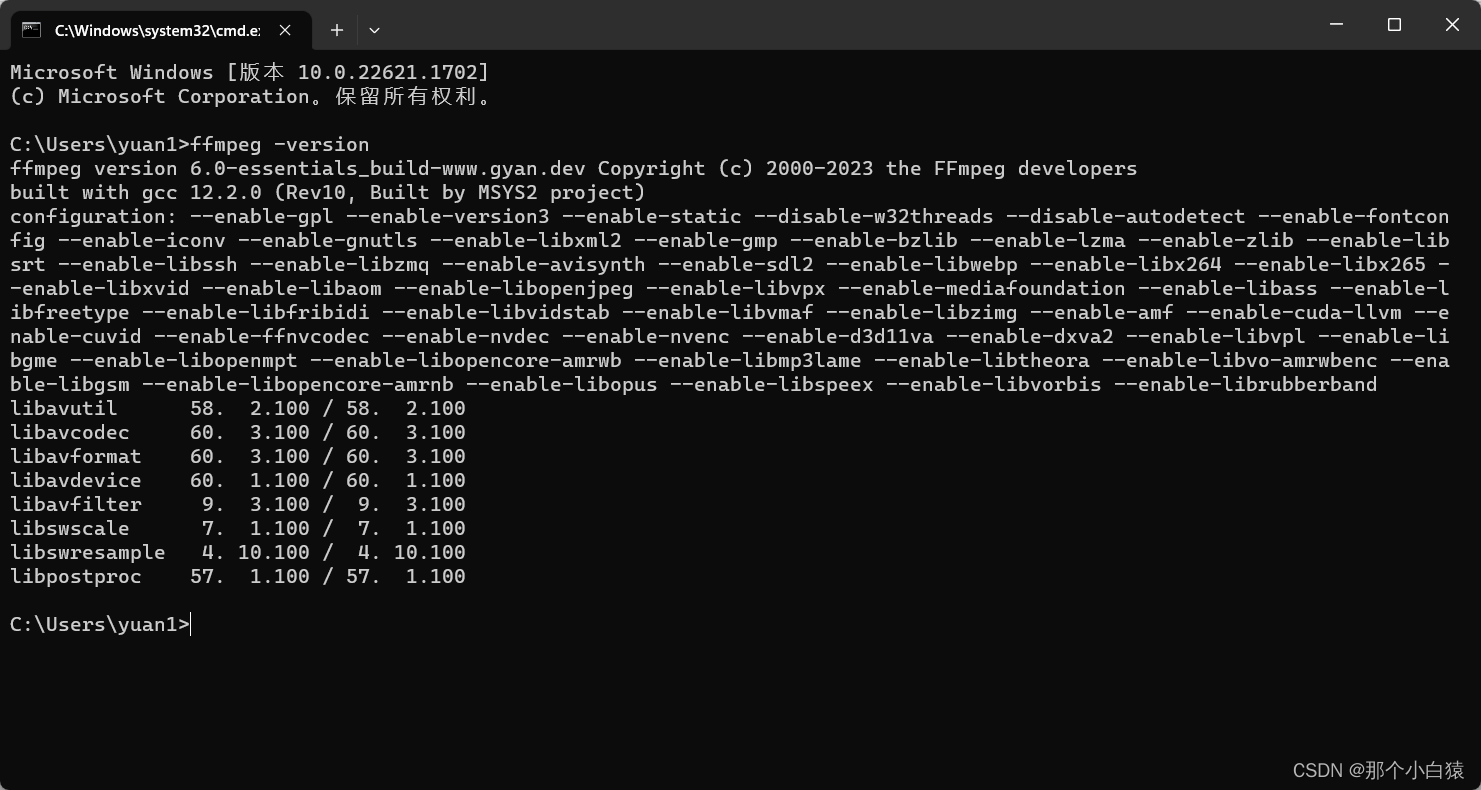
打开cmd,运行命令ffmpeg -version查看是否安装成功
克隆项目仓库
git clone https://github.com/facebookresearch/audiocraft.git
安装相关依赖库
# 进入到项目所在目录下,创建python虚拟环境
PS D:\AI\audio\audiocraft> python -m venv venv
# 激活python虚拟环境
PS D:\AI\audio\audiocraft> .\venv\Scripts\activate
# 安装torch
(venv) PS D:\AI\audio\audiocraft> pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装 requirements.txt 中的依赖
(venv) PS D:\AI\audio\audiocraft> pip install -e .
# 卸载默认安装的 xformers
(venv) PS D:\AI\audio\audiocraft> pip uninstall -y xformers
pip uninstall -y xformers
Found existing installation: xformers 0.0.20
Uninstalling xformers-0.0.20:
Successfully uninstalled xformers-0.0.20
# 安装符合torch版本的 xformers
(venv) PS D:\AI\audio\audiocraft> pip install xformers
运行项目
(venv) PS D:\AI\audio\audiocraft> python .\app.py
A matching Triton is not available, some optimizations will not be enabled.
Error caught was: No module named 'triton'
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
在浏览器中输入以上cmd打印的地址http://127.0.0.1:7860
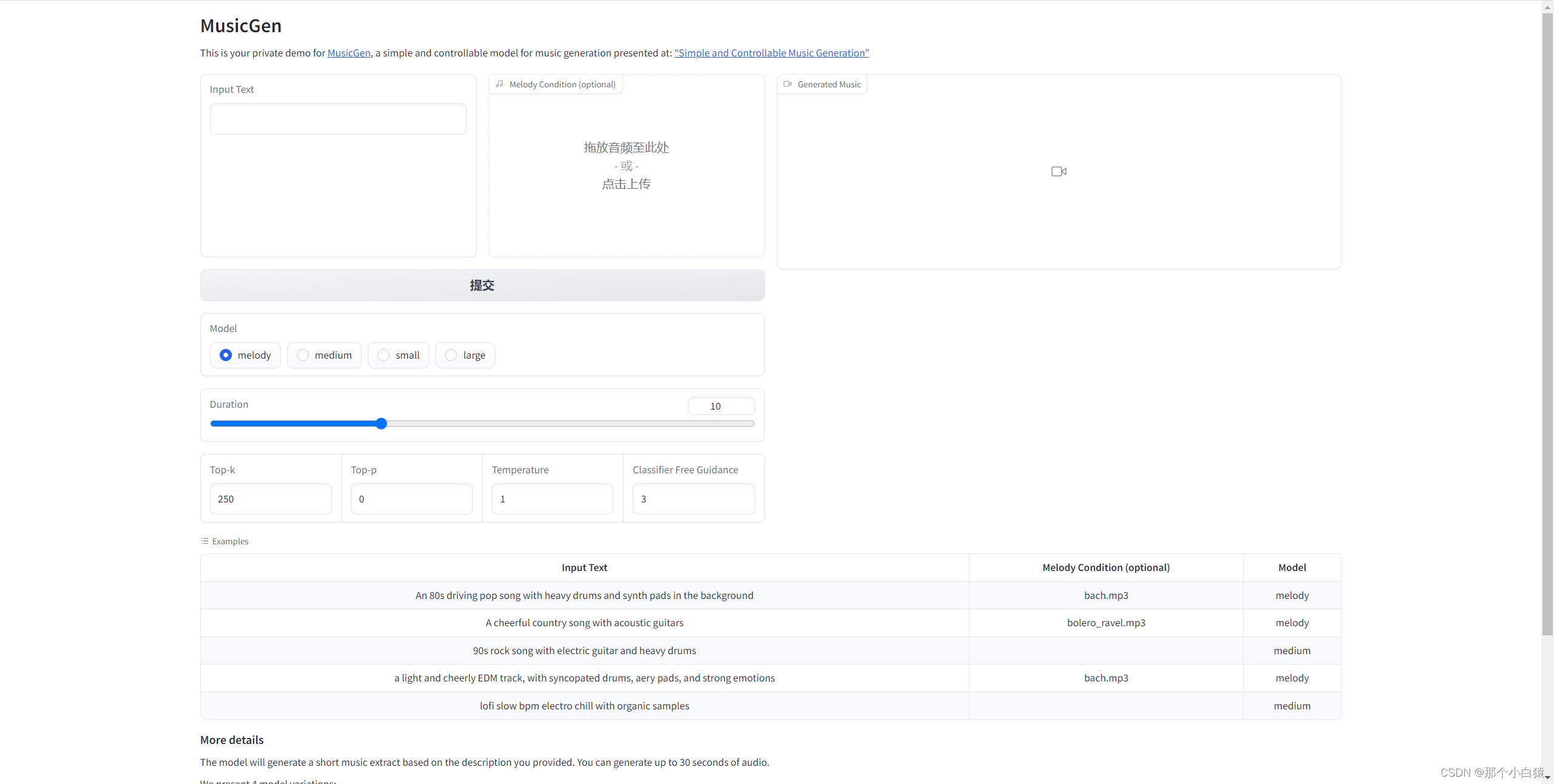
至此安装完成!
模型下载
在使用文本生成音乐的时,我们可以到界面上有四个模型的选项,代表了支持的四种模型,模型越大,对显卡显存要求就越大(官方建议显存VRAM 16G以上)。这四种模型分别为:
- small (300M), text to music, # see: https://huggingface.co/facebook/musicgen-small
- medium (1.5B), text to music, # see: https://huggingface.co/facebook/musicgen-medium
- melody (1.5B) text to music and text+melody to music, # see: https://huggingface.co/facebook/musicgen-melody
- large (3.3B), text to music, # see: https://huggingface.co/facebook/musicgen-large
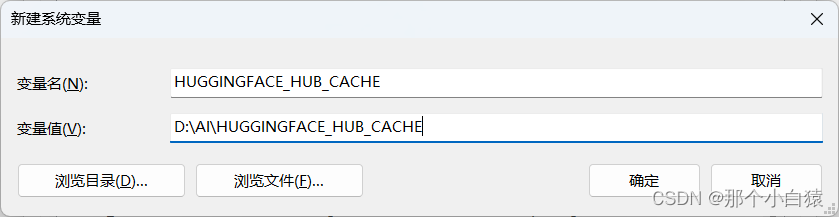
当点击相应模型去生成音乐时会去huggingface上下载对应的模型,且模型会默认缓存到 C:\Users\.cache\huggingface\hub中,这对于C盘空间占用不太友好,为此我们更改当前项目的模型缓存目录(可参考huggingface的文档),在系统变量中添加:
变量名:HUGGINGFACE_HUB_CACHE或者HF_HOME
变量值:自定义的模型缓存目录
查看原本的huggingface模型缓存目录
(venv) PS D:\AI\audio\audiocraft> huggingface-cli.exe scan-cache
REPO ID REPO TYPE SIZE ON DISK NB FILES LAST_ACCESSED LAST_MODIFIED REFS LOCAL PATH
----------------------------- --------- ------------ -------- ------------- ------------- ---- ----------------------------------------------------------------------------
openai/clip-vit-large-patch14 model 1.7G 6 24 hours ago 1 week ago main C:\Users\yuan1\.cache\huggingface\hub\models--openai--clip-vit-large-patch14
重新进入到当前项目的python虚拟环境查看huggingface模型缓存目录是否更新
(venv) PS D:\AI\audio\audiocraft> huggingface-cli.exe scan-cache
REPO ID REPO TYPE SIZE ON DISK NB FILES LAST_ACCESSED LAST_MODIFIED REFS LOCAL PATH
------- --------- ------------ -------- ------------- ------------- ---- ----------
Done in 0.0s. Scanned 0 repo(s) for a total of 0.0.
自动下载模型失败
在点击对应模型去生成音乐时会自动去huggingface下载模型,但是由于网络问题,大概率会下载报错,为此,我们可以将四个选项按钮分别点一遍,这样虽然模型无法下载成功,但是会在在缓存文件夹自动生成各个模型的目录,然后我们自己去各个模型的huggingface地址将模型手动下载后导入到对应的自动生成的模型目录
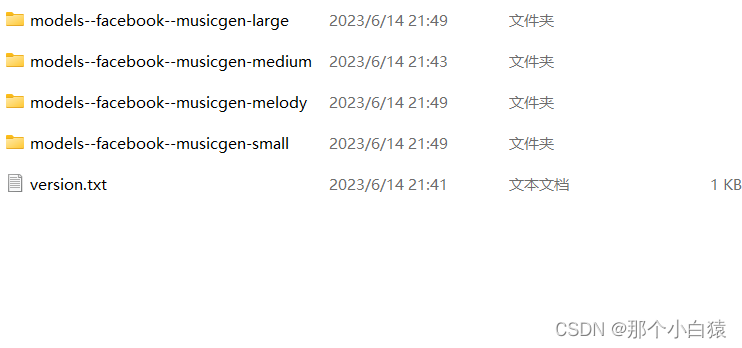
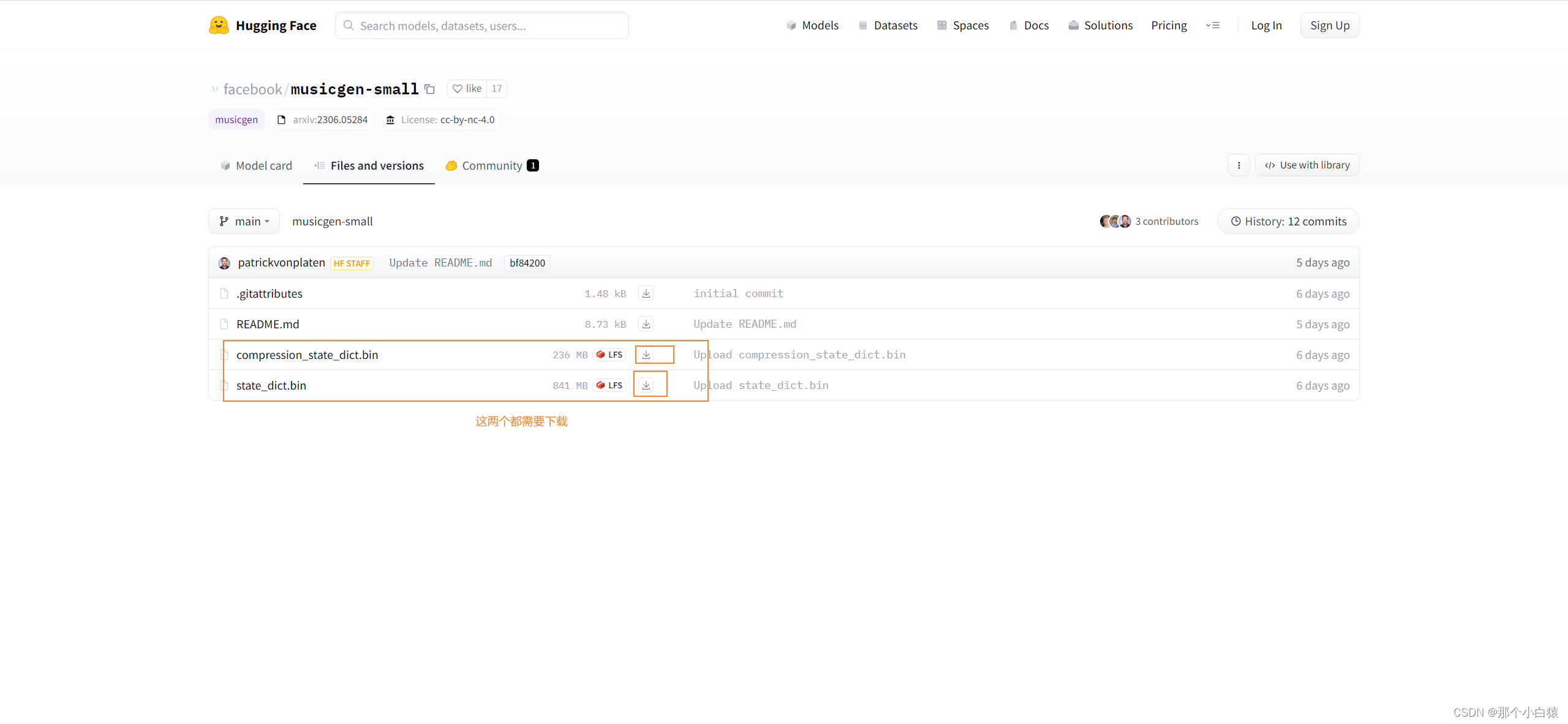
比如small模型的下载地址,下载好的compression_state_dict.bin以及state_dict.bin移动到以上自动生成的models--facebook--musicgen-small\snapshots\项目版本hash文件夹目录下即可!
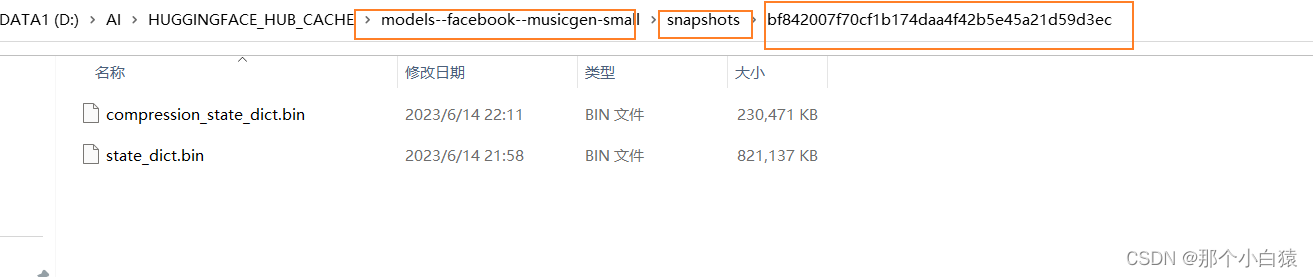
但是又有一个问题,我们首次点击了相应的模型去生成音乐时,在缓存目录只生成了一级目录,比如我这里使用medium模型以及large模型生成音乐时只是在缓存目录中生成了一级目录models--facebook--musicgen-medium以及models--facebook--musicgen-large,并没有进一步生成该一级目录下本该有的blobs、refs、snapshots目录
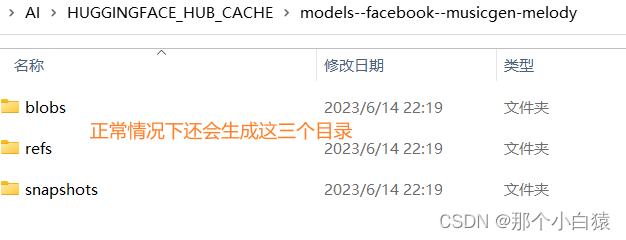
此时我们手动新建这三个目录,blobs是一个空目录,refs下有一个main文件,该文件的内容是一串hash值,即代表当前模型版本的提交记录hash,我们可以在huggingface相应的模型地中找到完整的hash值

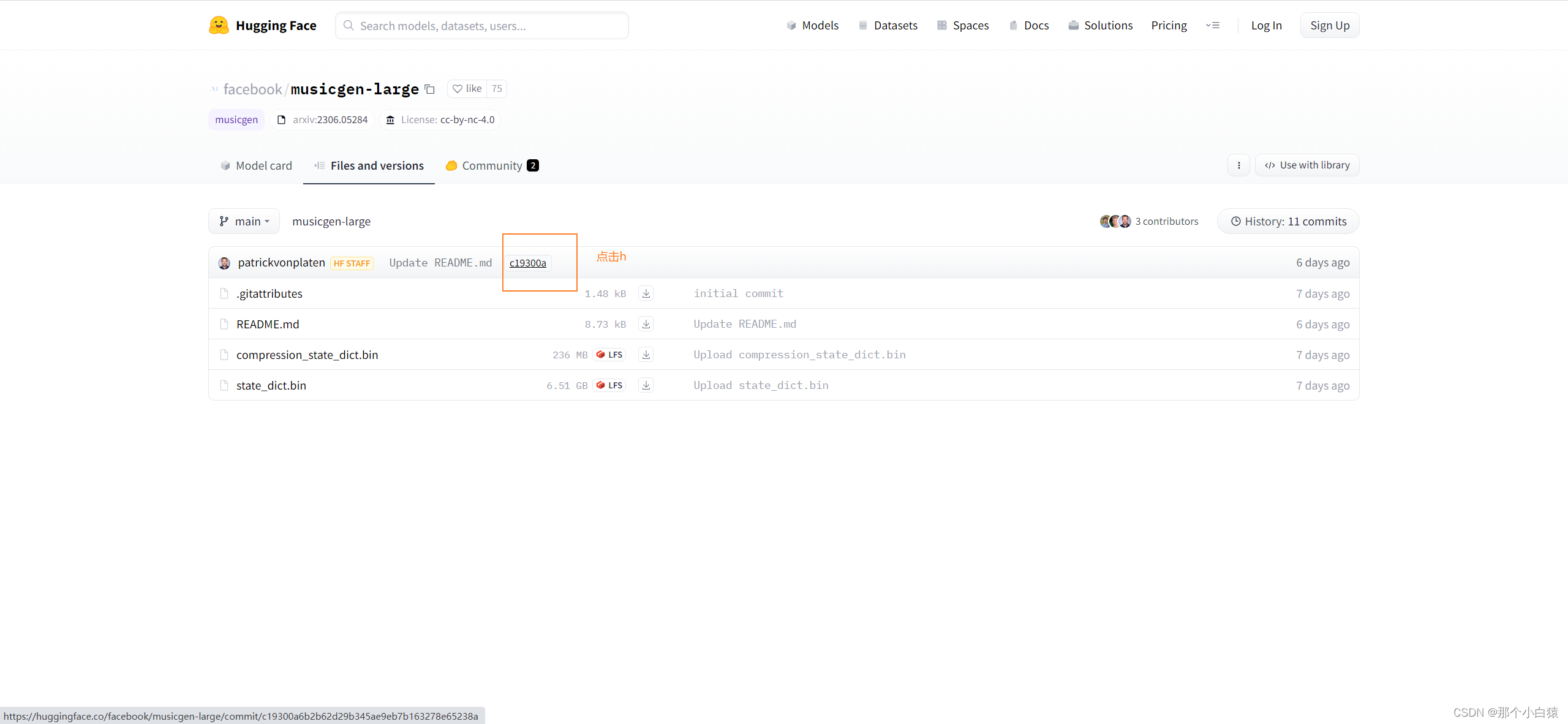
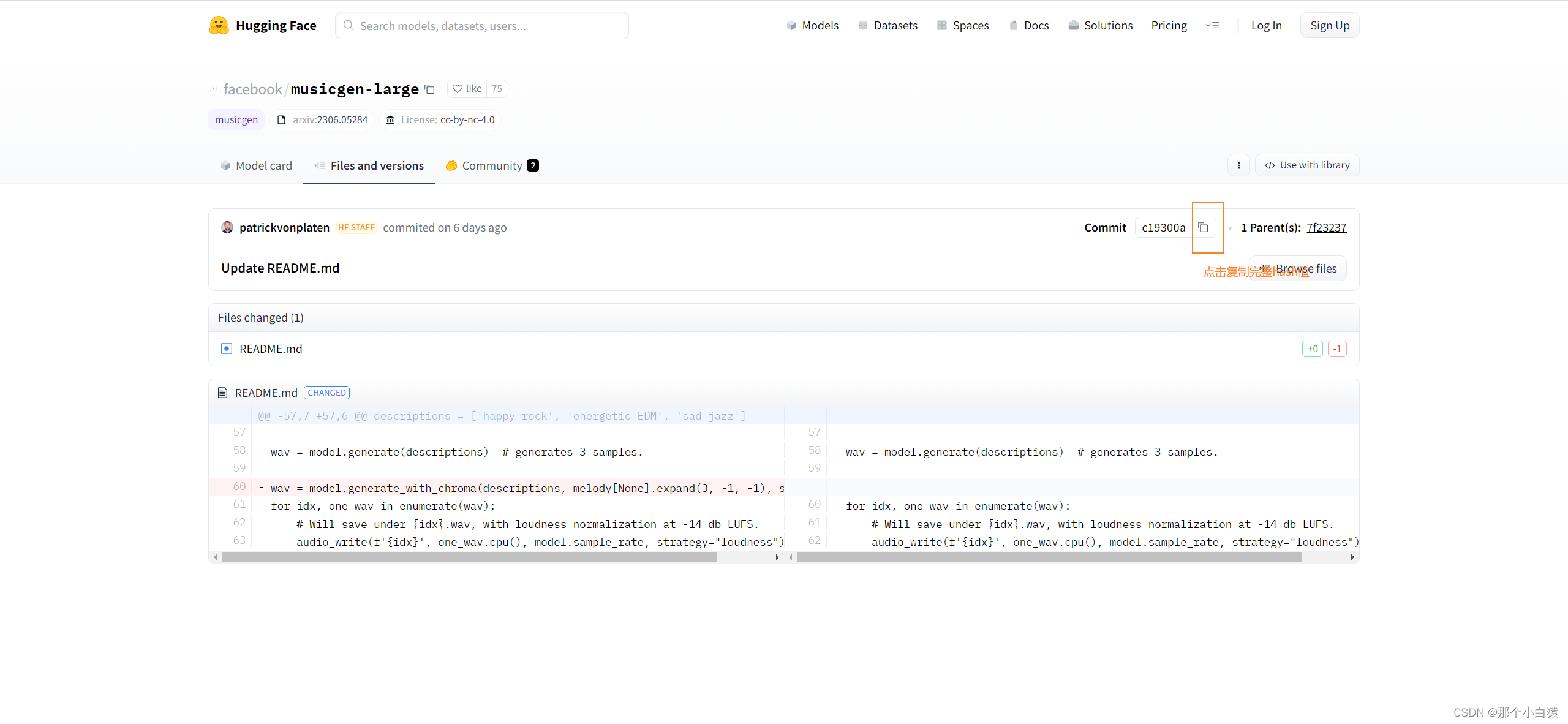
将复制的hash值放到main文件中保存,然后snapshots目录下还有一个目录,目录的名字就是这串hash值
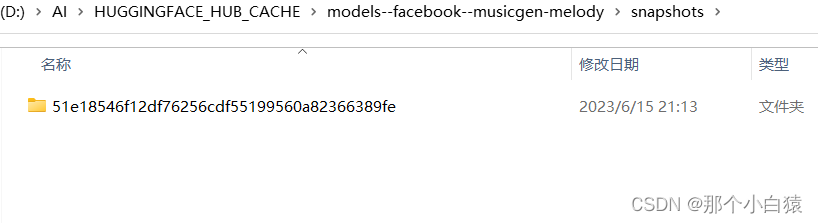
最后将下载的模型放入这个文件夹下即可
再次启动项目进行音乐生成时报错
raise EnvironmentError(
OSError: Can't load tokenizer for 't5-base'. If you were trying to load it from 'https://huggingface.co/models',
make sure you don't have a local directory with the same name. Otherwise,
make sure 't5-base' is the correct path to a directory containing all relevant files for a T5Tokenizer tokenizer.
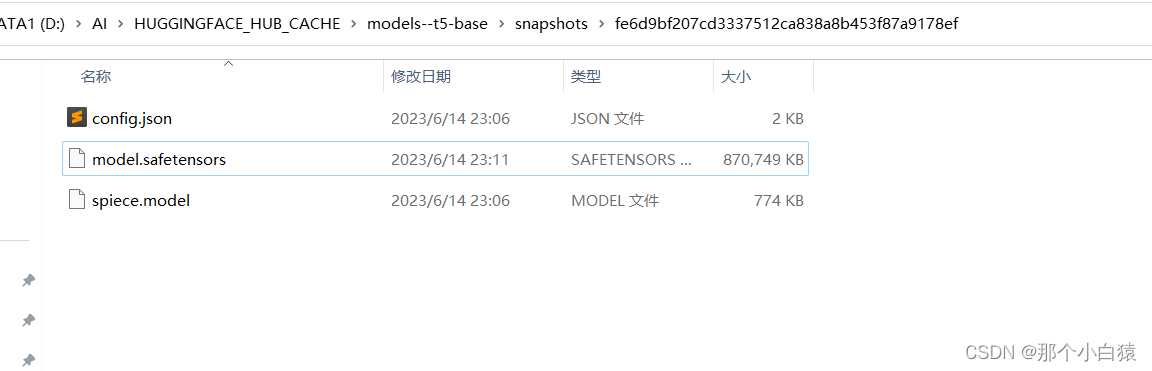
提示说要下载一个名叫t5-base的模型,其实回退到huggingface缓存跟目录可以看到已经自动生成了一个目录models-ts-base

于是我们打开huggingface的模型下载地址
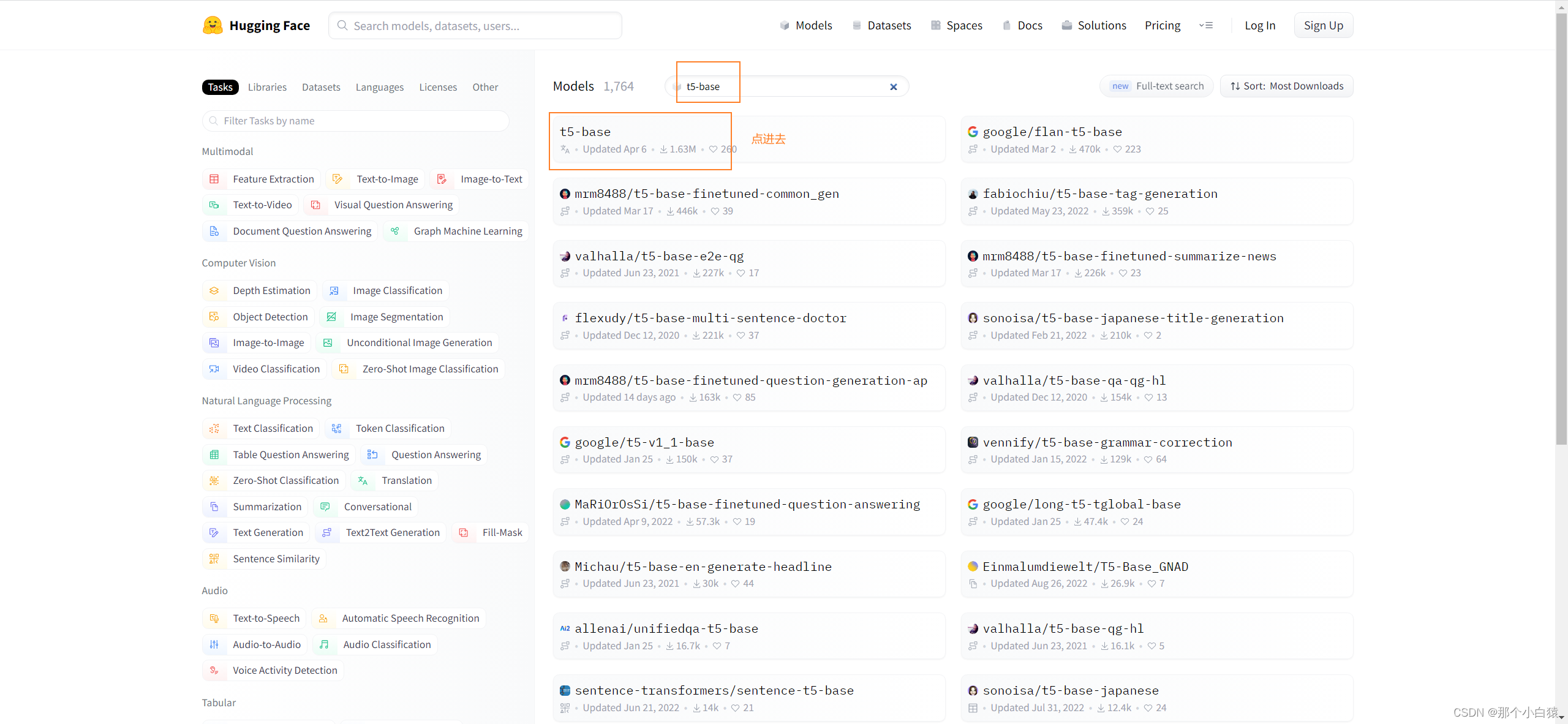
这里下载文件pytorch_model.bin以及config.json
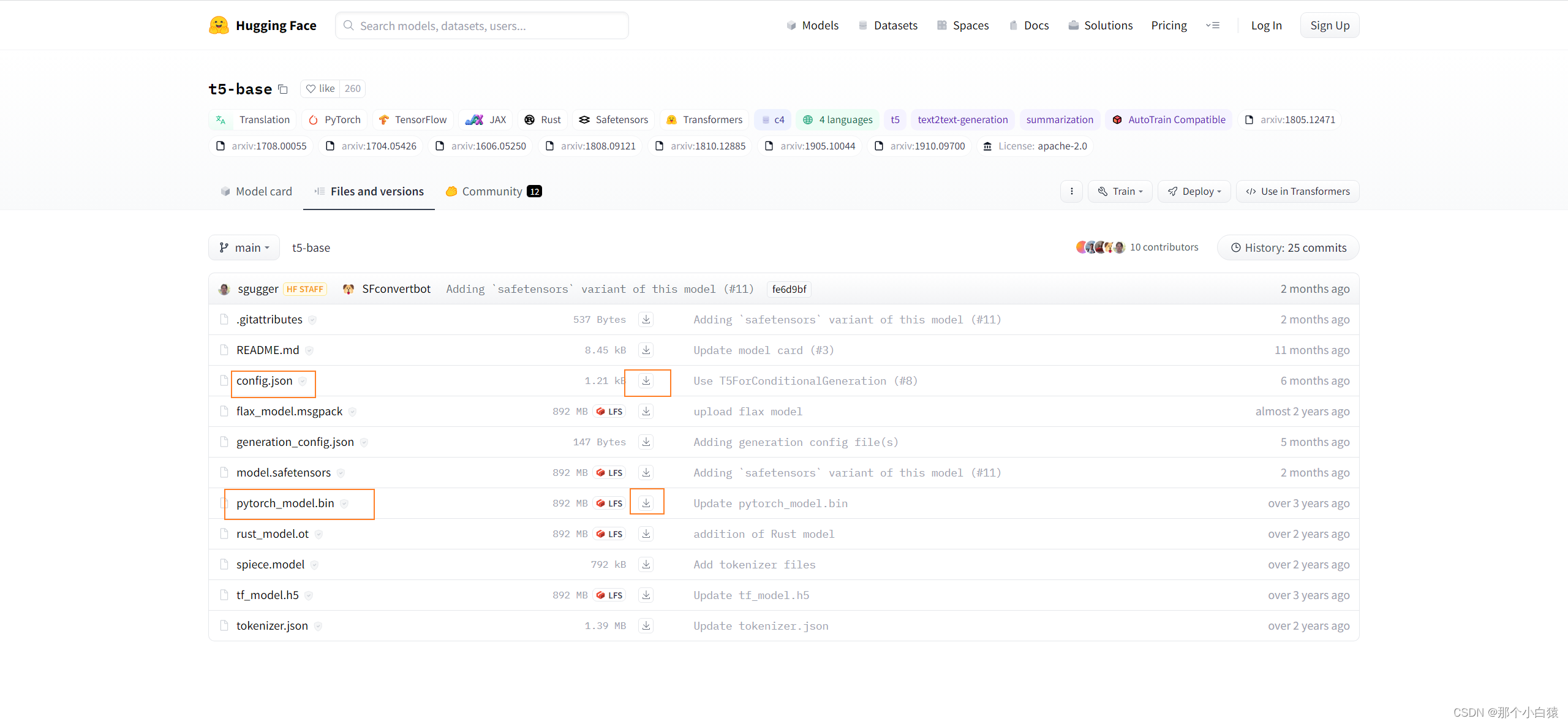
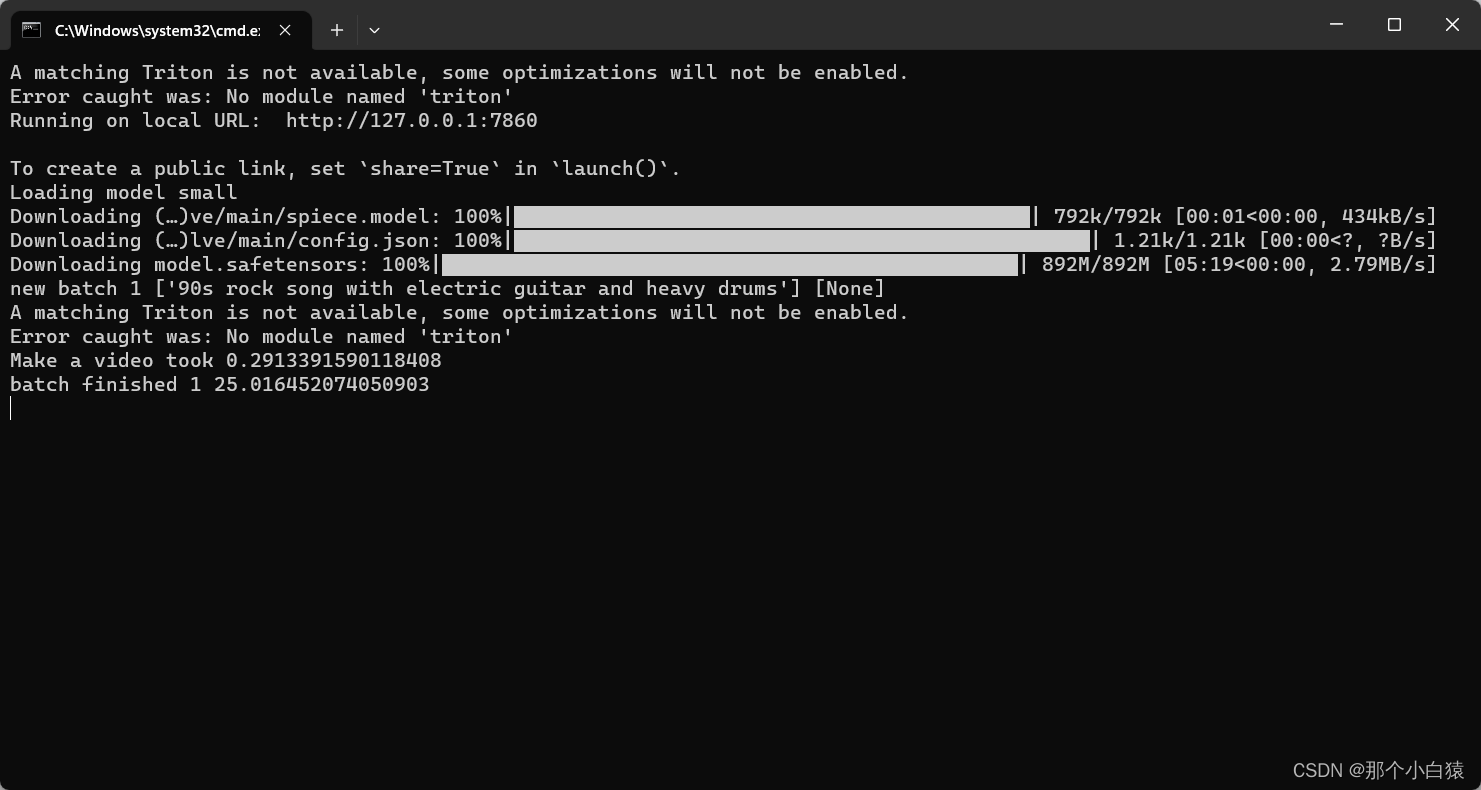
将下载好的文件放到models--t5-base目录下,然后重启项目再次生成音乐,会发现自动去下载所需的 model.safetensors模型,其实也就是我们以上搜索的t5-base仓库中的一个模型 model-safetensors,当然我们也可以手动将其下载下来放到以上生成的models-ts-base目录下
下载结果如下
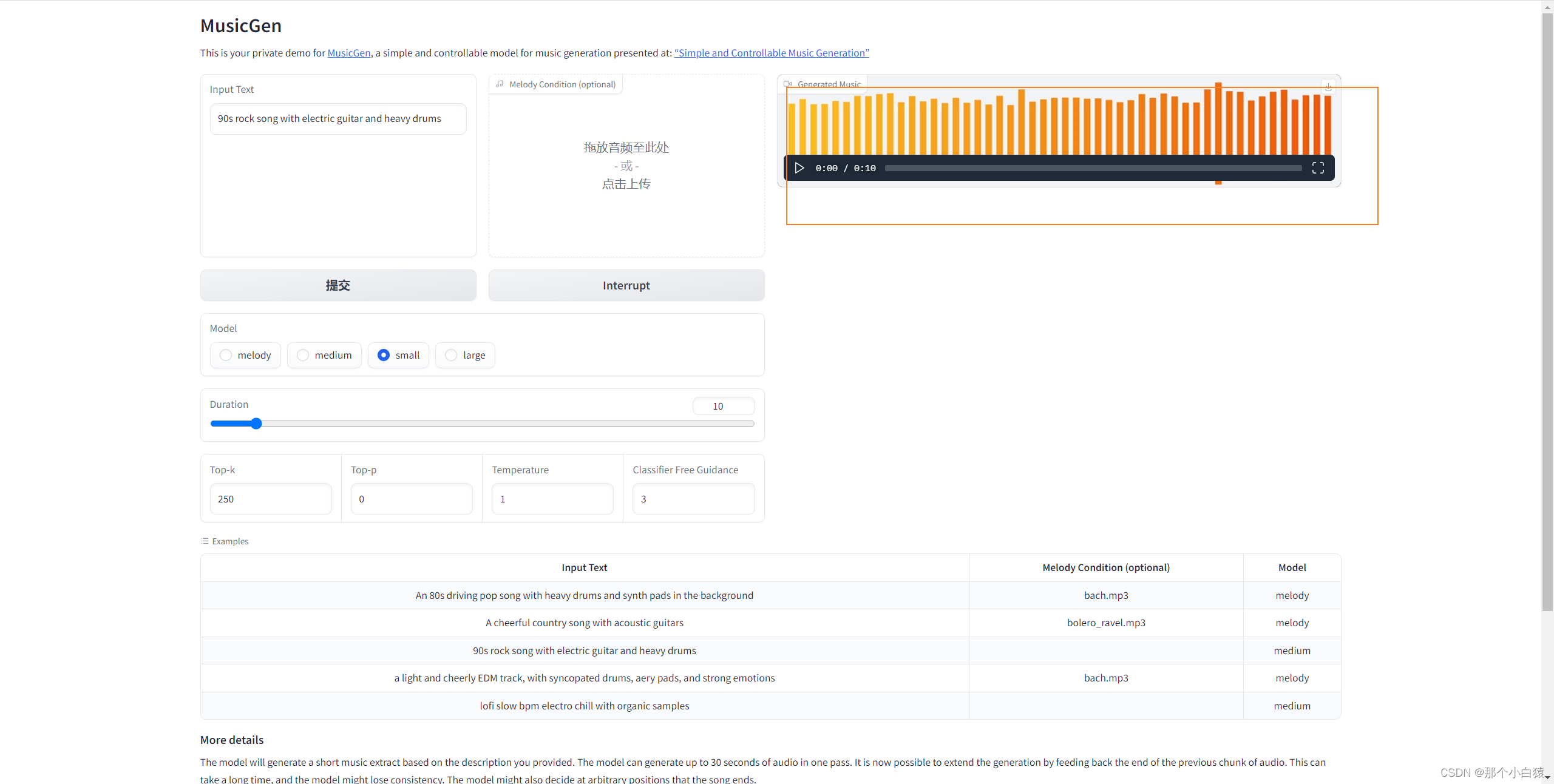
等待下载进度完成后,我们发现cmd中也没有报错,并且界面上成功生成了音乐
pytorch相关模型缓存目录
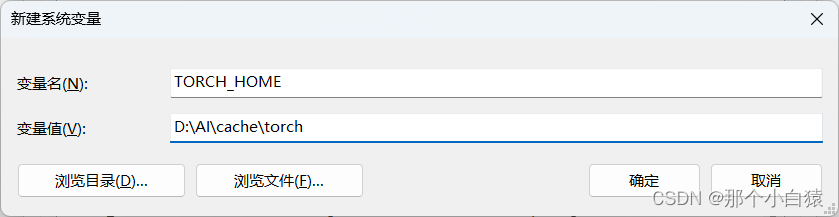
在使用melody模型生成音乐时可以看到控制台会去下载一个80M大小的模型955717e8-8726e21a.th,该模型的缓存地址在C盘的缓存目录下,这对于C盘空间占用不太友好,于是我们可以更改pytorch的模型下载缓存目录

新建环境变量,变量名必须是TORCH_HOME,变量值就是自定义的pytorch缓存目录,目录最好不要带中文


















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











