






 知名AI产品经理木易分享,OpenAI的GPT-4Preview在LMSYSLeaderboard上被Anthropic的Claude3Opus超越,反映出大语言模型技术的动态发展。排行榜揭示了当前顶级模型的综合表现,如Claude3系列和国产的Qwen1.5-72B-Chat.
知名AI产品经理木易分享,OpenAI的GPT-4Preview在LMSYSLeaderboard上被Anthropic的Claude3Opus超越,反映出大语言模型技术的动态发展。排行榜揭示了当前顶级模型的综合表现,如Claude3系列和国产的Qwen1.5-72B-Chat.
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
作为一个公认的AI领域基准测试平台,LMSYS Leaderboard排行榜专门用于评估和比较全球各个人工智能语言模型的性能。OpenAI的GPT-4 Preview模型自发布以来,一直高居榜首,处于绝对的碾压地位。但在LMSYS Leaderboard排行榜最近的一次更新中,Claude 3 Opus模型综合评分已超过GPT-4 Preview模型斩获头名, 也是GPT-4 Preview自发布以来分数首次被其他模型超越。
Claude 3 Opus模型以更好的输出质量与更快的回复速度受到用户青睐. 虽然榜单前三名实际上Elo综合分数非常接近,在误差范围内可以算是并列第一, 但这依旧体现了Anthropic在大语言模型技术上的一次飞跃,打破了之前GPT-4一家独大的局面。
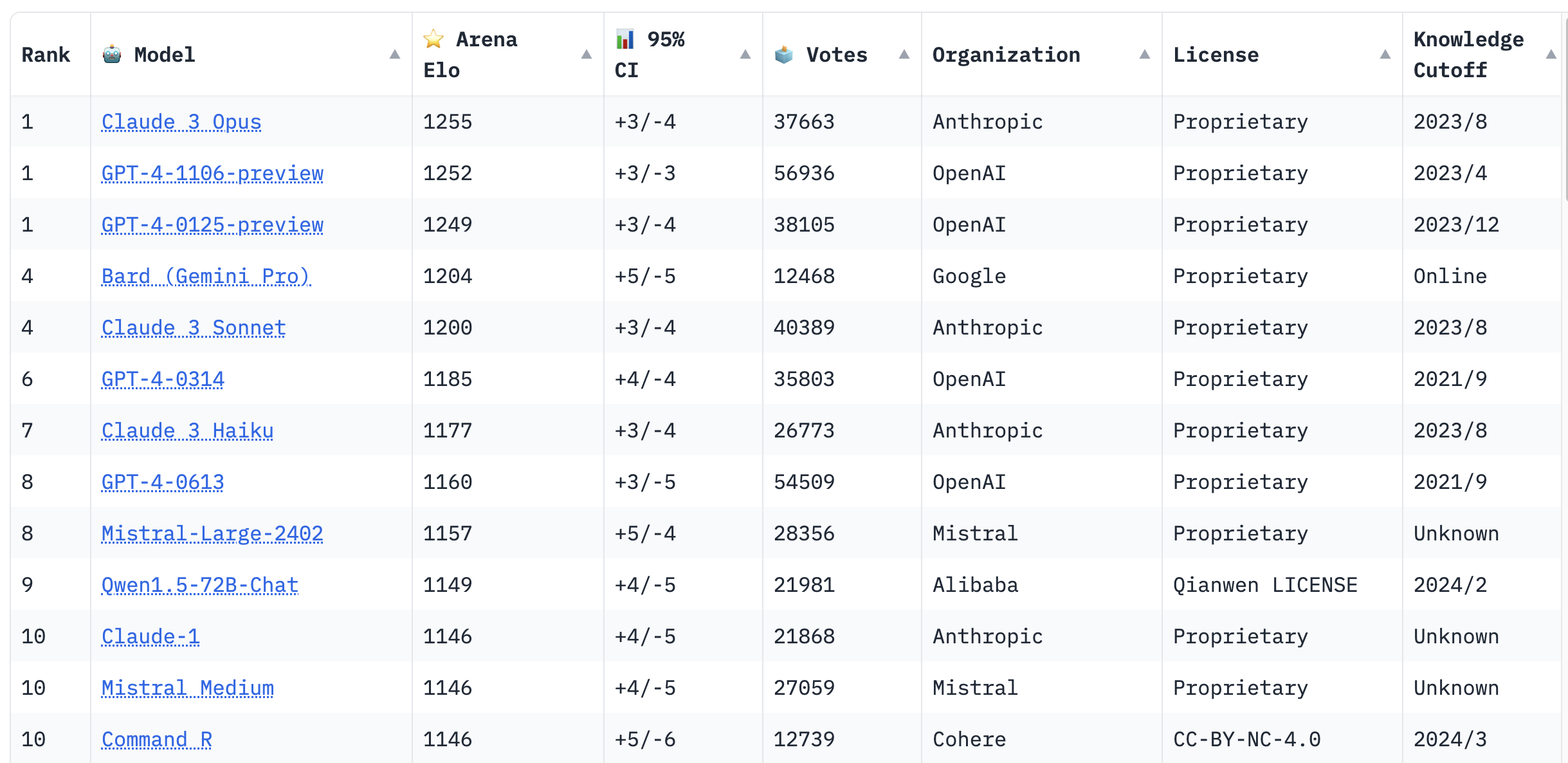
目前LMSYS Leaderboard排行榜前10名大语言模型总结如下:
| 🏆 | 🤖 模型 | ⭐ Arena Elo | 🗳️ 投票数 | 🏢 组织 | 📆 知识截止日期 |
|---|---|---|---|---|---|
| 1️⃣ | Claude 3 Opus | 1255 | 37663 | Anthropic | 2023/8 |
| 1️⃣ | GPT-4-1106-preview | 1252 | 56936 | OpenAI | 2023/4 |
| 1️⃣ | GPT-4-0125-preview | 1249 | 38105 | OpenAI | 2023/12 |
| 4️⃣ | Bard (Gemini Pro) | 1204 | 12468 | 在线 | |
| 4️⃣ | Claude 3 Sonnet | 1200 | 40389 | Anthropic | 2023/8 |
| 6️⃣ | GPT-4-0314 | 1185 | 35803 | OpenAI | 2021/9 |
| 7️⃣ | Claude 3 Haiku | 1177 | 26773 | Anthropic | 2023/8 |
| 8️⃣ | GPT-4-0613 | 1160 | 54509 | OpenAI | 2021/9 |
| 8️⃣ | Mistral-Large-2402 | 1157 | 28356 | Mistral | 未知 |
| 9️⃣ | Qwen1.5-72B-Chat | 1149 | 21981 | Alibaba | 2024/2 |
| 🔟 | Claude-1 | 1146 | 21868 | Anthropic | 未知 |
| 🔟 | Mistral Medium | 1146 | 27059 | Mistral | 未知 |
| 🔟 | Command R | 1146 | 12739 | Cohere | 2024/3 |
关于LMSYS Leaderboard
LMSYS是一个专注于LLMs大语言模型的研究组织,全称为LMSYS Organization。该组织由加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学合作创立,旨在推动大型语言模型的研究、评估和应用。
LMSYS Organization的核心项目之一是Chatbot Arena,这是一个为大型语言模型提供基准测试的平台。它采用了类似于国际象棋等竞技游戏中广泛使用的Elo评分系统,通过众包方式进行匿名、随机对抗测评。在Chatbot Arena中,系统会随机选择两个不同的大型语言模型进行比较,用户在与这些模型的互动中进行评估,并在匿名的情况下选择哪款模型的表现更佳。这种评测方式旨在提供一个公正、透明的评估环境,帮助研究者和开发者了解和改进他们的模型。

LMSYS Organization通过其基准测试平台和相关活动,已经成为AI领域内公认的权威机构之一。
LMSYS Leaderboard排行榜是如何生成的?
LMSYS Leaderboard排行榜是通过一个公正和互动的过程生成的,其中用户输入的提示被用于引导不同的大型语言模型(LLMs)生成回答,然后用户在不知道哪个模型生成了哪个回答的情况下,选择他们认为更好的回答。LMSYS Organization的平台记录这些选择,根据用户的反馈和偏好来评估模型的表现,并据此实时更新排行榜,从而提供一个动态的、用户驱动的模型性能评估。
步骤 1:用户输入提示(Prompt)
-
用户访问LMSYS Organization的在线平台,并输入一个提示(prompt)。这个提示是一个问题或话题,用于引导LLM生成回答。
步骤 2:模型生成回答
-
用户输入的提示会被送入两个不同的语言模型中。这些模型可能是由不同的团队开发,具有不同的架构和训练数据集。
步骤 3:匿名显示回答
-
平台将从两个模型中生成的回答展示给用户,但不会透露哪个回答是由哪个模型产生的。这样做是为了确保用户的评价不受模型品牌或先入为主的观念影响。
步骤 4:用户选择最佳回答
-
用户阅读这两个回答后,根据自己的判断选择认为更好的一个。用户的选择基于回答的相关性、准确性、可读性、创造性或其他个人认为重要的因素。
步骤 5:跟踪和计算
-
LMSYS Organization的平台会记录每个用户的选择,并使用这些数据来跟踪每个模型相对于其他模型的表现。这种比较是基于用户的选择和反馈,而不是单一的指标或专家评审。
步骤 6:生成排行榜
-
基于用户的选择和反馈,LMSYS Organization计算并更新一个实时的排行榜。这个排行榜展示了各个模型的综合表现,并根据它们的相对优劣进行排名。
Claude 3 VS GPT-4
Claude 3系列模型发布于2024年3月4日,由Anthropic公司开发。Claude 3系列模型共有三个版本,按照模型的“智商”排名分别是:Haiku < Sonnet < Opus。Claude 3的三个模型上下文长度默认都是200,000 token,但对于有特定需求的用户,可以定制到1,000,000 token的上下文窗口。Claude 3在发布时,Anthropic就表示Claude 3 Opus模型在能力上已全面超越 GPT-4。时至今日,网友们表示,Anthropic这句话并不是说说而已。
最早的GPT-4模型发布于2023年3月14日,由OpenAI开发。后来陆续推出了GPT-4模型的优化版本,LMSYS Leaderboard排行榜中的GPT-4 Preview模型就是其中之一,包括了GPT-4-1106-preview和GPT-4-0125-preview。GPT-4模型一经发布立刻在科技领域掀起轩然大波,它的数学能力、代码能力以及逻辑推理能力比上一代模型GPT-3.5强了不是一点半点,这也是GPT-4模型在各大排行榜都霸榜的原因。

通义大模型Qwen1.5-72B-Chat
细心的小伙伴可能已经发现,在LMSYS Leaderboard前10名榜单中,有一个国产大模型是我们熟悉的身影,它就是我们之前介绍和测评过多次的通义大模型Qwen1.5-72B-Chat。目前Qwen1.5-72B-Chat处于LMSYS Leaderboard榜单第9名。

Qwen1.5-72B-Chat是阿里研发的通义千问大模型系列中的一个版本,是基于Transformer架构的大语言模型。这个模型在超大规模的预训练数据上进行训练,数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。Qwen1.5系列模型支持多种参数规模,从0.5B到72B不等,以适应不同的应用场景和需求。Qwen1.5-72B在多个基准测试中都超越了Llama2-70B,展示了其在语言理解、推理和数学方面的强大能力。
关于阿里通义千问的更多介绍,可以看我之前的一些介绍和测评文章。
精选推荐
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。

















 106
106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









