







机器学习解决问题的通用流程,主要分为4大部分:
1.问题建模
2.特征工程
3.模型选择
4.模型融合
问题建模包含三部分:评估指标、样本选择、交叉验证
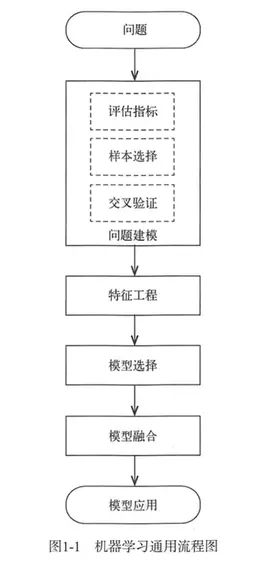
1.1评估指标
评估指标用于反映模型效果,预测问题中,将预测结果和真实结果进行比较,为:

实际项目中,线下和线上的评估指标尽可能变化趋势保持一致,线上成本明显高于线下实验成本,在线上实验较长时间并对效果进行可信度检验(如
t
−
t
e
s
t
t-test
t−test)才能得到结论,必然导致模型迭代进度缓慢。
1.1.1分类指标
1.精确率和召回率
多用于二分类问题
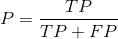
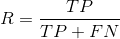
T
P
TP
TP表示真实结果为正例,预测结果也是正例;
F
N
FN
FN表示真实结果为正例,预测结果为负例;
F
P
FP
FP表示真实结果为负例,预测结果为正例;
T
N
TN
TN表示真实结果为负例,预测结果也是负例。
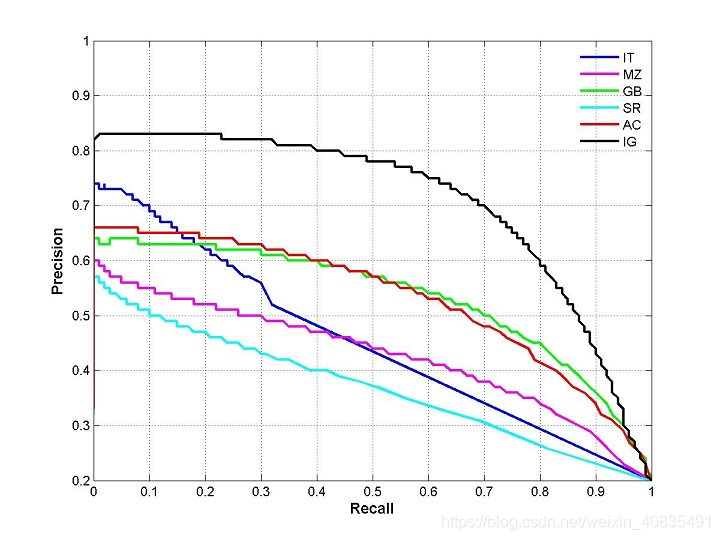
P-R曲线
P
−
R
P-R
P−R曲线越靠近右上角性能越好,曲线下面积为
A
P
AP
AP分数(平均精确率分数),面积大小能够反映不同模型的性能指标,但是这个值计算方法不好使,设计综合考虑两者的指标。
F
1
F_1
F1值是精确率和召回率的调和平均值:
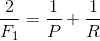
准确率(
a
c
c
u
r
a
c
y
accuracy
accuracy)=
T
P
+
T
N
T
P
+
F
P
+
F
N
+
T
N
\frac{TP+TN}{TP+FP+FN+TN}
TP+FP+FN+TNTP+TN
错误率( e r r o r r a t e error rate errorrate)= F P + F N T P + F P + F N + T N \frac{FP+FN}{TP+FP+FN+TN} TP+FP+FN+TNFP+FN
精确率是一个二分类指标,而准确率常用于多分类,其计算公式为:
准确率( a c c u r a c y accuracy accuracy)= 1 n ∑ i = 1 n I ( f ( x i ) = y i ) \frac{1}{n}\sum_{i=1}^{n} I(f(x_i)=y_i) n1∑i=1nI(f(xi)=yi)
2.
R
O
C
ROC
ROC与
A
U
C
AUC
AUC
很多机器学习模型中,输出为预测概率,而对于预测概率设定阈值,当预测概率大于阈值时为正例,小于阈值时为负例,这会多出一个阈值这个位置参数,且会影响模型的泛化能力。
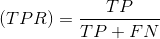
假正率

下图为ROC曲线示意图。
上图为ROC曲线,纵坐标为真正率,横坐标为假正率,模型靠近左上角性能越好。
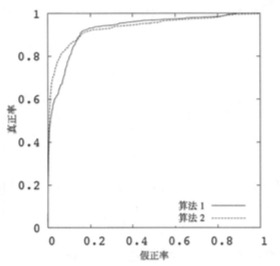
如何绘制?
将样本预测概率按照从大到小排序,以每个样本的预测概率为阈值,大于阈值的预测为正例,小于阈值到的预测为负例,再根据样本本身的真假计算FPR和TPR大小,将其作为坐标,绘制在图中,当所有样本绘制结束后,形成的曲线就是ROC曲线。
AUC(Area Under Roc Curve)即ROC曲线下的面积。面积大小表示正样本排在负样本的可能性大小,表示正确率越高;AUC考虑的是样本排序的质量,对于预测分数大小没有这么敏感。
3.对数损失
3.1熵
熵表示一件事情发生的不确定性或系统的不确定性,熵越大,不确定性就越大。
表达式为:
H ( x ) = − p ( x ) log ( p ( x ) ) H(x)=-p(x)\log(p(x)) H(x)=−p(x)log(p(x))
p
(
x
)
=
0
或
1
p(x)=0或1
p(x)=0或1时表示时间必定发生或者不发生,其熵为0;当
p
(
x
)
=
1
2
p(x)=\frac{1}{2}
p(x)=21时,其不确定性最大,熵为
1
2
\frac{1}{2}
21,为最大值。
当某个模型作用在样本上对于其预测值为0-1之间的数时,假设有M个样本,每个样本的预测分数为
p
i
p_i
pi,则这个模型的熵大小为
∑
i
p
i
∗
log
p
i
\sum_{i} p_i*\log p_i
∑ipi∗logpi
H
(
x
)
H(x)
H(x)也叫做平均信息量,当不确定性越大时,其平均信息量就越大。当信息确定时,则得到的信息就确定了,信息量就少了。
3.2交叉熵
定义为:在真实分布下,若存在非真实分布,用非真实分布指定的策略消除系统中的不确定性所付出的成本。也就是非真实分布和真实分布之间的差异大小。我得理解就是像最大释然估计一样,用非真实的分布区拟合真实分布所付出的代价大小就是交叉熵。
公式如下:
H
(
p
,
q
)
=
−
p
(
x
)
log
(
q
(
x
)
)
H(p,q)=-p(x)\log(q(x))
H(p,q)=−p(x)log(q(x))
上面的p(x)表示真实分布,q(x)表示非真实分布,
H
(
p
,
q
)
H(p,q)
H(p,q)表示两个分布的差异大小,非真实分布越接近真实分布,其交叉熵越低,该非真实分布也就越优。
二分类上:
例:
y
=
1
y=1
y=1的似然函数是对于y标签的预测y^,
y
=
0
y=0
y=0的似然函数是对于y标签的预测1-y^;
最大化似然函数:
p
⃗
(
x
)
log
p
(
x
)
=
y
∗
log
(
y
⃗
)
+
(
1
−
y
)
∗
log
(
1
−
y
⃗
)
\vec p(x)\log p(x)=y*\log(\vec y) +(1-y)*\log(1-\vec y)
p(x)logp(x)=y∗log(y)+(1−y)∗log(1−y)
交叉熵函数:
−
(
p
⃗
(
x
)
log
p
(
x
)
=
y
∗
log
(
y
⃗
)
+
(
1
−
y
)
∗
log
(
1
−
y
⃗
)
)
-(\vec p(x)\log p(x)=y*\log(\vec y) +(1-y)*\log(1-\vec y))
−(p(x)logp(x)=y∗log(y)+(1−y)∗log(1−y))
他们区别在于:交叉熵与最大似然函数相差一个负号
关系为最大似然函数=最小化交叉熵(相同)
也就是让非真实分布和真实分布之间的差异能够减小,这也是最大似然函数的宗旨。
3.3对数损失函数
lgloss是对预测概率的似然估计,其标准形式为:
l o g l o s s = − log P ( Y ∣ X ) logloss=-\log P(Y|X) logloss=−logP(Y∣X)
其中P(Y|x)表示在已知分布X下,Y发生概率大小。
对数损失函数最小化表示用样本的已知分布,求解导致这种分布的最佳模型参数(这和最大似然估计的思想基本相同,都是利用样本分布来求解模型参数)。
对数损失函数对应的二分类的计算公式为:
l o g l o s s = − 1 N ∑ i − 1 N ( y i ∗ log p i + ( 1 − y i ) ∗ log p i ) logloss =-\frac{1}{N} \sum_{i-1}{N} (y_i*\log p_i +(1-y_i)*\log p_i) logloss=−N1∑i−1N(yi∗logpi+(1−yi)∗logpi)
其中, y ∈ 0 , 1 , p i y \in {0,1} ,p_i y∈0,1,pi为第i个样本预测为1的概率。
在多分类任务中,其计算公式为:
l
o
g
l
o
s
s
=
−
1
N
∗
1
C
∗
∑
i
=
1
N
∑
j
=
1
C
y
i
j
∗
log
p
i
j
logloss=-\frac{1}{N}*\frac{1}{C}*\sum_{i=1}^{N} \sum _{j=1}^{C} y_{ij}* \log p_{ij}
logloss=−N1∗C1∗∑i=1N∑j=1Cyij∗logpij
其中,N为样本数,C为类别数,
y
i
j
=
1
y_{ij}=1
yij=1表示第i个样本的类别是j,
p
i
j
p_{ij}
pij为第i个样本类别为j的概率。
与交叉熵思想一样,Logloss衡量的是预测概率分布和真实概率分布的差异性,取值越小越好。和AUC不同,logloss对预测概率敏感。
参考文献:
1.https://www.jianshu.com/p/d0c59c2470ba
2.《美团机器学习实践》
3.自己的笔记














 1949
1949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









