






# 谷歌全面转向JAX
哪个也没学完 永远技术都更新这么快 谷歌放弃TensorFlow?
TensorFlow 大概已经成为了谷歌的一枚「弃子」。
015 年,谷歌大脑开放了一个名为「TensorFlow」的研究项目,这款产品迅速流行起来,成为人工智能业界的主流深度学习框架,塑造了现代机器学习的生态系统。
七年后的今天,故事的走向已经完全不同:谷歌的 TensorFlow 失去了开发者的拥护,因为他们已经转向了 Meta 推出的另一款框架 PyTorch。
曾经无处不在的机器学习工具 TensorFlow 已经悄悄落后,而 Facebook 在 2017 年开源的 PyTorch 正在成为这个领域的霸主。
近日,外媒 Business Insider 采访了一系列开发人员、硬件专家、云供应商以及与谷歌机器学习工作关系密切的人,获得了同样的观点。TensorFlow 已经输掉了这场战争,其中有人用了一个鲜明的比喻:「PyTorch 吃掉了 TensorFlow 的午餐。」
专家们表示,鉴于战术失误、开发决策和 Meta 在开源社区中的一系列智取策略,谷歌引领互联网机器学习未来的机会正在逐渐消失。
在 PyTorch 的阴影下,谷歌正在悄悄地开发一个机器学习框架,就是 JAX(曾是「Just After eXecution」的首字母缩写,但官方说法中不再代表任何东西),许多人将其视为 TensorFlow 的继承者。
图片
接近该项目的人士告诉 Insider,谷歌大脑和 DeepMind 在很大程度上放弃了 TensorFlow,转而使用 JAX。这为谷歌的其他部门铺平了跟随的道路,一位谷歌内部人士向 Insider 证实,JAX 现在几乎已在谷歌大脑和 DeepMind 中被全球采用。
接近谷歌机器学习工作的人士表示,最初 JAX 面临着来自内部的强烈反对,一些人认为谷歌员工已经习惯了使用 TensorFlow。尽管它可能很难用,但它一直是谷歌员工中的统一因素。他们说,JAX 方法是要简单得多,但它会改变 Google 内部构建软件的方式。
熟悉该项目的人士表示,Jax 现在有望成为未来几年所有使用机器学习的谷歌产品的支柱,就像 TensorFlow 在 2015 年之后几年所做的那样。
「JAX 是一项工程壮举,」Julia 编程语言创建者 Viral Shah 说。「我认为 JAX 是一种通过 Python 实例化的独立编程语言。如果你遵守 JAX 想要的规则,它就可以发挥它的魔力,这真是令人惊叹。」
现在,谷歌希望在这场竞赛中再次获得金牌,同时也从开发 TensorFlow 时所犯的错误中吸取教训,但这将是一个巨大的挑战。
TensorFlow 的暮光,PyTorch 的崛起
根据提供给 Insider 的数据,PyTorch 在一些必读开发者论坛上的帖子正在迅速赶超 TensorFlow。Stack Overflow 的参与度数据显示,以论坛问题份额衡量, TensorFlow 受欢迎程度近年来停滞不前,而 PyTorch 的参与度继续上升。
图片
TensorFlow 起步强劲,推出后受欢迎程度不断提高。Uber 和 Airbnb 等公司以及 NASA 等机构很快就开始将其用于一些复杂的项目,这些项目需要在大量数据集上训练算法。截至 2020 年 11 月,TensorFlow 已被下载 1.6 亿次。
但谷歌持续及增量的功能更新使得 TensorFlow 变得笨拙,且对用户不友好,即使是谷歌内部的那些人、开发人员和与项目关系密切的人都认为如此。随着机器学习领域以惊人的速度发展,谷歌不得不经常使用新工具更新其框架。接近该项目的人士表示,该项目已经在内部传播开来,越来越多的人参与其中,不再专注最初是什么让 TensorFlow 成为首选工具。
专家告诉 Insider,对于许多拥有引领者身份的公司来说,这种疯狂的猫鼠游戏是一个反复出现的问题。例如,谷歌并不是第一家建立搜索引擎的公司,它能够从 AltaVista 或 Yahoo 等前辈的错误中吸取教训。
2018 年,PyTorch 推出了完整版。虽然 TensorFlow 和 PyTorch 都建立在 Python 之上,但 Meta 在满足开源社区的需求方面投入了大量资金。熟悉 TensorFlow 项目的人士说,PyTorch 还受益于专注做一些 TensorFlow 团队错过的事情。
「我们主要使用 PyTorch,它拥有最多的社区支持,」机器学习初创公司 Hugging Face 的研究工程师 Patrick von Platten 说。「我们认为 PyTorch 可能在开源方面做得最好,他们能确保在线回复问题,所有示例都能 work。」
一些最大的组织机构开始在 PyTorch 上运行项目,包括那些曾经依赖 TensorFlow 的机构。不久之前,特斯拉、Uber 等公司就在 PyTorch 上运行了他们最艰巨的机器学习研究项目。
TensorFlow 的新增功能有时会复制使 PyTorch 流行的元素,使得 TensorFlow 对于其最初的研究人员和用户受众来说越来越臃肿。一个这样的例子是它在 2017 年增加了「敏锐执行」,这是 Python 的原生特性,使开发人员可以轻松分析和调试他们的代码。
尝试用 JAX 自救
随着 PyTorch 和 TensorFlow 之间竞争日益激烈,谷歌内部的一个小型研究团队开发了一个新框架 JAX,该框架将更容易访问张量处理单元(TPU)——一种谷歌专门为机器学习和 TensorFlow 定制的芯片。
团队研究人员 Roy Frostige、Matthew James Johnson 和 Chris Leary 在 2018 年发表了一篇名为《Compilation of machine learning software through high-level traceability》的论文,介绍了这个新框架 JAX。PyTorch 的原始作者之一 Adam Paszky 于 2020 年初全职加入 JAX 团队。
图片
论文地址:https://cs.stanford.edu/~rfrostig/pubs/jax-mlsys2018.pdf
JAX 提出了一种直接的设计来解决机器学习中最复杂的问题之一:将一个大问题的工作分散到多个芯片上。JAX 不会为不同的芯片运行单段代码,而是自动分配工作,即时访问尽可能多的 TPU,以满足运行需要。这解决了谷歌研究人员对算力的巨大需求。
PyTorch 和 TensorFlow 都是以同样的方式开始的,首先是研究项目,然后成为机器学习研究的标准化工具,从学界扩散到更多地方。
然而,JAX 在很多方面仍然依赖于其他框架。开发人员表示:JAX 没有加载数据和预处理数据的简单方法,需要使用 TensorFlow 或 PyTorch 进行大量数据处理。
JAX 基础框架 XLA 也针对谷歌 TPU 设备做了很大的优化。该框架还适用于更传统的 GPU 和 CPU。了解该项目的人称:该项目仍有办法对 GPU 和 CPU 进行优化,以达到 TPU 同等水平。
谷歌发言人表示,2018 年至 2021 年谷歌内部对 GPU 的支持策略欠优,缺乏与大型 GPU 供应商英伟达的合作,因此谷歌转而关注 TPU,谷歌自己内部的研究也主要集中在 TPU 上,导致缺乏良好的 GPU 使用反馈循环。从这个意义上说,谷歌对 TPU 的重视和专注也属迫不得已。
然而,如 Cerebras Systems 的 CEO Andrew Feldman 所说:「任何以一种设备优于另一种设备的行为都是不良做法,会遭到开源社区的抵制。没有人希望局限于单一的硬件供应商,这就是机器学习框架应运而生的原因。机器学习从业者希望确保他们的模型是可移植的,可以移植到他们选择的任何硬件上,而不是被锁定在一个平台上。」
如今,PyTorch 快 6 岁了,TensorFlow 在这个年纪早已出现衰落的迹象。也许 PyTorch 有一天也会被新框架取代,这尚未可知。但至少,新框架出现的时机已经成熟。
延庆川北小区45孙老师 东屯- 收卖废品破烂垃圾炒股 废品孙 技术更新太快了
抓紧每天学习把。。。
# MambaVision
英伟达也对 Mamba下手了 ,视觉 Transformer 与 Mamba 的完美融合 !
在ImageNet-1K数据集上的图像分类中,MambaVision模型变体在Top-1准确率和图像吞吐量方面达到了新的最先进(SOTA)性能。在MS COCO和ADE20K数据集上的下游任务,如目标检测、实例分割和语义分割中,MambaVision超越了同等大小的架构,并展示了更优的性能。
作者提出了一种新颖的混合Mamba-Transformer架构,称为MambaVision,这是专门为视觉应用量身定制的。作者的核心贡献包括重新设计Mamba公式,以增强其高效建模视觉特征的能力。此外,作者还对将视觉Transformer(ViT)与Mamba集成的可行性进行了全面的消融研究。作者的结果表明,在Mamba架构的最后几层配备几个自注意力块,大大提高了捕获长距离空间依赖关系的建模能力。基于作者的发现,作者引入了一系列具有分层架构的MambaVision模型,以满足各种设计标准。在ImageNet-1K数据集上的图像分类中,MambaVision模型变体在Top-1准确率和图像吞吐量方面达到了新的最先进(SOTA)性能。在MS COCO和ADE20K数据集上的下游任务,如目标检测、实例分割和语义分割中,MambaVision超越了同等大小的架构,并展示了更优的性能。
代码:https://github.com/NVIabs/MambaVision。
1 Introduction
在近年来,Transformers [1] 已成为包括计算机视觉、自然语言处理、语音处理和机器人技术在内的不同领域的实际架构。此外,Transformer架构的多功能性,主要归功于其注意力机制,以及它的灵活性,使其非常适合多模态学习任务,在这些任务中集成和处理来自不同模态的信息至关重要。尽管这些好处,但注意力机制相对于序列长度的二次复杂度使得Transformers在训练和部署上的计算成本很高。最近,Mamba [2] 提出了一种新的状态空间模型(SSM),该模型具有线性时间复杂度,并在不同的语言建模任务中超越或匹配Transformers [2]。Mamba的核心贡献是一种新颖的选择机制,该机制使得在考虑硬件感知的情况下,能够有效地处理依赖于输入的长序列。
图1:ImageNet-1K数据集上的Top-1准确性与图像吞吐量。 所有测量均在A100 GPU上进行,批量大小为128。MambaVision达到了新的SOTA帕累托前沿。
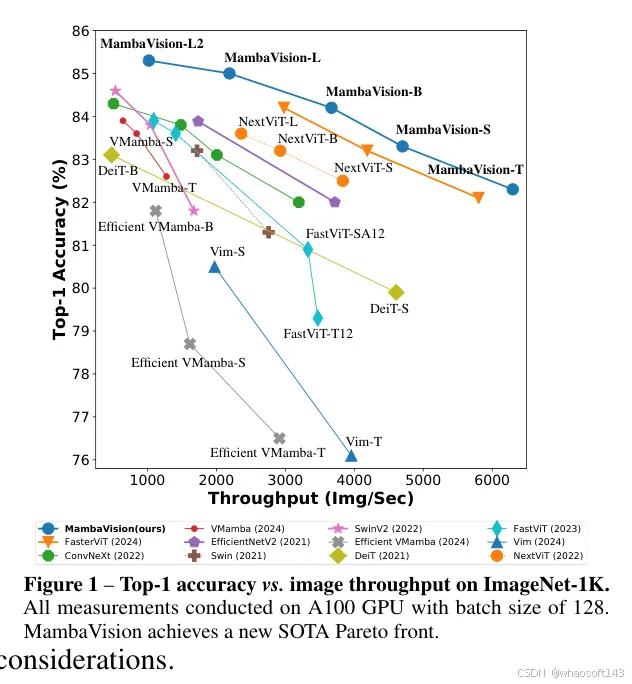
最近,还提出了几个基于Mamba的 Backbone 网[3; 4],以利用其在视觉任务中的SSM公式的优势,例如图像分类和语义分割。然而,Mamba的自回归公式虽然在需要顺序数据处理的任务中有效,但在从完整感受野中受益的计算机视觉任务中面临限制:(1)与序列数据不同,图像像素不具有相同的顺序依赖性。相反,空间关系通常是局部的,需要以更并行和综合的方式考虑。因此,这导致处理空间数据时的效率低下(2)像Mamba这样的自回归模型逐步处理数据,限制了其在一次前向传递中捕获和利用全局上下文的能力。相比之下,视觉任务通常需要理解全局上下文以对局部区域做出准确预测。
Vision Mamba (Vim) [3] 等人提出了修改措施,例如双向SSM来解决全局上下文和空间理解的不足。尽管双向SSM有潜力捕获更全面的上下文,但由于需要在做出预测之前处理整个序列,它们引入了显著的延迟。此外,复杂度的增加可能导致训练困难、过拟合的风险,并且不一定能带来更高的准确度。由于这些缺陷,带有Vision Transformer (ViT) 和卷积神经网络 (CNN) 架构的 Backbone 网在不同的视觉任务上仍然优于最佳的基于Mamba的视觉模型。
在这项工作中,作者系统地重新设计Mamba块,使其更适合视觉任务。作者提出了一种混合架构,包括作者提出的公式(即MambaVision混合器和MLP)以及Transformer块。具体来说,作者研究不同的集成模式,例如以等参数方式将Transformer块添加到早期、中期和最终层以及每隔层。作者的分析显示,在最后阶段利用几个自注意力块可以显著增强捕获全局上下文和长距离空间依赖的能力。如第5节所示,使用混合架构也比纯Mamba或基于ViT的模型在图像吞吐量方面有更好的表现。
作者引入了MambaVision模型,该模型由多分辨率架构组成,并利用基于CNN的残差块快速提取较大分辨率特征。如图1所示,MambaVision在ImageNet-1K Top-1准确性和图像吞吐量方面达到了新的SOTA帕累托前沿,超过了Mamba、CNN和基于ViT的模型,有时幅度还很大。在如下游任务目标检测和实例分割以及语义分割中,带有MambaVision Backbone 网的模型在MS COCO和ADE20数据集上分别优于同等大小的对应模型。因此,这验证了MambaVision作为有效 Backbone 网的有效性和多功能性。
据作者所知,MambaVision是首次研究和开发同时包含Mamba和Transformers的混合架构以用于计算机视觉应用。
作者在这项工作中的主要贡献总结如下:
- 作者引入了一个重新设计的面向视觉的Mamba块,提高了原始Mamba架构的准确性和图像吞吐量。
- 作者系统地调查了Mamba和Transformer块的集成模式,并证明在最后阶段整合自注意力块显著提高了模型捕获全局上下文和长距离空间依赖的能力。
- 作者介绍了MambaVision,这是一个新颖的混合Mamba Transformer模型。分层的MambaVision在ImageNet-1K数据集上实现了Top-1和图像吞吐量折衷的新SOTA帕累托前沿。
2 Related work
ViT(视觉 Transformer ): 视觉 Transformer (ViT)[5]作为一种替代CNN的有前景的选择出现,利用自注意力层提供更大的感受野。然而,最初ViT缺乏CNN的一些固有优势,例如归纳偏置和平移不变性,并且需要大规模的训练数据集才能达到有竞争力的性能。为了解决这些限制,数据高效图像 Transformer (DeiT)[6]引入了一种基于蒸馏的训练策略,显著提高了分类精度,即使是在较小的数据集上。在此基础上,LeViT[7]模型提出了一种混合方法,融入了重新设计的MLP和自注意力模块,这些模块针对快速推理进行了优化,提高了效率和性能。此外,跨协方差图像 Transformer (XCiT)[8]引入了一种转置自注意力机制,有效地建模了特征通道之间的交互,提高了模型捕捉数据中复杂模式的能力。金字塔视觉 Transformer (PVT)[9]采用了一种分层结构,在每个阶段的开始处使用块嵌入和空间尺寸减小,从而提高了计算效率。同样,Swin Transformer [10]提出了一种分层架构,其中自注意力在局部窗口内计算,这些窗口会移动以实现区域间的交互,平衡局部和全局上下文。Twins Transformer [11]具有空间可分离的自注意力,显著提高了效率。此外,焦点 Transformer (Focal Transformer)[12]利用焦点自注意力捕捉长距离空间交互的细粒度细节。
Mamba: 自从Mamba被引入以来,已经提出了许多努力来利用其在视觉应用中的能力。具体来说,Vim[3]提出使用双向SSM公式,与相同的Mamba公式相同,在这种公式中,标记在前后两个方向上处理,以捕捉更多的全局上下文并提高空间理解。然而,双向编码增加了计算负载,可能会减慢训练和推理时间。此外,有效结合来自多个方向的信息形成一个连贯的全局理解是具有挑战性的,因为在过程中可能会丢失一些全局上下文。与Vim相比,作者提出的MambaVision使用单一的前向传播和重新设计的Mamba块,可以捕捉到短距离和长距离的信息,并且在ImageNet Top-1准确性和吞吐量方面显著优于Vim。
EfficientV Mamba[4]提出了一种基于扩张的选择性扫描和跳过采样方法,以高效提取全局空间依赖关系。EfficientVLambda还使用了由SSM和基于CNN的块组成的分层架构,其中SSM用于更大的输入分辨率以更好地捕捉全局上下文,而CNN用于较低的分辨率。与EfficientV-Mamba相比,MambaVision在较高分辨率下使用CNN进行更快特征提取,同时在较低分辨率下使用SSM和自注意力捕捉短距离和长距离空间依赖关系的细粒度细节。作者提出的MambaVision在Top-1准确性和图像吞吐量方面也显著优于EfficientVMamba。
此外,V Mamba[13]引入了一种基于Mamba的通用视觉 Backbone 网络,并配备了交叉扫描模块(CSM),该模块实现了一维选择性扫描,并具有扩大的全局感受野。具体来说,CSM模块采用四向选择性扫描方法(即左上和右下向相反方向)以整合来自所有周围标记的信息并捕捉更多的全局上下文。此外,V Mamba在架构上进行了更改,如使用深度卷积和分层多分辨率结构。尽管CSM模块的设计更适合视觉任务,但其感受野仍然受到跨扫描路径的限制。与V Mamba相比,作者提出的MambaVision混合器的设计更简单,可以捕捉短距离和长距离依赖关系。MambaVision还使用基于CNN的层进行快速特征提取,而不是在所有阶段使用相同的块结构。此外,MambaVision模型在具有显著更高图像吞吐量的同时,性能也优于V Mamba对应模型。
3 Methodology
Macro Architecture

注意:表格内容在翻译中已调整为适应中文语境的顺序。公式和引用编号保持不变。
Micro Architecture
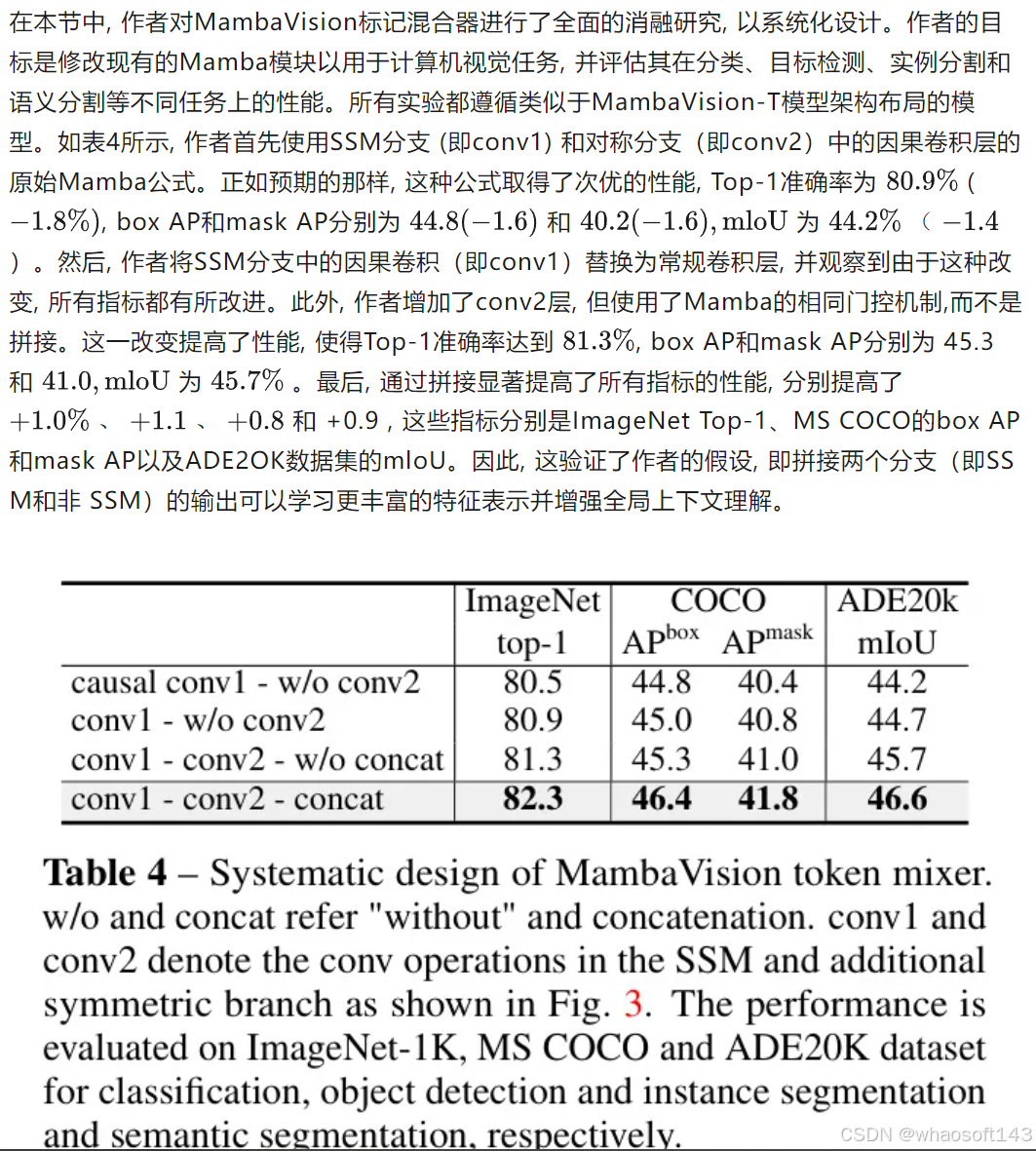
在本节中,作者首先回顾了Mamba和SSMs的基础知识。然后作者分阶段展示了第3和第4阶段的微架构设计,并详细讨论了MambaVision的公式化表述。
3.2.1 Mamba Preliminaries

然后方程式2可以用离散参数表示为:

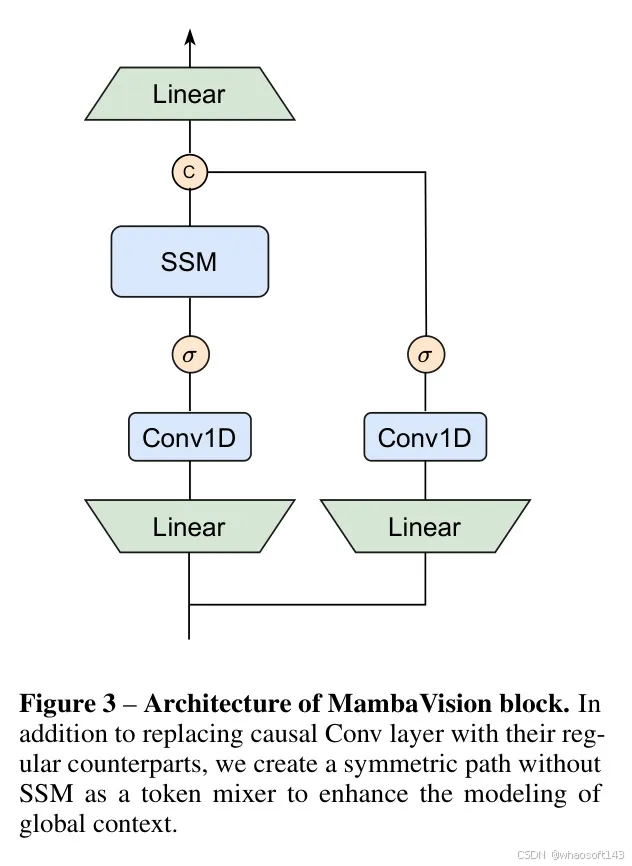
图3:MambaVision块的架构。除了用它们的常规对应物替换因果卷积层外,作者还创建了一个没有SSM的对称路径作为标记混合器,以增强全局上下文的建模。

算法1 类似PyTorch的伪代码用于MambaVision混合器

选择性Mamba通过引入选择机制进一步扩展了S4公式,该机制允许进行输入相关的序列处理。这使得模型的参数,和可以根据输入动态调整,并过滤掉不相关的信息。进一步的离散化细节在[2]中提供。
3.2.2 Layer Architecture


4 Experiments
图像分类实验是在ImageNet-1K数据集[19]上进行的。作者遵循了先前工作的标准训练方法[10; 12; 29],以便对不同模型的性能进行比较分析。具体来说,所有模型都经过300个周期的训练,使用余弦衰减调度器,并分别使用额外的20个周期进行预热和冷却阶段。此外,作者使用了LAMB优化器[30],全局批量大小为4096,初始学习率为0.005,权重衰减为0.05。作者注意到,使用LAMB优化器相比于传统的AdamW[31]可以获得更好的结果,特别是由于它对较高学习率的鲁棒性。作者在分类任务中使用了32个A100 GPU。
为了评估下游任务的性能,作者将预训练的模型作为目标检测和实例分割以及语义分割任务的 Backbone 网络,并分别使用了MS COCO数据集[32]和ADE20K数据集[33]。具体来说,对于目标检测和实例分割,作者使用了Mask-RCNN[34] Head ,并设置了如 LR计划、初始学习率为0.0001、批量大小为16、权重衰减为0.05等超参数。对于语义分割,作者使用了UperNet网络[35] Head 和Adam-W[31]优化器,初始学习率为6e-5,全局批量大小为16。作者在所有下游任务中使用了8个A100 GPU。
5 Result
Image classification
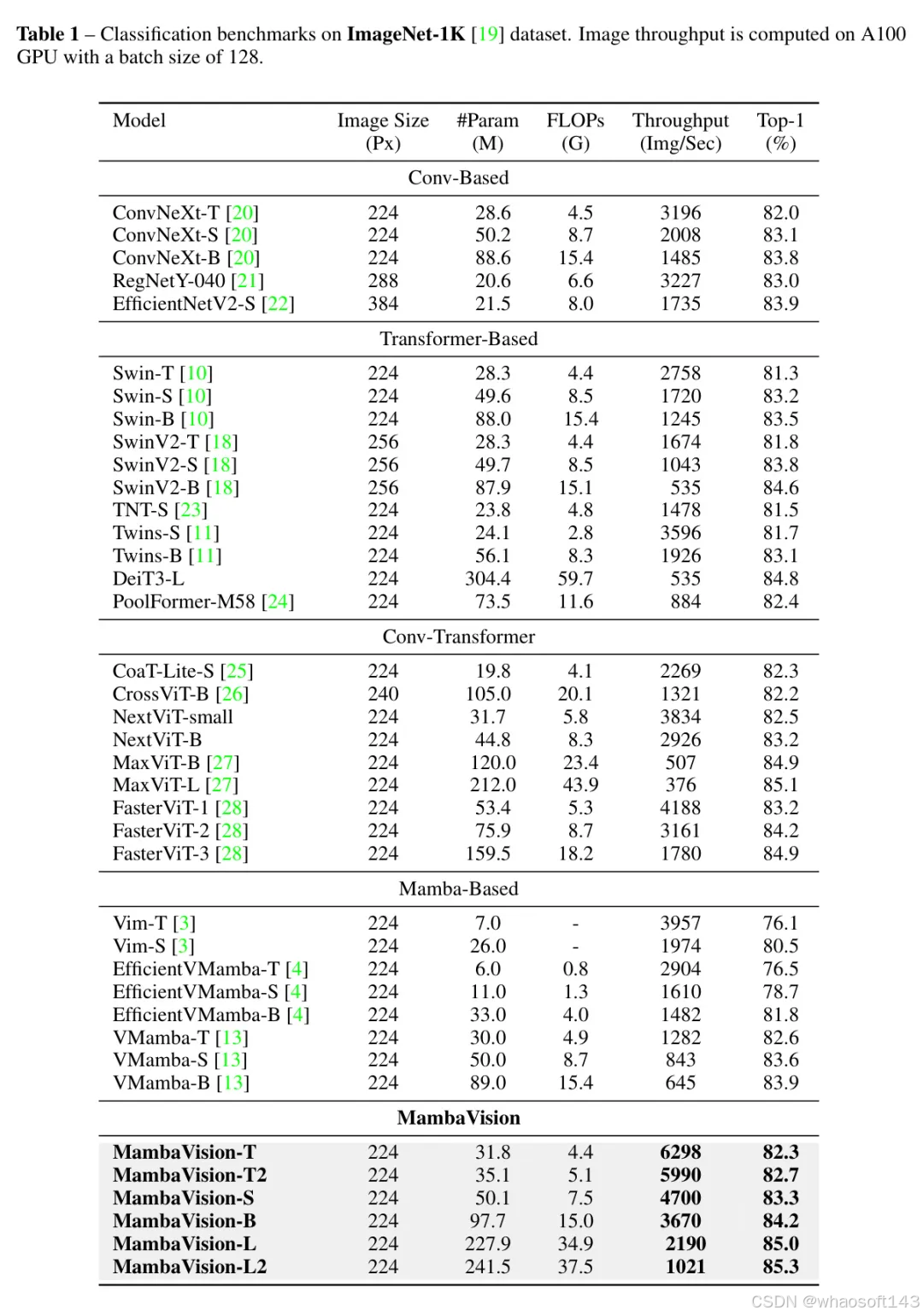
在表1中,作者展示了ImageNet-1K分类的结果。具体来说,作者与不同类型的模型家族进行了比较,如基于卷积的、基于Transformer的、卷积-Transformer混合的以及基于Mamba的模型,并展示了作者的模型在ImageNet Top-1准确率和图像吞吐量方面超过了此前的成果。例如,与流行的模型如ConvNeXt和Swin Transformers相比,MambaVision-B(84.2%)分别超过了ConvNeXt-B(83.8%)和Swin-B(83.5%),同时在图像吞吐量上也有显著优势。与基于Mamba的模型相比,作者也观察到了类似的趋势。具体来说,MambaVision-B(84.2%)尽管图像吞吐量明显更高,但性能还是超过了V Mamba-B(83.9%)。作者还想指出,虽然作者主要的设计目标是准确性与吞吐量的权衡,但MambaVision模型变体与同等大小的模型相比,FLOPs要低得多。例如,MambaVision-B的GFLOPs比MaxViT-B少了。
Object Detection and Segmentation
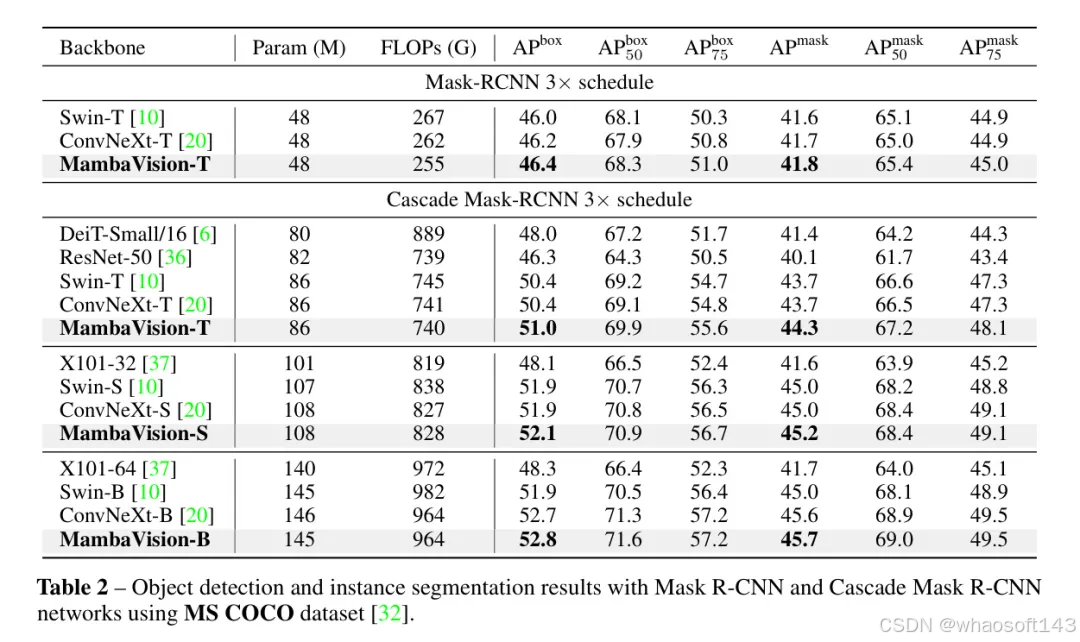
作者在表2中展示了在MS COCO数据集[32]上的目标检测和实例分割结果。特别地,作者训练了不同检测尺寸的模型,以进一步验证MambaVision在不同场景下的有效性。作者还注意到,作者的目标并非要在这些任务上达到最先进水平,而是要比较作者的主干网络与同尺寸的流行视觉主干网络的表现,并验证其有效性。使用简单的Mask-RCNN检测Head,作者预训练的MambaVision-T主干网络在box AP和mask AP方面分别达到了46.4和41.8,超过了ConvNeXt-T [20]和Swin-T [10]模型。使用级联Mask-RCNN网络,MambaVision-T、MambaVision-S和MambaVision-B均超过了竞争模型。具体来说,在box AP和mask AP方面,MambaVision模型分别比ConvNeXt-T高出+0.2和0.2,比ConvNeXt-B高出+0.1和0.1。同样,在box AP和mask AP方面,MambaVision分别比Swin-T高出+0.6和0.6,比Swin-S高出+0.1和0.2,比Swin-B高出+0.9和0.7。
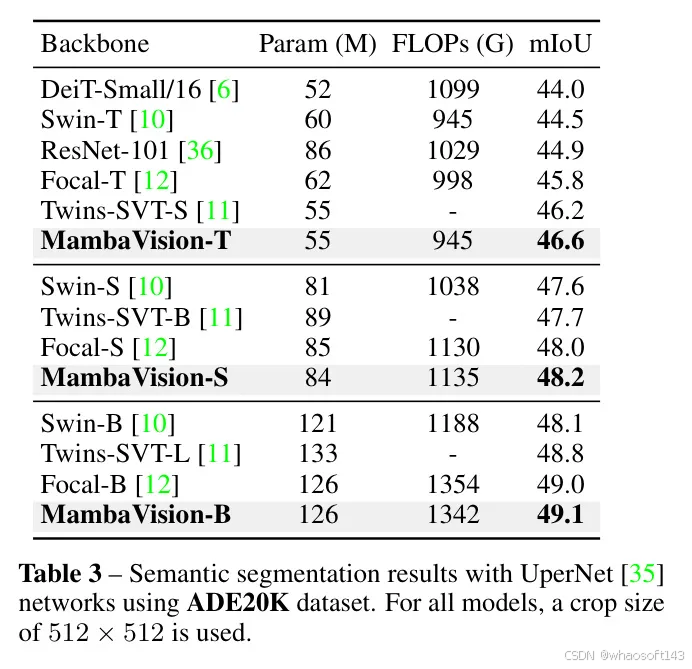
作者在表3中展示了在ADE20K数据集[33]上的语义分割基准。在这些实验中,作者使用了UPerNet [35],以便与其他模型进行比较。作者观察到,MambaVision模型在各个变体中均超过了同样尺寸的竞争模型。例如,在mIoU方面,MambaVision-T、MambaVision-S和MambaVision-B分别比Swin-T、Swin-S和Swin-B高出+0.6、+0.6和+1.0。尽管作者没有针对下游任务的超参数调整进行大量优化,但这些结果证明了MambaVision作为一个不同视觉任务的有前景的主干网络是可行的,尤其是在高分辨率设置下。
Ablation

6 Conclusion
在本文中,作者引入了MambaVision,这是首个专门为视觉应用设计的Mamba-Transformer混合骨架。
作者提出了重新设计Mamba公式的方法,以增强全局上下文表示的学习能力,并进行了混合设计集成模式的综合研究。
MambaVision在Top-1准确性和图像吞吐量方面达到了新的SOTA帕累托前沿,大幅超越了基于Transformer和Mamba的模型。
作者希望这些研究成果能够成为新型混合视觉模型的基础。
-------















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









