






来源:新智元
【导读】ICCV 2023录用结果公布了。
ICCV 2023开奖了!
近日,世界三大顶级视觉会议之一ICCV公开了最新录用结果。
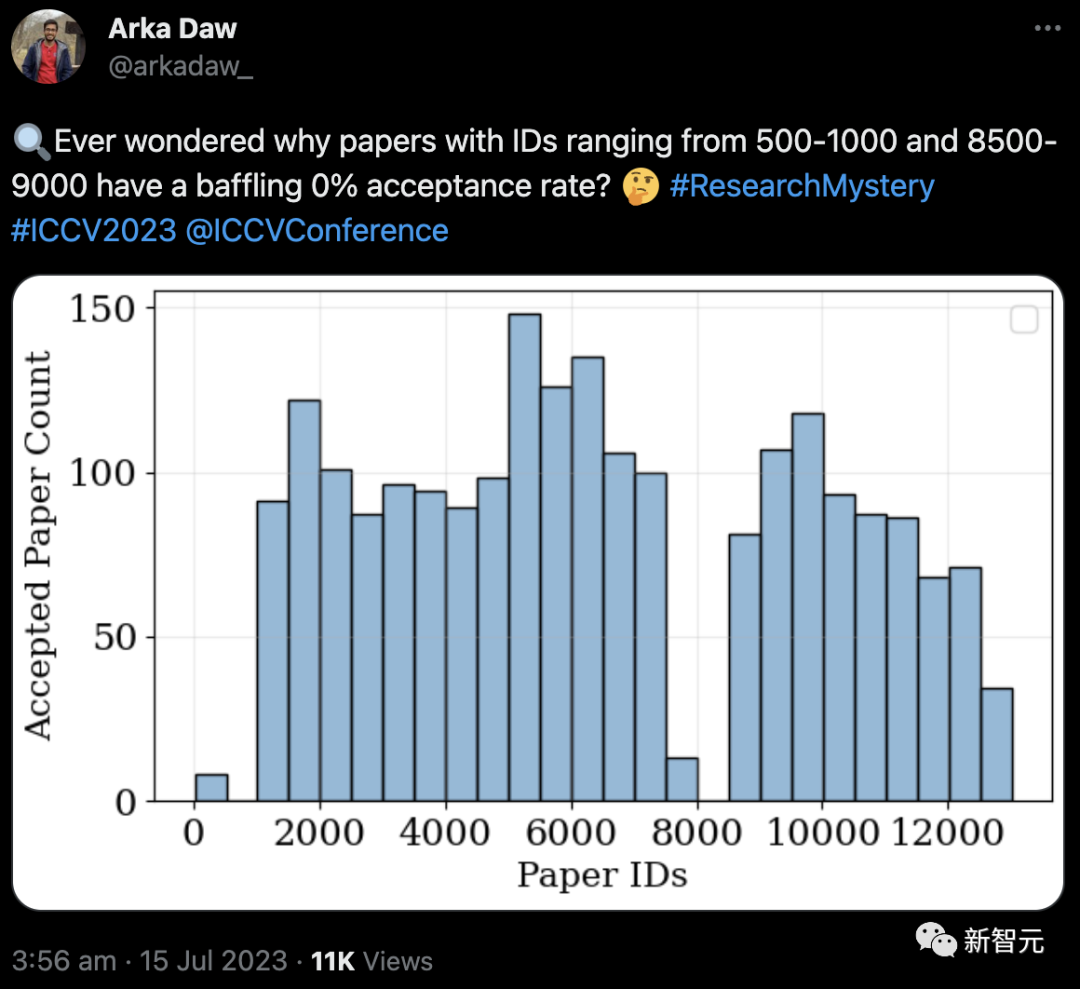
根据文件里给出的ID,总共有2160篇论文入选。
有趣的是,ID在500-1000和8500-9000之间的论文,录用率为0%。
虽然还不清楚具体的原因,不过约克大学的助理教授Kosta Derpanis指出,ID有时会被跳过。
ICCV每2年举办一次,与CVPR、ECCV并称计算机视觉三大顶级会议。
ICCV 2023是第19届国际视觉会议,将在10月2日-6日在法国巴黎举办。

都来看看今年都有哪些论文被录用了。
分割一切
Meta团队推出的图像分割基础模型「分割一切」(SAM)被ICCV 2023接收。

SAM的强大之处在于,能从照片或视频中对任意对象实现一键分割,并且能够零样本迁移到其他任务。

论文地址:https://ai.facebook.com/research/publications/segment-anything/
整体而言,SAM遵循了基础模型的思维:
1. 一种非常简单但可扩展的架构,可以处理多模态提示:文本、关键点、边界框。
2. 直观的标注流程,与模型设计紧密相连。
3. 一个数据飞轮,允许模型自举到大量未标记的图像。

值得一提的是,SAM具有广泛的通用性。
即具有了零样本迁移的能力,足以涵盖各种用例,不需要额外训练,就可以开箱即用地用于新的图像领域,无论是水下照片,还是细胞显微镜。

「扩散模型」热度不减
罗格斯大学和谷歌提出的SVDiff,为扩散模型微调提出了一个紧凑参数空间——频谱移动。

论文地址:https://arxiv.org/abs/2303.11305
扩散模型在T2P生成方面取得了显著的成功,能够从文本提示,或其他模态中创建高质量的图像。
然而,现有的定制这些模型的方法受到处理多个个性化主题和过拟合风险的限制。此外,其大量的参数对于模型的存储来说是低效的。
论文中,提出了一种新的方法来解决现有文本-图像扩散模型的这些限制,以实现个性化。
与现有的方法(vanilla DreamBooth 3.66GB,Custom Diffusion 73MB)相比,提出的SVDiff方法的模型大小明显较小(StableDiffusion为1.7MB),使其在现实世界的应用中更加实用。

Adobe和伦敦大学学院提出了用图像扩散进行视频编辑的方法:Pix2Video。

论文地址:https://arxiv.org/pdf/2303.12688.pdf
图像扩散模型支持反转真实图像和有条件的(例如文本)生成,使其成为高质量图像编辑应用程序的理想选择。
本文研究了如何利用这样的预训练图像模型,进行文本引导的视频编辑。其中的关键挑战是在「保留源视频内容的同时实现目标编辑」。
研究人员的方法通过2个简单的步骤实现:
- 使用预先训练的结构引导(如深度)图像扩散模型对锚定帧进行文本引导编辑
- 在关键步骤中,通过自注意力特征注入逐步将更改传播到未来帧,以适应扩散模型核心去噪步骤。
- 通过调整上一帧的潜在编码来巩固这些更改,并继续整个过程。
值得一提的是,该方法无需训练,适用于各种广泛的编辑。

哥伦比亚等研究团队提出了由一张图像生成三维物体的框架Zero-1-to-3,可以仅通过一张RGB图像改变物体的相机视角

论文地址:https://arxiv.org/pdf/2303.11328.pdf
研究人员为了在这种不完备的情况下执行新视角合成,因此利用了大规模扩散模型学习的有关自然图像的几何先验知识。
条件扩散模型使用合成数据集学习相对相机视角的控制,这使得可以在指定的相机变换下生成同一对象的新图像。
尽管它是在合成数据集上训练的,但该模型仍然保持了很强的零样本泛化能力,可以适应分布外的数据集以及野外图像,包括印象派绘画。
该视角条件扩散方法还可以用于从单张图像进行3D重建的任务。定性和定量实验表明,该方法通过利用互联网规模的预训练,显著优于最先进的单视角3D重建和新视角合成模型。

南洋理工大学MMLab共有20篇论文被录用。
前段时间,颠覆设计AI工具DragGAN的论文一作潘新钢加入了MMLab,出任助理教授。





UC伯克利博士、新加坡国立大学校长青年教授教授尤洋指导的论文也被ICCV 2023接收。
论文分享
阿里徐海洋称,达摩院多模态mPLUG的3篇最新工作都被ICCV 2023接收。
其中包括两篇视频文本预训练(HiTeA,TW-BERT),一篇图文预训练(BUS)。

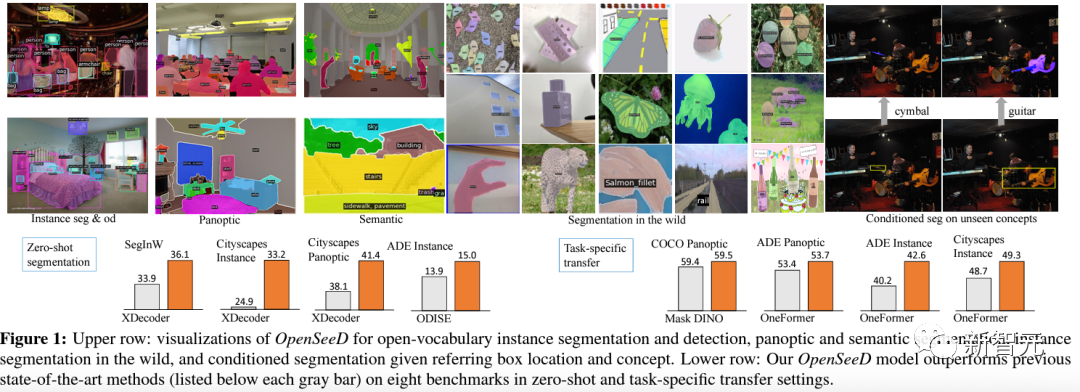
这项由香港理工大学等团队发表的论文,提出了提出了OpenSeeD,一个简单的开放词分割和检测框架,


论文地址:https://arxiv.org/pdf/2303.08131.pdf
项目地址:https://github.com/IDEA-Research/OpenSeeD
为了弥合词汇和标注颗粒度的差距,团队首先引入了一个预训练的文本编码器来编码2个任务中的所有视觉概念,并为它们学习一个公共语义空间。
作为一个强大的开放集分割方法,OpenSeeD可以分割出大量从未见过的物体,在各项指标上都取得了SOTA。而且通过引入O365检测任务来提升open-set语义能力,训练代价相对其他open-set方法较小。
东北大学等研究人提出了GlueGen,它应用了一个新提出的GlueNet模型,将来自单模态或多模态编码器的特征与现有T2I模型的潜在空间对齐。
该方法引入了一个新的训练目标,利用并行语料库来对齐不同编码器的表示空间。
实验结果表明,GlueNet可以有效地训练,并实现超越以前最先进模型的各种功能:
1)XLM-Roberta等多语言语言模型可以与现有的T2I模型对齐,允许从英语以外的字幕生成高质量图像;
2)GlueNet可以将AudioCLIP等多模态编码器与稳定扩散模型对齐,实现声音到图像的生成;
3)它还可以升级潜在扩散模型的当前文本编码器,以生成挑战性的案例。
通过各种特征表示的对齐,GlueNet允许将新功能灵活高效地集成到现有的T2I模型中,并阐明X到图像(X2I)生成。

论文地址:https://arxiv.org/pdf/2303.10056
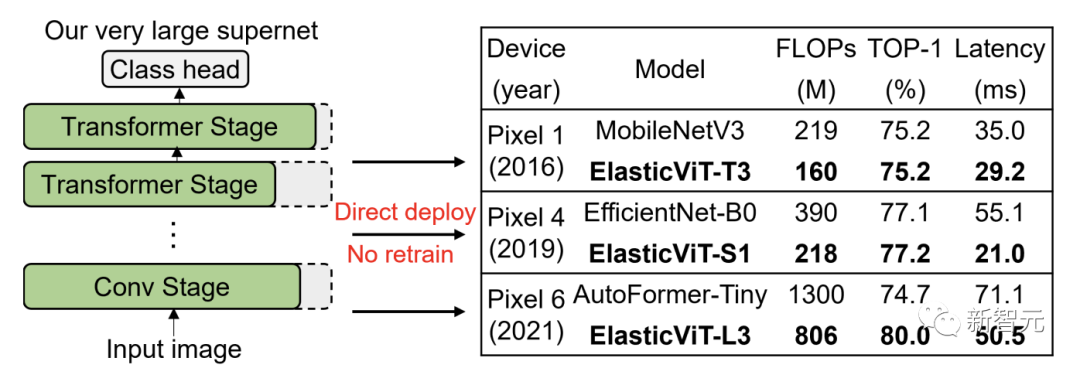
清华和微软提出了ElasticViT。
首先在一个非常大的搜索空间内训练一个高质量的ViT超网络,该搜索空间支持各种移动设备,然后搜索一个最优子网络(子网)进行直接部署。
然而,依赖均匀采样的先前超网络训练方法会遇到梯度冲突问题:采样的子网可能会有极大的模型大小差异(例如,50M vs. 2G FLOPs),导致优化方向的不同和性能的下降。
为了应对这个挑战,研究人员提出了2种新颖的采样技术:「复杂度感知采样」和「性能感知采样」。
复杂度感知采样限制了在相邻训练步骤中采样的子网之间的FLOPs差异,同时覆盖了搜索空间中不同大小的子网。
性能感知采样进一步选择了具有良好准确性的子网,这可以减少梯度冲突并提高超网络质量。

论文地址:https://arxiv.org/pdf/2303.09730.pdf
结果发现ElasticViT模型,在60M-800M FLOPs的范围内,ImageNet上的top-1准确率从67.2%提高到80.0%,
无需额外的再训练,超过了所有先前的CNNs和ViTs在准确性和延迟上的表现。
上海AI实验室和商汤提出的3DHumanGAN,一个具有三维感知能力的生成对抗网络,可以合成在不同视角和身体姿势下具有一致外观的全身人体图像。

论文地址:https://arxiv.org/pdf/2212.07378.pdf
为了解决合成人体关节结构的表征和计算挑战,研究人员提出了一种新颖的生成器架构,其中二维卷积骨干网络被三维姿态映射网络调节。
这个三维姿态映射网络被设计成一个可渲染的隐式函数,其条件是一个具有姿态的三维人体网格。

今年的ICCV,你中了吗?
参考资料:
https://www.zhihu.com/question/602507329
https://twitter.com/ICCVConference/status/1679718755390160896

分享
收藏
点赞
在看














 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









