






本文翻译整理自:
https://pub.towardsai.net/want-to-learn-quantization-in-the-large-language-model-57f062d2ec17
简单介绍下大模型的为什么需要量化,以及量化的基本操作。
首先,了解量化的是什么以及为什么需要它。
接下来,深入学习如何进行量化,并通过一些简单的数学推导来理解。
最后编写一些PyTorch 代码,以对 LLM 权重参数进行量化和反量化。
Let’s unpack all one by one together.
什么是量化,为什么需要它?
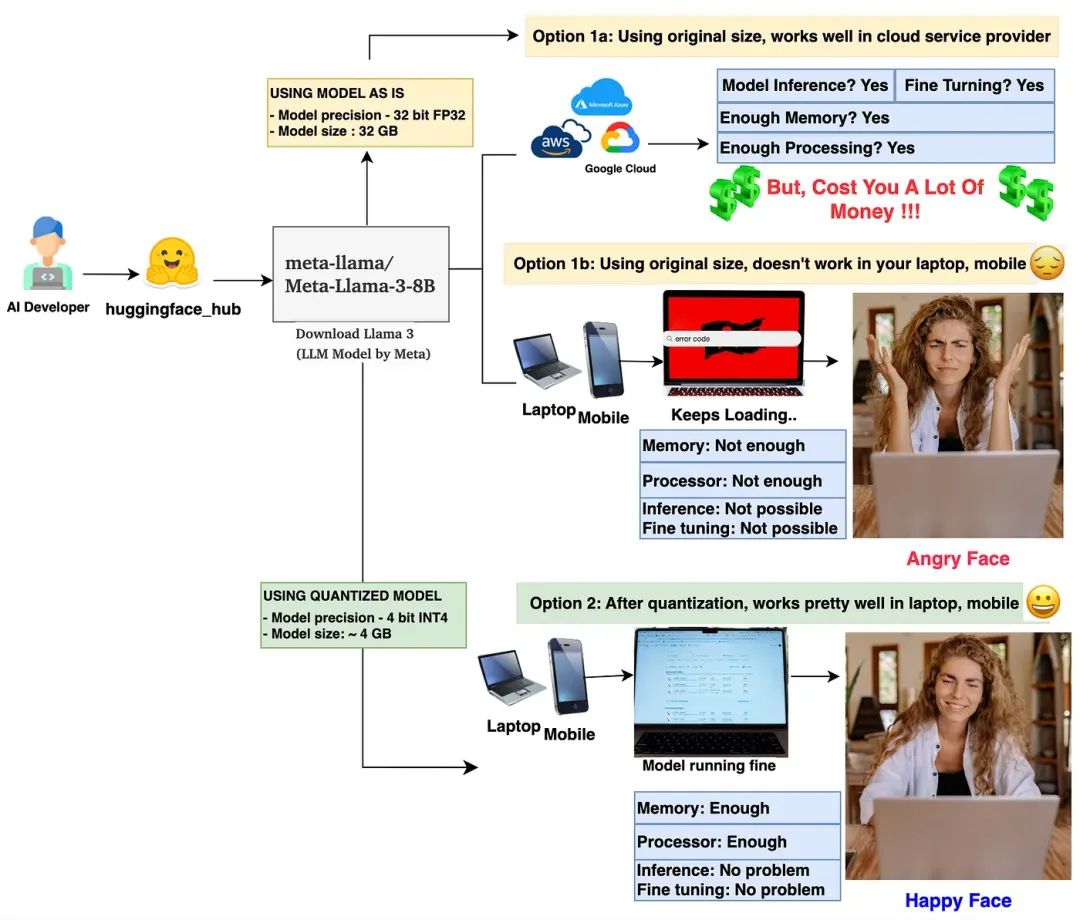
量化是一种将较大尺寸的模型(如 LLM 或任何深度学习模型)压缩为较小尺寸的方法。量化主要涉及对模型的权重参数和激活值进行量化。让我们通过一个简单的模型大小计算来验证这个说法。
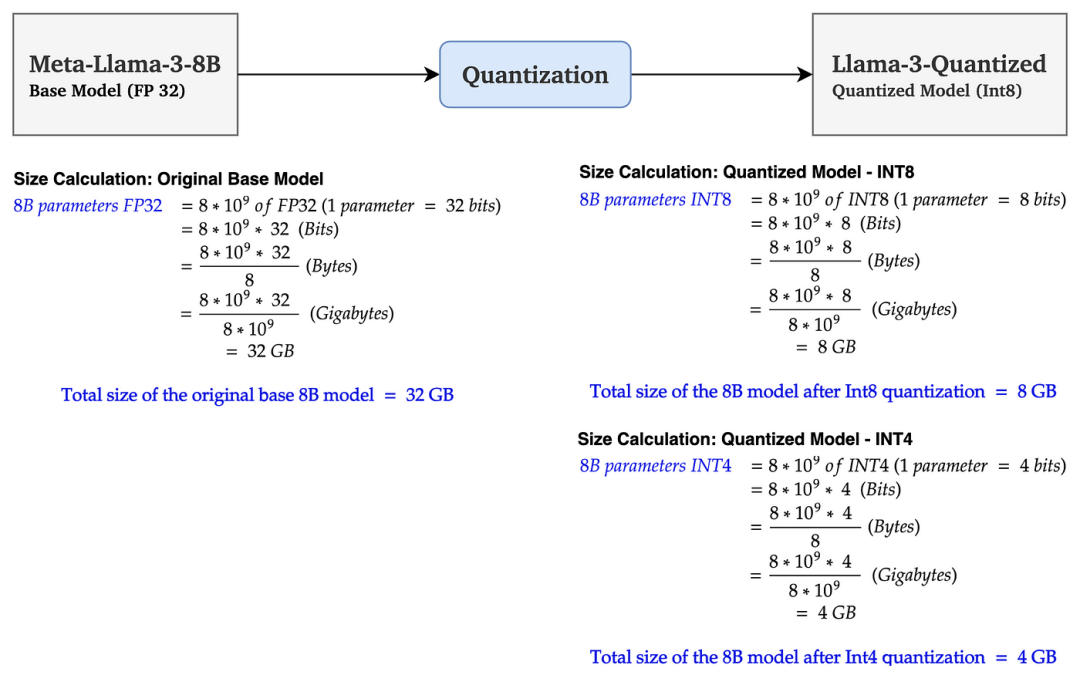
在上图中,基础模型 Llama 3 8B 的大小为 32 GB。经过 Int8 量化后,大小减少到 8GB(减少了 75%)。使用 Int4 量化后,大小进一步减少到 4GB(减少约 90%)。这使模型大小大幅减少。
这么算,7B的大模型FP16部署权重14G,INT8是8G,INT4再砍半是4G
量化两大作用:
降低显存需要
提升推理性能
不仅有助于在有限硬件资源上部署更大的模型,还能加快模型的推理速度,对精度的折损还比较OK,不用白不用。
量化是如何工作的?简单的数学推导
从技术上讲,量化将模型的权重值从较高精度(如 FP32)映射到较低精度(如 FP16、BF16、INT8)。虽然有许多量化方法可供选择,但在本文中,我们将学习其中一种广泛使用的量化方法,称为线性量化方法。线性量化有两种模式:A. 非对称量化和B. 对称量化。我们将逐一学习这两种方法。
A. 非对称线性量化: 非对称量化方法将原始张量范围(Wmin, Wmax)中的值映射到量化张量范围(Qmin, Qmax)中的值。
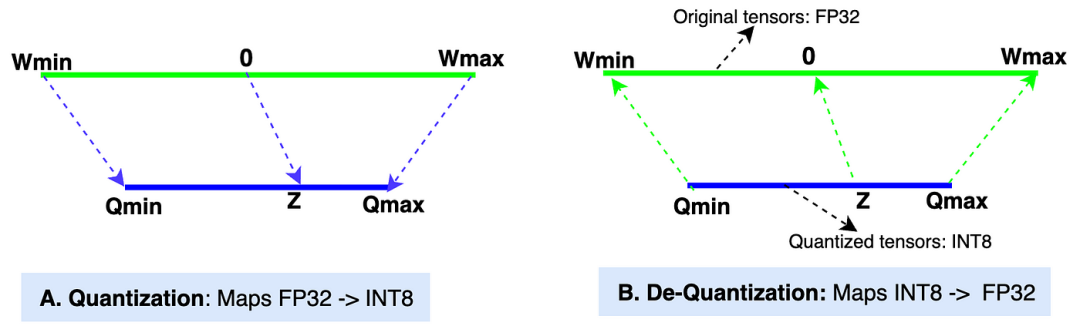
Wmin, Wmax: 原始张量的最小值和最大值(数据类型:FP32,32 位浮点)。在大多数现代 LLM 中,权重张量的默认数据类型是 FP32。
Qmin, Qmax: 量化张量的最小值和最大值(数据类型:INT8,8 位整数)。我们也可以选择其他数据类型,如 INT4、INT8、FP16 和 BF16 来进行量化。我们将在示例中使用 INT8。
缩放值(S): 在量化过程中,缩放值将原始张量的值缩小以获得量化后的张量。在反量化过程中,它将量化后的张量值放大以获得反量化值。缩放值的数据类型与原始张量相同,为 FP32。
零点(Z): 零点是量化张量范围中的一个非零值,它直接映射到原始张量范围中的值 0。零点的数据类型为 INT8,因为它位于量化张量范围内。
量化: 图中的“A”部分展示了量化过程,即 [Wmin, Wmax] -> [Qmin, Qmax] 的映射。
反量化: 图中的“B”部分展示了反量化过程,即 [Qmin, Qmax] -> [Wmin, Wmax] 的映射。
那么,我们如何从原始张量值导出量化后的张量值呢? 这其实很简单。如果你还记得高中数学,你可以很容易理解下面的推导过程。让我们一步步来(建议在推导公式时参考上面的图表,以便更清晰地理解)。


细节1:如果Z值超出范围怎么办?解决方案:使用简单的if-else逻辑将Z值调整为Qmin,如果Z值小于Qmin;若Z值大于Qmax,则调整为Qmax。这个方法在图4的图A中有详细描述。
细节2:如果Q值超出范围怎么办?解决方案:在PyTorch中,有一个名为 clamp 的函数,它可以将值调整到特定范围内(在我们的示例中为-128到127)。因此,clamp函数会将Q值调整为Qmin如果它低于Qmin,将Q值调整为Qmax如果它高于Qmax。
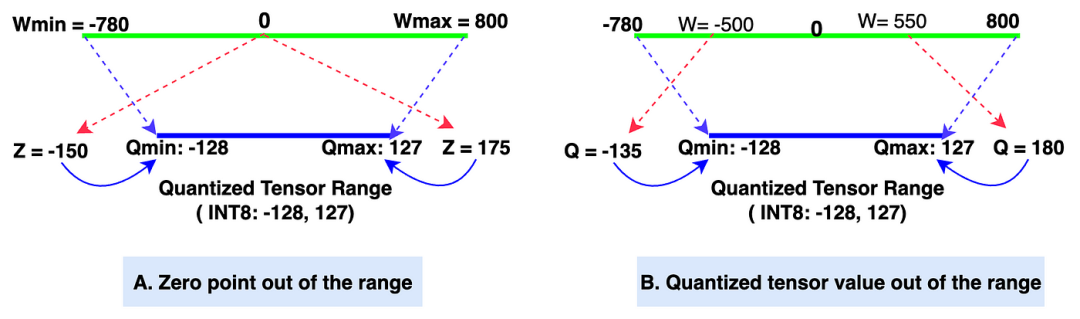
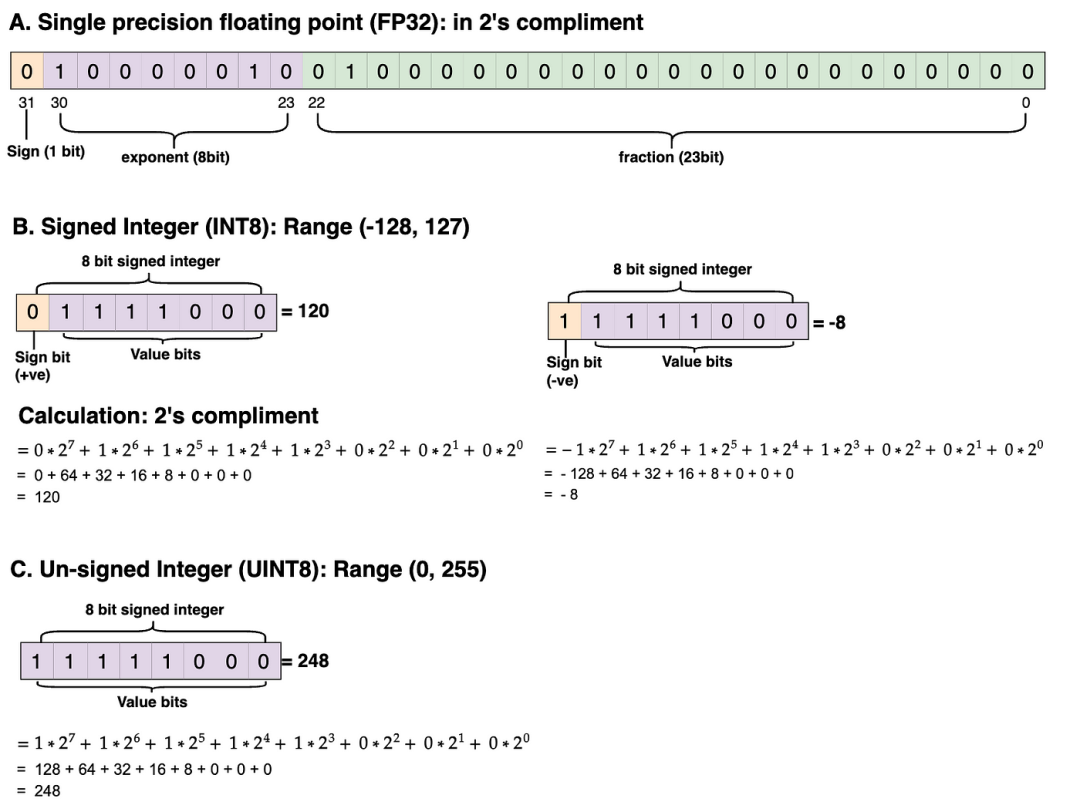
量化张量值的范围为-128到127(INT8,带符号整数数据类型)。如果量化张量值的数据类型为UINT8(无符号整数),则范围为0到255。
B. 对称线性量化: 在对称方法中,原始张量范围内的零点映射到量化张量范围内的零点。因此,这被称为对称量化。由于零在两侧范围内均映射为零,对称量化中不存在零点(Z)。整体映射发生在原始张量范围的 (-Wmax, Wmax) 和量化张量范围的 (-Qmax, Qmax) 之间。下图展示了量化和反量化情况下的对称映射。
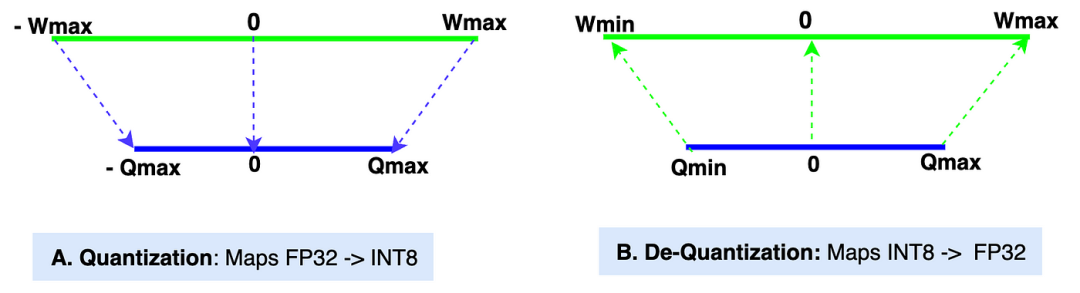
由于我们在非对称段中已经定义了所有参数,这里也适用。让我们进入对称量化的数学推导。

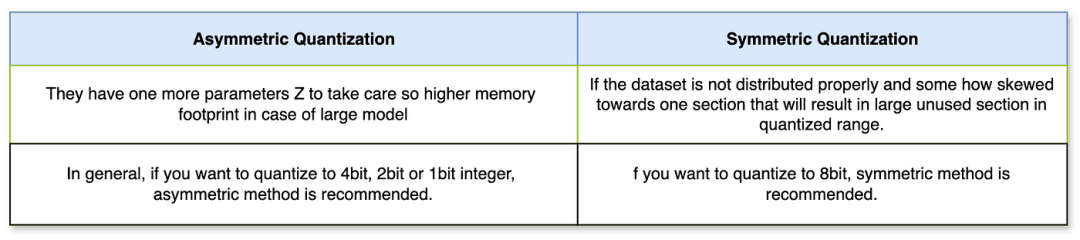
非对称量化和对称量化之间的区别:
现在你已经了解了线性量化的什么、为什么和如何,这将引导我们进入本文的最后部分,即代码部分。
LLM权重参数进行量化和反量化
量化作用于模型的权重、参数和激活值。
为了简化,我们将在Pytorch示例中仅对权重参数进行量化。先快速浏览一下量化后Transformer模型中权重参数值的变化。
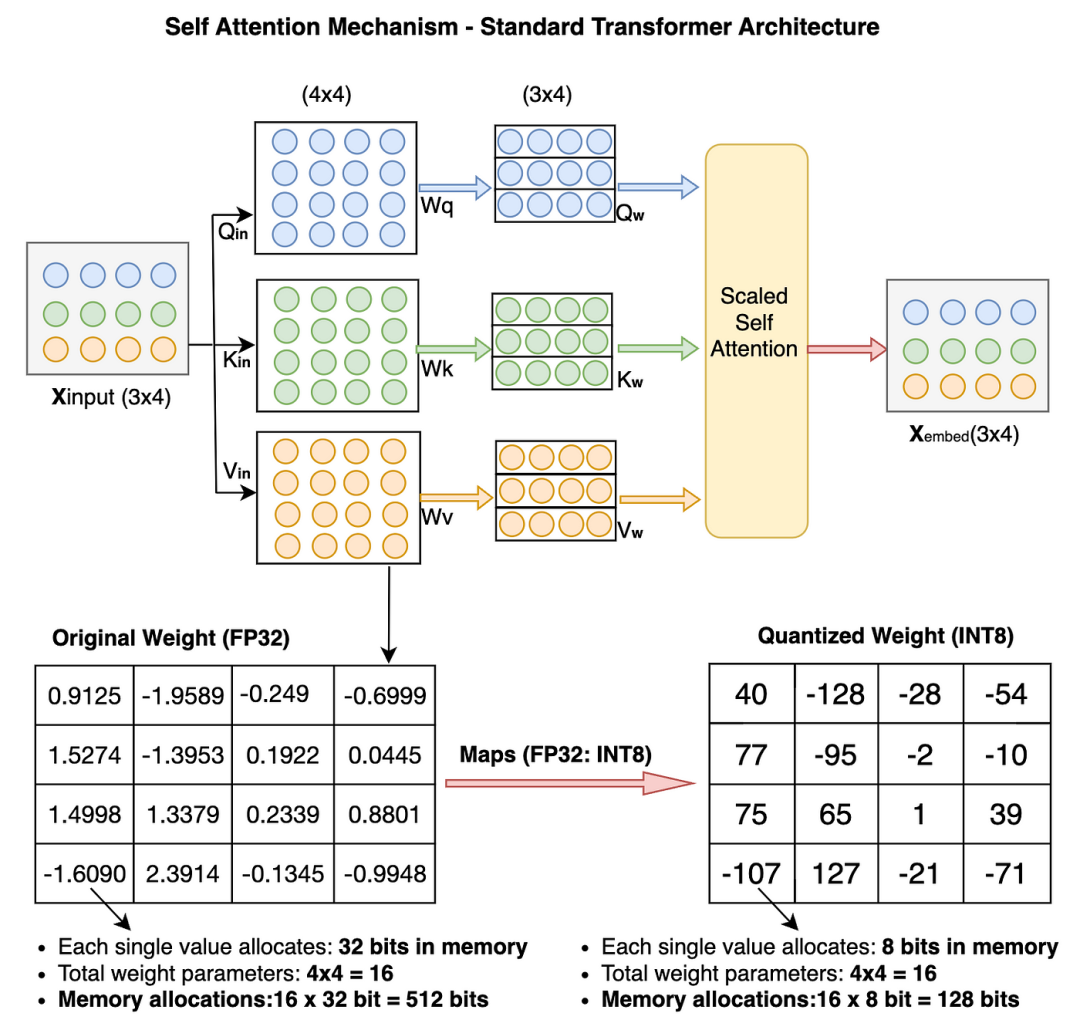
我们对16个原始权重参数从FP32到INT8进行了量化,内存占用从512位减少到128位(减少了25%)。对于大模型来说,减少幅度会更显著。
下面,你可以看到数据类型(如FP32、带符号的INT8和无符号的UINT8)在实际内存中的分布。我已经在2的补码中进行了实际计算。欢迎你自己练习计算并验证结果。
非对称量化代码:让我们一步步编写代码。
我们首先将随机值赋给原始权重张量(大小:4x4,数据类型:FP32)
# !pip install torch; 安装torch库,如果你还没有安装的话
# 导入torch库
import torch
original_weight = torch.randn((4,4))
print(original_weight)
定义两个函数,一个用于量化,另一个用于反量化
def asymmetric_quantization(original_weight):
# 定义你想要量化的数据类型。在我们的示例中,是INT8。
quantized_data_type = torch.int8
# 从原始的FP32权重中获取Wmax和Wmin值。
Wmax = original_weight.max().item()
Wmin = original_weight.min().item()
# 从量化数据类型中获取Qmax和Qmin值。
Qmax = torch.iinfo(quantized_data_type).max
Qmin = torch.iinfo(quantized_data_type).min
# 使用缩放公式计算缩放值。数据类型 - FP32。
# 如果你想了解公式的推导过程,请参考本文的数学部分。
S = (Wmax - Wmin)/(Qmax - Qmin)
# 使用零点公式计算零点值。数据类型 - INT8。
# 如果你想了解公式的推导过程,请参考本文的数学部分。
Z = Qmin - (Wmin/S)
# 检查Z值是否超出范围。
if Z < Qmin:
Z = Qmin
elif Z > Qmax:
Z = Qmax
else:
# 零点的数据类型应与量化后的值相同,为INT8。
Z = int(round(Z))
# 我们有了original_weight、scale和zero_point,现在我们可以使用数学部分推导出的公式计算量化后的权重。
quantized_weight = (original_weight/S) + Z
# 我们还将对其进行四舍五入,并使用torch clamp函数,确保量化后的权重不会超出范围,并保持在Qmin和Qmax之间。
quantized_weight = torch.clamp(torch.round(quantized_weight), Qmin, Qmax)
# 最后,将数据类型转换为INT8。
quantized_weight = quantized_weight.to(quantized_data_type)
# 返回最终的量化权重。
return quantized_weight, S, Z
def asymmetric_dequantization(quantized_weight, scale, zero_point):
# 使用本文数学部分推导出的反量化计算公式。
# 还要确保将量化后的权重转换为浮点型,因为两个INT8值(quantized_weight和zero_point)之间的减法会产生不期望的结果。
dequantized_weight = scale * (quantized_weight.to(torch.float32) - zero_point)
return dequantized_weight我们将通过调用 asymmetric_quantization 函数来计算量化后的权重、缩放值和零点。你可以在下面的截图中看到输出结果,注意量化后的权重数据类型为int8,缩放值为FP32,零点为INT8。
quantized_weight, scale, zero_point = asymmetric_quantization(original_weight)
print(f'quantized weight: {quantized_weight}')
print('\n')
print(f'scale: {scale}')
print('\n')
print(f'zero point: {zero_point}')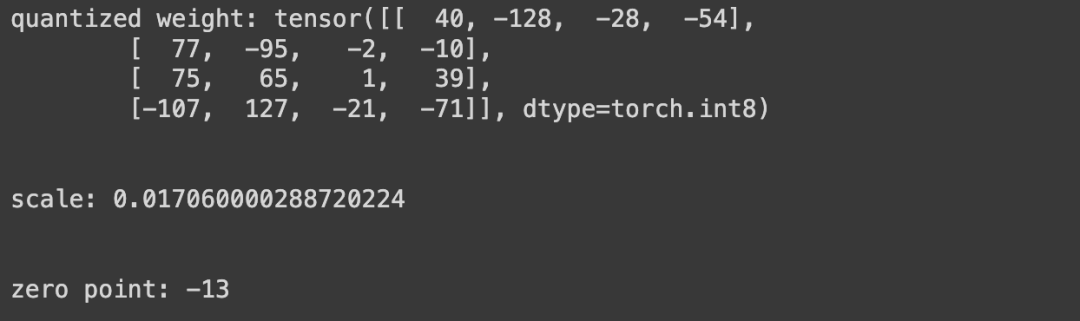
现在我们已经有了量化权重、缩放值和零点的所有值。 让我们通过调用 asymmetric_dequantization 函数来获得反量化后的权重值。注意反量化后的权重值为FP32。
dequantized_weight = asymmetric_dequantization(quantized_weight, scale, zero_point)
print(dequantized_weight)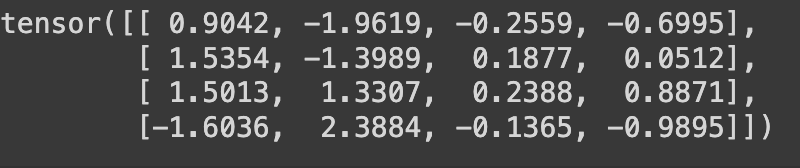
让我们通过计算它们之间的量化误差,找出最终反量化后的权重值与原始权重张量相比的准确性。
quantization_error = (dequantized_weight - original_weight).square().mean()
print(quantization_error)
对称量化和非对称的差不多,唯一需要更改的地方是在对称方法中,始终确保 zero_input 的值为 0。这是因为在对称量化中,zero_input 值始终映射到原始权重张量中的 0 值。
上述的量化代码代码示例:
https://github.com/tamangmilan/llm_quantization/blob/main/llm_quantization_part_1.ipynb
——The End——

分享
收藏
点赞
在看















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









