






来源:Kimi开放平台
今天,全新多模态图片理解模型 moonshot-v1-vision-preview 正式发布,本模型完善了 moonshot-v1 模型系列的多模态能力,助力 Kimi 更好地理解世界。
注:下文简称为 Vision 模型。
模型能力说明
图像识别
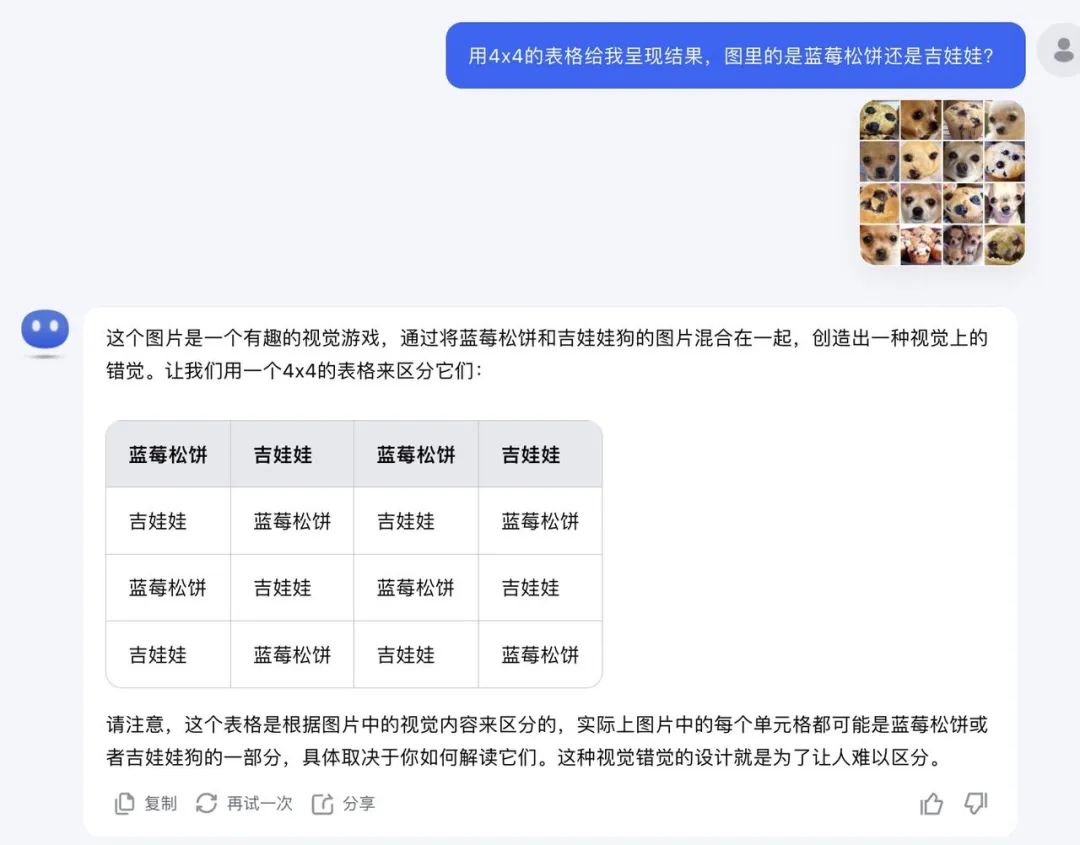
Vision 模型具备较强的图像识别能力,能够准确识别出图像中的复杂细节和细微的差别,无论是食物还是动物,能够区分出相似但又不相同的对象。下图示例中,我们拼凑了16张相似的人眼较难区分的蓝莓松饼和吉娃娃图片,由 Vision 模型来识别并按顺序标记图片类型,无论是蓝莓松饼还是吉娃娃,我们的模型都能精确地区分和识别。
文字识别和理解
Vision 模型具备国内领先的高级图像识别能力,在 OCR 文字识别和图像理解场景中表现优异。比普通的文件扫描和 OCR 识别软件更加准确,例如收据单/快递单等潦草的手写内容都可以准确识别。

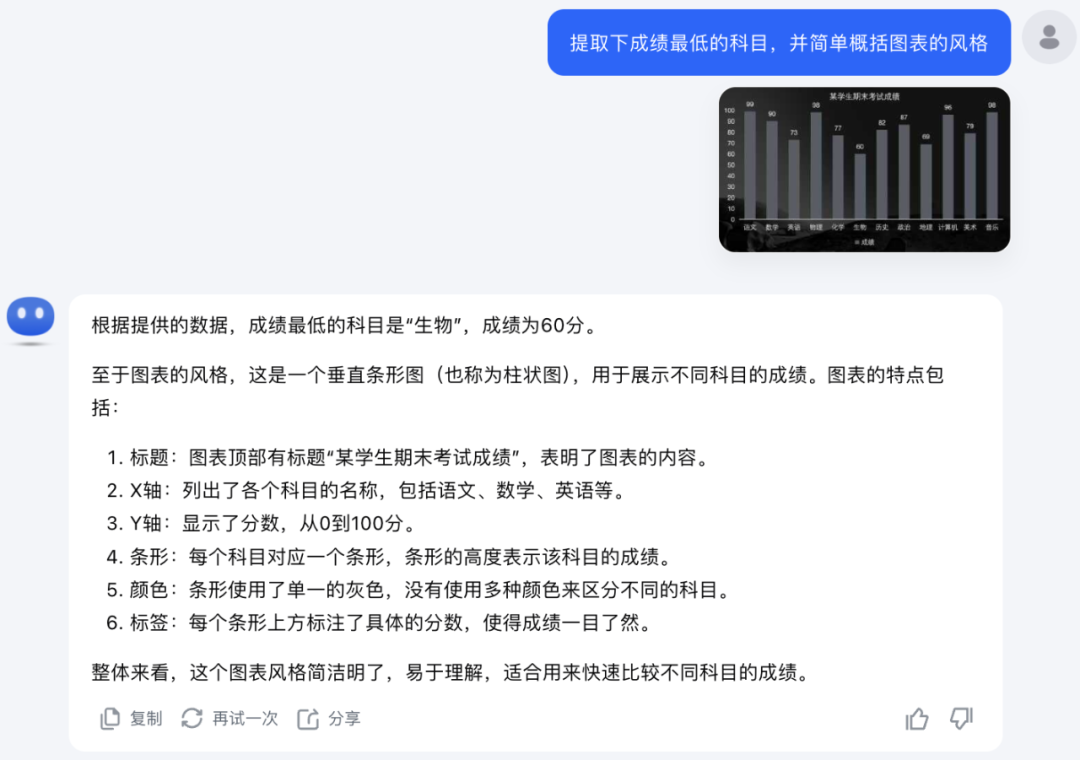
以这张《某学生期末考试成绩》柱状图为例,我们让模型提取分析考试成绩,并从美学风格的角度分析一下该柱状图。Vision 模型也能够精准地识别出柱状图中每个科目名称对应的分数数值并做分数对比,同时可以识别出该柱状图的样式格式和颜色等。
API 调用示例
我们以《某学生期末考试成绩》分析为例,提供以下 API 调用示例:
Example request
import os
import base64
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("MOONSHOT_API_KEY"),
base_url="https://api.moonshot.cn/v1",
)
image_path = "math.webp"
with open(image_path, "rb") as f:
image_data = f.read()
# 我们使用标准库 base64.b64encode 函数将图片编码成 base64 格式的 image_url
image_url = f"data:image/{os.path.splitext(image_path)[1]};base64,{base64.b64encode(image_data).decode('utf-8')}"
completion = client.chat.completions.create(
model="moonshot-v1-8k-vision-preview",
messages=[
{"role": "system", "content": "你是 Kimi。"},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
{
"type": "text",
"text": "请你提取图片中的信息,并告诉我考试成绩最低的一门科目是哪个。同时从美学的角度评价一下这个柱状图的背景和配色。",
},
],
},
],
)
print(completion.choices[0].message.content)Response
根据图片中的信息,以下是各科目的考试成绩:
```json
[
{"subject": "语文", "scores": "99"},
{"subject": "数学", "scores": "90"},
{"subject": "英语", "scores": "73"},
{"subject": "物理", "scores": "98"},
{"subject": "化学", "scores": "77"},
{"subject": "生物", "scores": "60"},
{"subject": "历史", "scores": "82"},
{"subject": "政治", "scores": "87"},
{"subject": "地理", "scores": "69"},
{"subject": "计算机", "scores": "96"},
{"subject": "美术", "scores": "79"},
{"subject": "音乐", "scores": "98"}
]
```
考试成绩最低的一门科目是生物,分数为60。
从美学角度来看:
1. **背景**:背景较为简单,使用了深色,这使得柱状图的灰色柱体更加突出,便于观察数据。不过,背景中有一些模糊的图案,可能会稍微分散注意力。
2. **配色**:柱状图使用了单一的灰色,这种配色简洁明了,能够清晰地展示数据。然而,缺乏色彩的变化可能会让图表显得有些单调。可以考虑使用不同颜色来区分不同的科目,以增加视觉吸引力。
3. **布局**:整体布局清晰,科目名称和分数都标注得很清楚,便于阅读和理解。
4. **对比度**:柱状图的灰色与背景的深色形成了良好的对比,使得数据易于辨识。
总体来说,这个柱状图在信息传达上是有效的,但在视觉吸引力上可以进一步优化。模型计费
Vision 模型实行按量计费方式,单张图片按 1024 tokens 合并计算在 Input 请求的 tokens 用量中,模型调用的价格根据选择的模型不同具体区分如下,具体说明详见计费说明 调用说明
| 模型 | 计费单位 | 价格 |
| moonshot-v1-8k-vision-preview | 1M tokens | ¥12.00 |
| moonshot-v1-32k-vision-preview | 1M tokens | ¥24.00 |
| moonshot-v1-128k-vision-preview | 1M tokens | ¥60.00 |
模型限制说明
Vision 视觉模型支持的特性包括:
多轮对话
流式输出
工具调用
JSON Mode
Partial Mode
以下功能暂未支持或部分支持
联网搜索:不支持
Context Caching:不支持创建带有图片内容的 Context Cache,但支持使用已经创建成功的 Cache 调用 Vision 模型
URL 格式的图片:不支持,目前仅支持使用 base64 编码的图片内容
其他平台更新
支持组织项目管理功能
支持一个企业实体认证多账号
增加 File 文件资源管理功能:直观管理查看文件资源
优化资源管理列表鼠标悬浮复制
Context Caching 功能已放开给全量用户
Cache 续期不再收取创建的费用
 ·················END·················
·················END·················
分享
收藏
点赞
在看

















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









