






ResNet论文笔记
引言
-
卷积神经网络的深度对卷积网络的性能非常重要,因此提出一个问题:
Is learning better networks as easy as stacking more layers?
仅仅依靠堆叠深度来提升提升网络性能?
-
结果当然是否定的,梯度消失/爆炸这个问题从一开始就阻碍了收敛。
一个小于1或一个大于1的数字在经过150层的指数叠加就会变得很大或者很小,我们自己手算一下也能算出来,0.8的150次方大约是2.9 x 10-15 ,1.2的150次方大约是7.5 x 1011.
而参数 θ \theta θ:
θ = θ − λ ∂ f ∂ θ \theta = \theta - \lambda \frac{{\partial f}}{{\partial \theta }} θ=θ−λ∂θ∂f
λ \lambda λ为学习率,过大则越过局部极小值,过小则停滞不动 -
这个过程已经通过标准化(normalization) 、和中间标准化层( Batch normalization )解决
-
为什么可以解决梯度消失的问题?
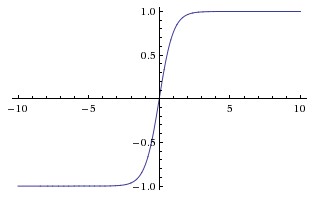
BatchNormal思想: 对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题
Normal思想: 对于输入,将其输入分布拉到均值为0方差为1的分布上
-
这使得数十层的网络能通过具有反向传播的**随机梯度下降(SGD)**开始收敛
-
-
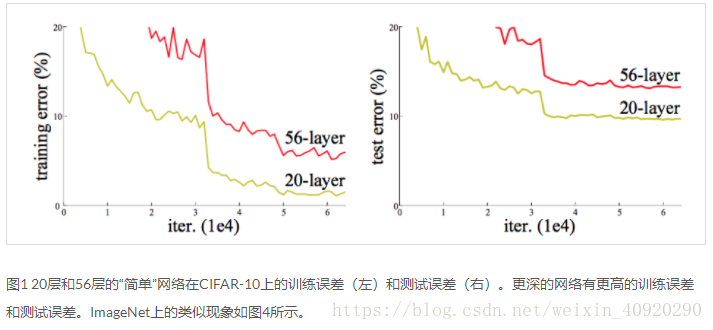
当更深的网络能够开始收敛时,暴露了一个退化问题
-
随着网络深度的增加,准确率达到饱和(不在上升),反而下降
-
意外的是,这种下降不是由过拟合引起的,并且在适当的深度模型上添加更多的层会导致更高的训练误差
-
-
引入深度残差学习框架解决了退化问题
-
定义:
残差: 残差在数理统计中是指实际观察值与估计值(拟合值)之间的差
-
传统的平网络:
- 一层的网络的数据来源只能是前一层网络,就像上图这样,数据一层一层向下流。对于卷积神经网络来说,每一层在通过卷积核后都会产生一种类似有损压缩的效果,可想而知在有损压缩到一定程度以后,分不清楚原本清晰可辨的两张照片并不是什么意外的事情。
- 实际在工程上我们称之为降采样(Downsampling)——就是在向量通过网络的过程中经过一些滤波器(filters)的处理,产生的效果就是让输入向量在通过降采样处理后具有更小的尺寸,在卷积网络中常见的就是卷积层和池化层,这两者都可以充当降采样的功能属性。主要目的是为了避免过拟合,以及有一定的减少运算量的副作用。
-
残差神经网络:
我们让这些层拟合残差映射,而不是每几个堆叠的层直接拟合期望的基础映射.
-
期望的基础映射: H ( x ) H\left( x \right) H(x),也就是最后的输出;
-
我们不用将堆叠的非线性层去拟合基础映射(H(X)),二是将堆叠的非线性层拟合另一个映射(残差映射F(X)),
F ( x ) : = H ( x ) − x ( 残 差 映 射 = 期 望 的 基 础 映 射 − 原 来 的 X ) F\left( x \right): = H\left( x \right) - x (残差映射=期望的基础映射-原来的X) F(x):=H(x)−x(残差映射=期望的基础映射−原来的X)
将期望的基础映射重写:
H ( x ) : = F ( x ) + x H(x): = F(x) + x H(x):=F(x)+x -
假设残差映射F(X)比原始的、未参考的映射更容易优化,最后我们得到了该结构的基础映射(H(x))
-
我们通过以下这个结构实现
-
-
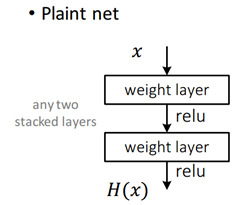
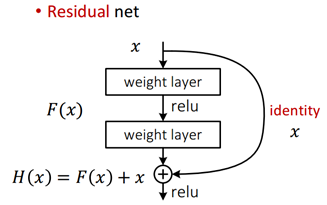
网络主要结构

为什么梯度不会消失
正向传播数学推导
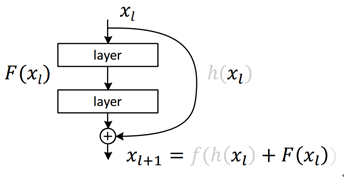
这种短路层引入后会有一种有趣的现象,就是会产生一个非常平滑的正向传递过程。我们看xl+1和其前面一层xl的关系是纯粹一个线性叠加的关系。如果进一步推导xl+2及其以后层的输出会发现展开后是这样一个表达式:
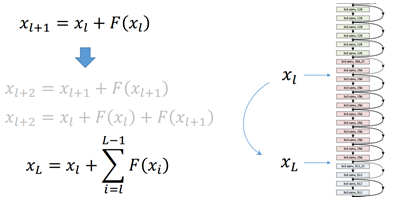
后面一层的输出是前面一层输出与经过该层卷积后输出的线性叠加,非常的平滑
反向传播数学推导
一般的卷积神经网络是首尾相连的,而残差神经网络后面的任何一层xL向量的内容会有一部分由其前面的某一层xl线性贡献。 我们看到某曾输出xL的函数表达式 :
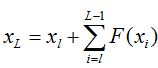
那么残差我们定义为E(就是Loss),应该有
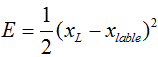
后面的xlable表示的是在当前样本和标签给定情况下某一层xL所对应的理想向量值,这个残差就来表示它就可以了。下面又是老生常谈的求导过程了,这里就是用链式法则可以直接求出来的,很简单
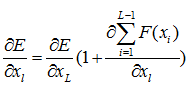
它可以使得 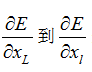














 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









