







分享一篇对深度的脉冲神经网络剪枝的论文,这篇论文发表在MM'23(CCF-A类会议),论文代码已经在github开源,一作来自北京大学,其余作者都来自快手。这篇博客主要介绍其中的技术细节,背景知识会稍微提到,实验结果请参看论文。
摘要
脑启发的脉冲神经网络(Spiking Neural Network, SNN)具有事件驱动和高能效的特点,这与传统的人工神经网络(ANN)在神经形态芯片等边缘设备上部署不同。以往的工作集中在SNN的训练策略,以提高模型性能,带来更大、更深的网络架构。但是这很难直接在资源有限的边缘设备上部署这些复杂的网络。为了满足这种需求,人们非常谨慎地压缩SNN,以平衡性能和计算效率。现有的压缩方法要么使用权值范数大小迭代简直SNN,要么将问题表述为稀疏学习优化。针对该稀疏学习问题,我们提出了一种改进的端到端极大极小优化方法,以更好地平衡模型的性能和计算效率。我们还证明了在SNN上联合应用压缩和微调优于顺序应用,特别是对于极端压缩比。压缩的SNN模型在各种基准数据集和架构上实现了最先进的(SOTA)性能。
引言
脉冲神经网络作为第三代神经网络,近年来受到了广泛的关注。SNN是大脑启发式智能研究的核心,具有较高的生物学可解释性和较强的时空信息处理能力。此外,由于脉冲训练固有的异步性和稀疏性,这些类型的网络可以保持相对较好的性能和较低的功耗,特别是当与神经形态芯片结合时。随着高效的深度SNN训练策略的发展,建立了一些有用的网络架构,如脉冲ResNet 和SEW ResNet,以提高SNN的性能。SNN模型的参数和计算能耗迅速增加,而边缘器件的计算资源通常都很有限。例如,SpiNNaker证明可以在48芯片上运行多达25万个神经元和8000万个突触的网络,但这仍然无法运行那些更先进的SNN。因此,在实际场景中部署SNN之前进行压缩具有重要意义,从而降低计算成本,节省存储资源,帮助研究人员从高节能中获得更多好处。权值剪枝是一种广泛使用的技术,通过剔除卷积核或全连通权值矩阵的个体权值来压缩模型大小。
LIF神经元计算方程

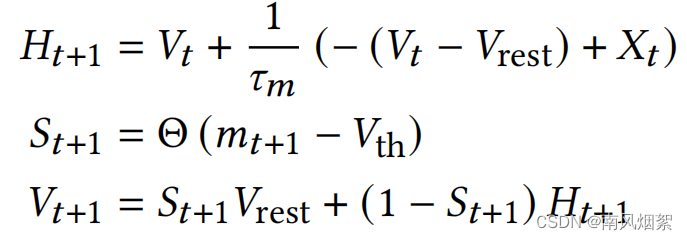
相关工作
本文方法
问题描述
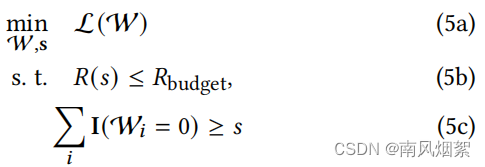
- (5a):是一般的损失函数(本文使用的是替代梯度下降的方法进行训练),损失越小,模型精度越高。因此,我们希望能够使损失值最小;
- (5c):(5a)必须在满足(5b)和(5c)的前提下使损失值最小,这里我们先讲(5c)。(5c)的意思是权值为0的连接数量需要大于s,权值为0不就是删除了这条连接嘛,所以统计有多少权值为0的数量,就知道删除了连接了。s是一个值,表示要删除多少条连接。
- (5b):正常来说,剪枝只需要考虑删除的连接数量(稀疏度)和精度(损失值)就可以了。但是,作者对这个问题更加深入了一下。我们知道,删除权值可以减少FLOPs,在特定硬件上运行更快、能耗更低。所以,R(s)就是衡量在删除 s 条连接后,运行这个网络的预算是多少,这里的预算可以是很多指标,文中提到了FLOPs和Latency。Rbudget就是一个预先设定的预算值。问题转换
问题转换
有了上面的三个形式化描述公式还不行呀,我怎么训练呀???
回忆一下正常的反向传播算法是怎么计算的:损失函数和梯度。
(5a)是可以直接进行反向传播的,那(5b)和(5c)咋整??所以需要对 5b)和(5c)进行转换,使其能够进行反向传播。
我们先看(5c),(5c)的意思是权值为0的连接数量要大于s。对于这个问题,我们可以换个思路。‘权值等于0的连接数量要大于s’ 和 ‘最小的s个权值的平方和应该等于0’是一个意思叭。我们理解一下这句话:首先每个权值进行平方得到了,然后进行排序,选取最小的s个平方值进行求和得到sum,只要sum等于0,就说明这个网络中至少有s条权值为0的连接叭。
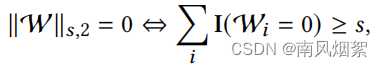
上面的图就是对(5c)的转换。
(5b)咋整呢??它要求就可以了,这个需要结合完整的损失函数来理解,直接上公式:
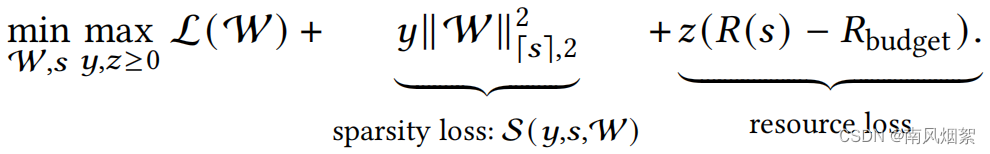
上图就是完整的极小化极大化的公式,这里面有三项,y和z是两个学习变量,我们分开解说。
第一个公式L(W)就是普通的损失函数。
第二项就是(5c)转换后的公式。
第三项就是(5b)转换后的公式。
为啥要求y和z大于0???为啥要求先是最大??
首先,在反向传播的时候,我们希望损失值越小越好叭。
对于第二项,这是个非负数,那么我们考虑两种情况,大于0和等于0。(1)如果 不等于0,y是个非负数,而且内层是要求max函数,那么在反向传播的时候,y就会朝着正无穷的方向发展,导致整个损失函数变成无穷大;(2)如果
等于0,那么第二项就永远是0。
对于第三项,与第二项的原理是相同的,不同的是第三项可以为负数,不过这不影响,因为z是大于等于0的。
所以上面的损失函数中,内层的max函数使得在反向传播的时候,权值更新朝着满足条件的情况发展。在满足条件的情况下,我们就可以使当前的损失值最小了,就是最外层的min函数。
所以,作者通过将约束条件转换为损失函数中的附加项,从而使得其能够直接反向传播训练。
STE训练
得到上面的损失函数后,还有一个问题就是梯度反传,这就要求可导。认真观察后面两项,其实在可导方面存在问题的。 针对这个问题,作者使用了straight-through estimator (STE)方法。详细的梯度反传可以看论文哈!!
实验结果
作者使用Spikingjelly作为实现框架,具体的训练细节和实验结果请参看论文!


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









