






 该论文介绍了早期将深度卷积神经网络(CNN)转化为脉冲神经网络(SNN)的方法,通过调整CNN结构适应SNN需求并迁移权重,实现了与CNN相近的识别精度,为低功耗目标识别提供了可能。实验在Neovision2Tower和CIFAR-10数据集上验证了有效性。
该论文介绍了早期将深度卷积神经网络(CNN)转化为脉冲神经网络(SNN)的方法,通过调整CNN结构适应SNN需求并迁移权重,实现了与CNN相近的识别精度,为低功耗目标识别提供了可能。实验在Neovision2Tower和CIFAR-10数据集上验证了有效性。
这篇论文是发表于2014年的一篇ANN-SNN的论文,也是非常早期的将ANN转为SNN的论文。本篇论文介绍了一种将深度卷积神经网络(CNN)转化为脉冲神经网络(SNN)的方法,以实现超低功耗的目标识别。通过调整CNN的架构以适应SNN的要求,并将学习到的网络权重应用于SNN架构,研究人员成功地实现了与原始CNN相似的目标识别准确率。这种方法有望在实现高能效的同时保持卓越的目标识别性能,为具有严格尺寸、重量和功耗要求的实际视觉应用打开了新的可能性。
 https://blog.csdn.net/weixin_40936298/article/details/136161033?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_40936298/article/details/136161033?spm=1001.2014.3001.5502典型的CNN结构
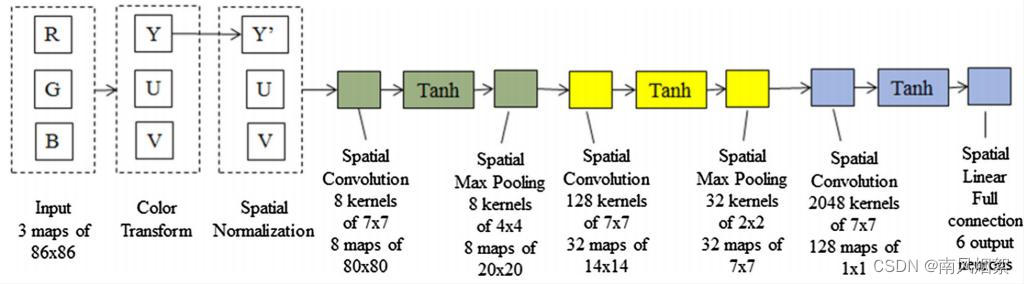
上图展示了一个典型的CNN结构。第一层是由一组滤波器组成的空间卷积层。第二层是一个非线性函数,通常由函数tanh()实现。tacnh()是双曲切线函数,这是CNN中模拟神经元输出激活的标准方法(随着研究发展,目前已经有很多激活函数了)。空间卷积是一种二维线性滤波,对前一层的所有神经元进行一组滤波核,生成一组特征映射。第三层也是最后一层是空间最大池化,它取非线性层产生的特征图中一个小图像邻域的最大输出值。在上图所示的示例中,最后一个卷积层没有最大池化层。CNN的最后一层是一个全连接的单层线性分类器。整个网络可以使用具有随机梯度下降的标准误差反向传播算法进行训练。训练CNN的目标是调整系统参数(即卷积核权值和偏差),这样当有一个未知的输入图像时,CNN的输出就可以预测该类(即标签)。
ANN-SNN转换
其实这篇文章的转换思想比较,最开始想的就是:将在CNN中训练的参数直接映射到同等结构的SNN中(一比一复制)。
ANN-SNN转换的精度损失
但是作者发现,直接将一个传统的CNN参数映射到SNN中会出现精度损失,这个精度损失来自以下几个方面:
(1)CNN层的负输出值难以在SNN中准确表示。负值来自于以下CNN的计算:
- tanh()函数的输出值是(-1,1);
- 在每个卷积层中,每个输出特征图的值都是输入加上偏差的加权和。权重和偏差都可以是负的,导致输出值是负的;
- 来自预处理的输出值(例如,颜色变换和空间归一化)可以产生负值。
(2)与CNN不同,没有好的方法来表示脉冲神经网络中的偏置项。每个卷积层中的偏置可以是正的,也可以是负的,这在SNN中不容易表示。
(3)最大池化需要两层脉冲网络。在CNN中,最大池化被实现为取输入中一个小图像邻域的最大输出值。在SNN中,需要两层的神经网络来实现。
转换方法
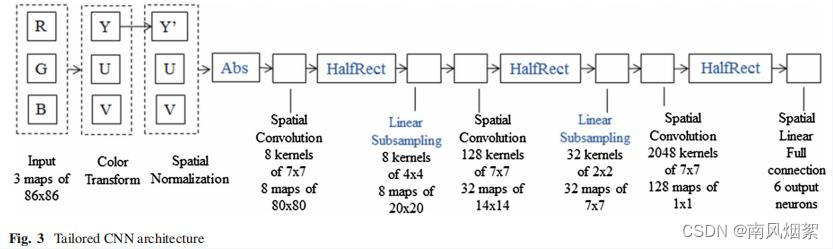
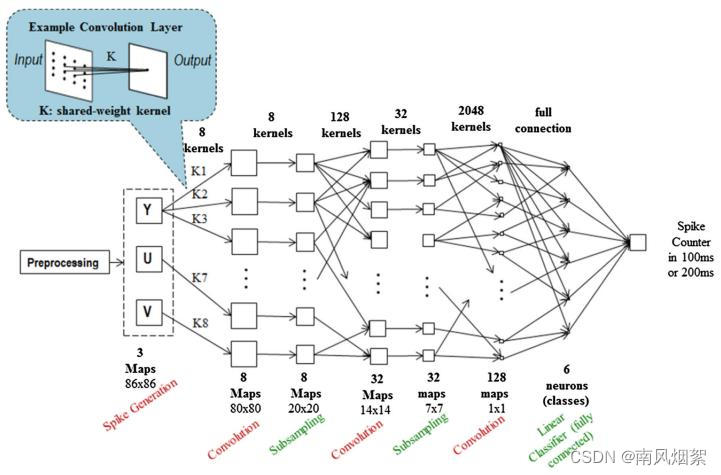
针对上述问题,作者设计了一个定制的CNN架构,先训练这个定制的CNN网络,然后再将其中的权值参数移植到SNN中。

这里定制的网络结构包括以下3点:
(1)使每一层的输出值都为正数。这主要通过以下两点实现:
- 在预处理阶段后添加一个abs()函数层,包括颜色转换和空间归一化。abs() 函数确保了到第一个卷积层的输入值都是非负的。
- 使用ReLU作为激活函数
(2)去除所有卷积层和全连接层的偏置项。
(3)使用平均池化代替最大池化。
实验
作者使用两个数据集验证了方法的有效性:Neovision2 Tower数据集和CIFAR-10数据集。CIFAR-10实验结果:在原始CNN的精度是79.12%;在定制CNN的精度是79.09%;在SNN的精度是77.43%。
总结
从2024年回望2014年这篇ANN-SNN转换的论文,可能思想比较简单,效果和现在相比也差距较大。但是在当时能够使用SNN将CIFAR-10的精度训练到77.43%,应该是比较厉害的了。


















 6275
6275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









