









 Whisper是OpenAI的多任务语音识别模型,支持多语言识别、翻译和语言识别。本文档介绍了如何设置、使用Whisper模型,包括命令行和Python API,并给出了模型性能的数据。同时,推荐了兼容openai接口的API服务。
Whisper是OpenAI的多任务语音识别模型,支持多语言识别、翻译和语言识别。本文档介绍了如何设置、使用Whisper模型,包括命令行和Python API,并给出了模型性能的数据。同时,推荐了兼容openai接口的API服务。
Whisper
Whisper 是一种通用语音识别模型。它是在大量不同音频数据集上进行训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。官方地址 https://github.com/openai/whisper
方法
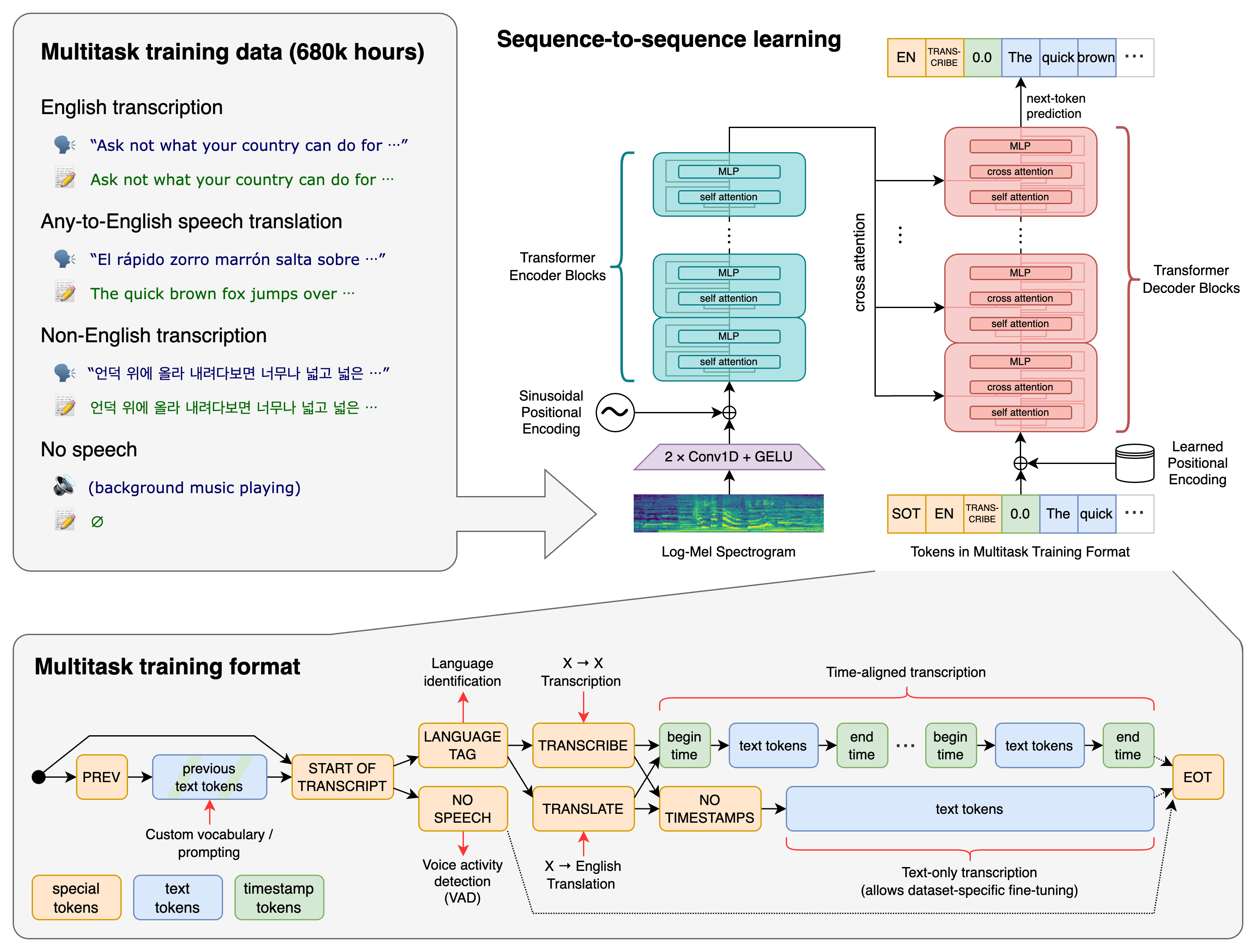
一个Transformer序列到序列模型被训练在多种语音处理任务上,包括多语言语音识别、语音翻译、口语语言识别以及语音活动检测。这些任务被共同表示为一系列由解码器预测的令牌,使得单一模型能够替代传统语音处理管道中的多个阶段。多任务训练格式采用了一组特殊令牌,作为任务指定符或分类目标。
设置
Whisper使用Python 3.9.9和PyTorch 1.10.1来训练和测试我们的模型,但代码库预期与Python 3.8至3.11版本及近期的PyTorch版本兼容。该代码库还依赖于几个Python包,特别是OpenAI的tiktoken</

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











