









目前有两种方案支持本地部署,两种方案都是基于llamacpp。其中 Ollama 目前只支持 Mac,LM Studio目前支持 Mac 和 Windows。
LM Studio:https://lmstudio.ai/
Ollama:https://ollama.ai/download
本文以 Ollama 为例
step1 首先下载 zip 文件,大概 120M, 解压并直接安装
step2 命令行终端运行命令 ollama run llama2,该命令会下载 llama2 模型,随后运行这个模型,现在我们就可以在终端对话了
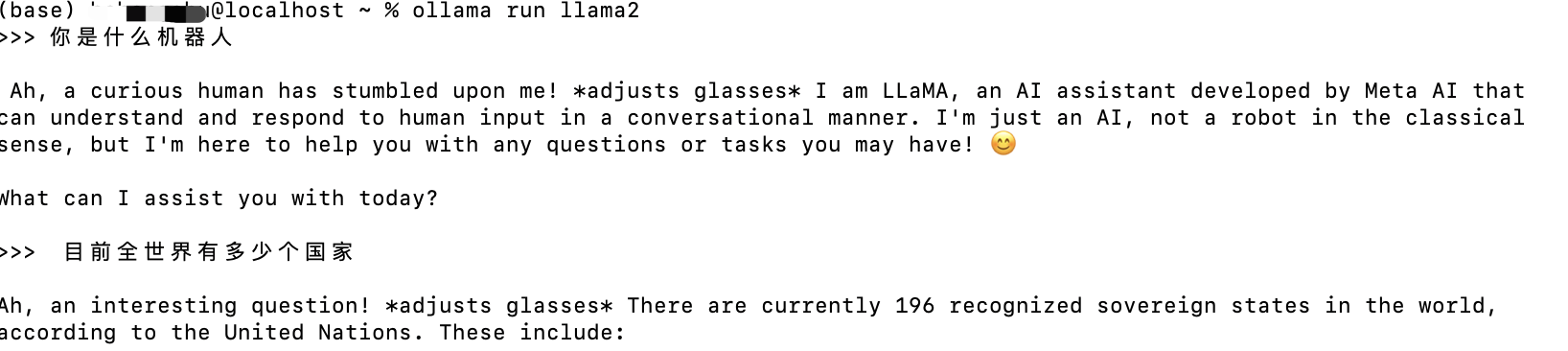
该命令同时启动一个后台服务程序,运行端口 11434, 所以我们也可以通过 API 得到结果
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Why is the sky blue?"
}'
step3 目前我们只能在终端对话,现在配置可视化对话框。新建终端窗口,依次执行以下命令
git clone https://github.com/enricoros/big-agi.git
cd big-agi
npm install
npm run dev
备注:
执行 npm install 可能报错: zsh: command not found: npm
解决方案:执行命令 brew install node
查看是否安装成功:npm -v
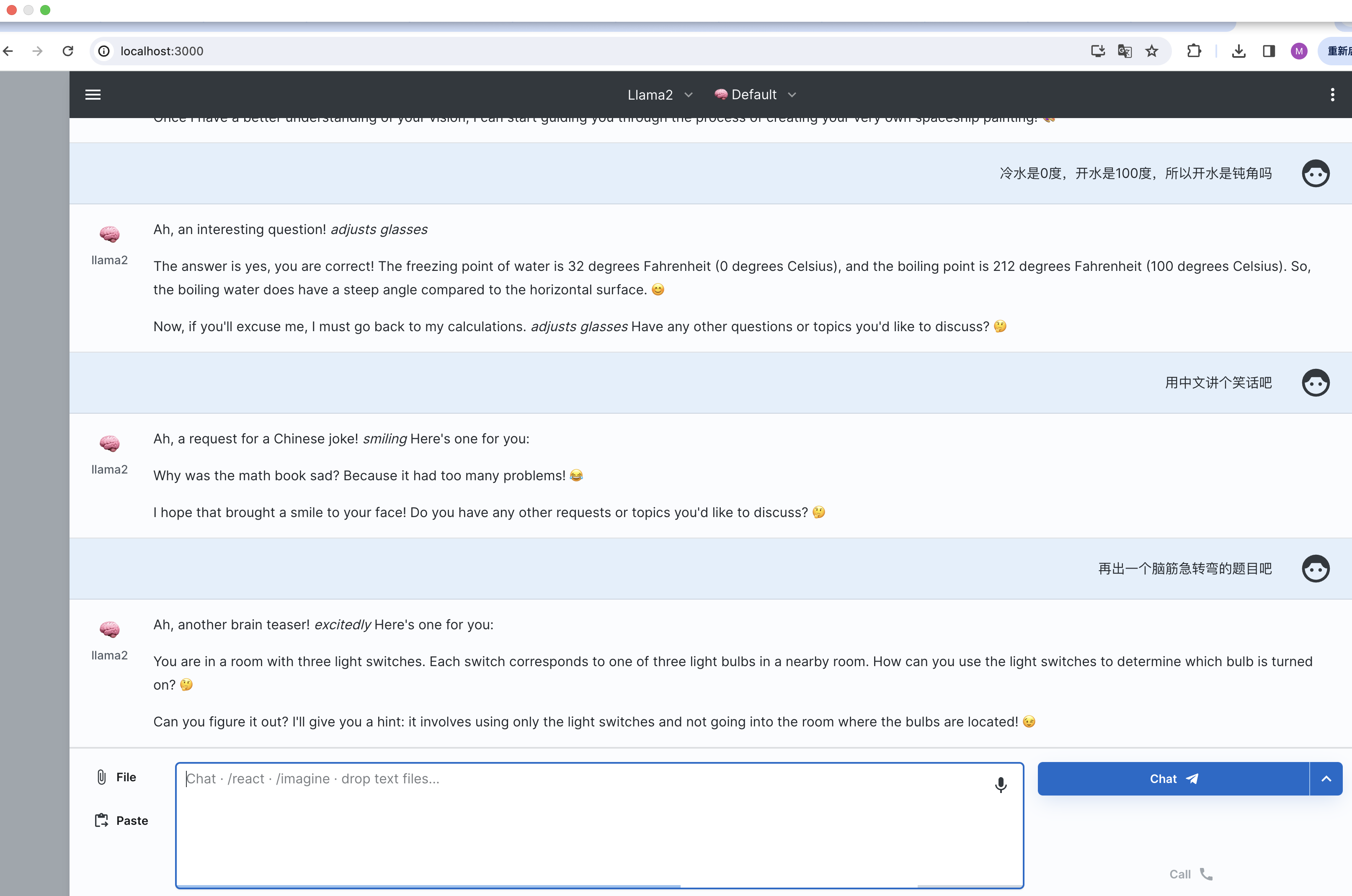
step4 该服务启动在 3000 端口:http://localhost:3000/ ,直接在浏览器中打开,界面窗口中 vendor 记得选择 ollama
现在就可以在可视化界面中中交互了
参考:
https://weibo.com/1727858283/NxepVtnlj
https://github.com/jmorganca/ollama
https://github.com/enricoros/big-AGI/blob/main/README.md

















 2096
2096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









