






先介绍几个相关概念:
1.零样本学习(zero-shot)
参考:https://blog.csdn.net/gary101818/article/details/129108491
利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;例如模型训练使用马、老虎和熊猫。模型需要识别斑马类别。对于传统的监督学习方法,需要收集一些斑马的图片进行训练。而零样本学习,不需要收集图片重新训练。只需要将用马、老虎和熊猫训练的模型。再告诉它斑马的信息即可用来识别斑马。不用收集样本进行重新训练。
clip介绍
参考:https://blog.csdn.net/weixin_53280379/article/details/125585445
CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。作者看到一般使用vit较多,可能因为vit效果比CNN更好。
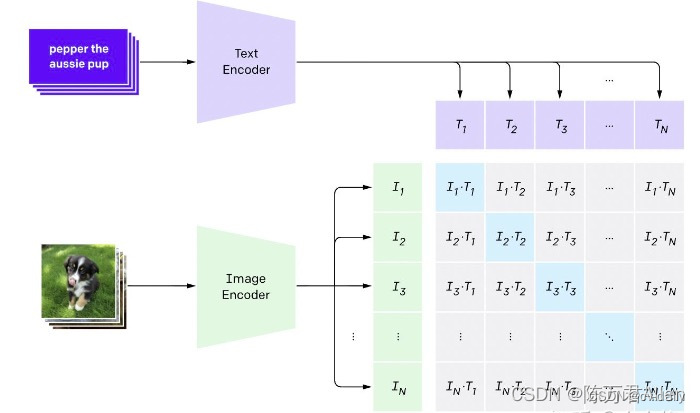
上面我们介绍了CLIP的原理,可以看到训练后的CLIP其实是两个模型,除了视觉模型外还有一个文本模型,那么如何对预训练好的视觉模型进行迁移呢?与CV中常用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类,这也是CLIP亮点和强大之处。用CLIP实现zero-shot分类很简单,只需要简单的两步:
根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为[公式],那么将得到[公式]个文本特征;
将要预测的图像送入Image Encoder得到图像特征,然后与[公式]个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。















 7367
7367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









