






一、原理
到目前为止,主要有两大类知识蒸馏:一类是logits蒸馏,另一类是特征蒸馏。前者是直接匹配网络输出的概率分布或学习一批logits的分布来强制匹配;后者是直接匹配中间的特征或学习特征之间的转换关系。例如,在特征No.1和No.2中间,知识可以表示为如何模做两者中间的转化,可以用一个矩阵让学习者产生这个矩阵,学习者和转化之间的学习关系。
看到有一些经验说:分类模型蒸馏效果 好,检测模型蒸馏效果一般,后处理越多的蒸馏效果不好。可以实际用一下看看。
1.1logits蒸馏
参考:https://blog.csdn.net/weixin_40620310/article/details/124004687
https://blog.csdn.net/qq_60445109/article/details/125245695
模型蒸馏
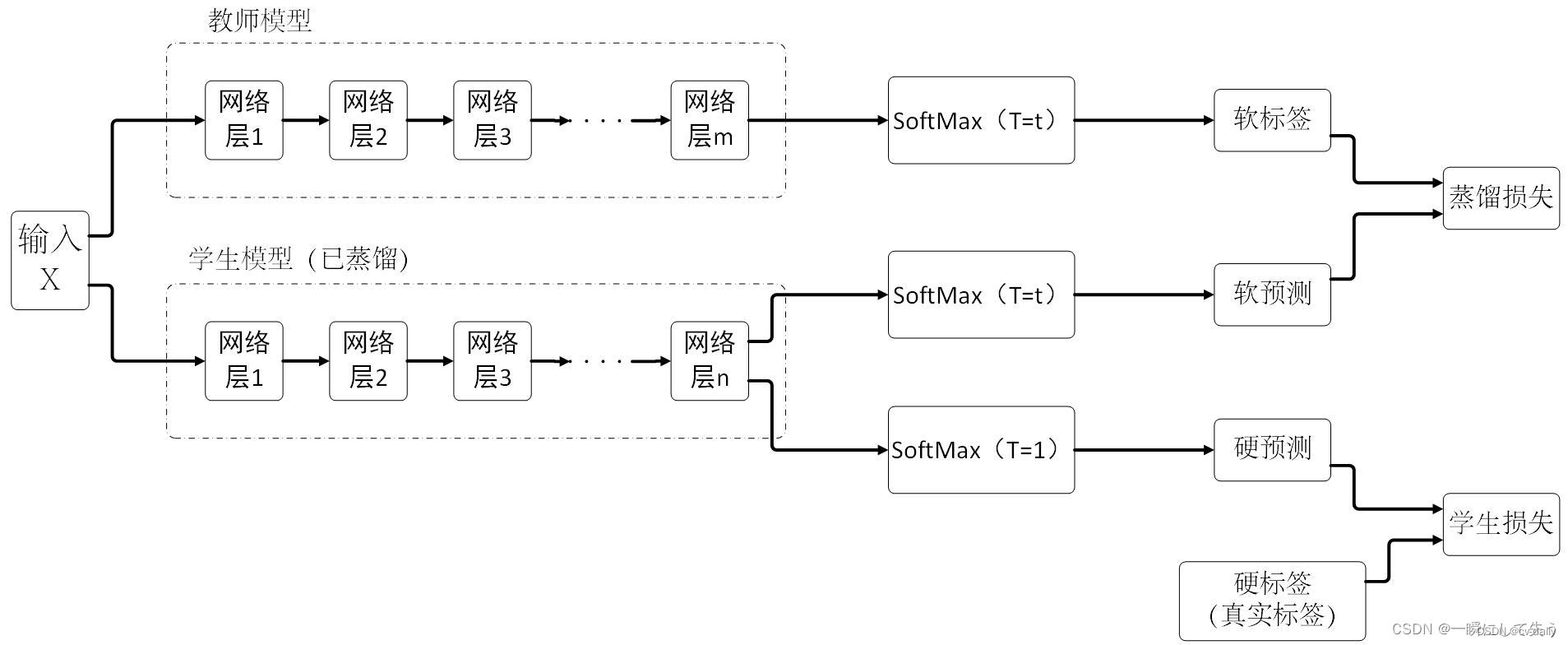 温度系数T
温度系数T
软标签可以把错误标签的信息呈现出来,但是在呈现时有些错误标签的差距不明显,也就是标签值不够软。这个时候为了把这个不明显的差距变得更为明显,论文作者就引入了温度系数T来改变原来的SoftMax函数,即:
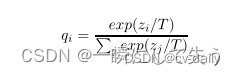
式中qi代表使用SoftMax输出的类别概率、zi代表每个类别的logit、T为温度系数。
PS:如果T小,错误类别的信息差距较小,但如果T过大,标签就会过软,容易导致平均主义,难以达到预测的效果,具体T的选值效果如下所示。
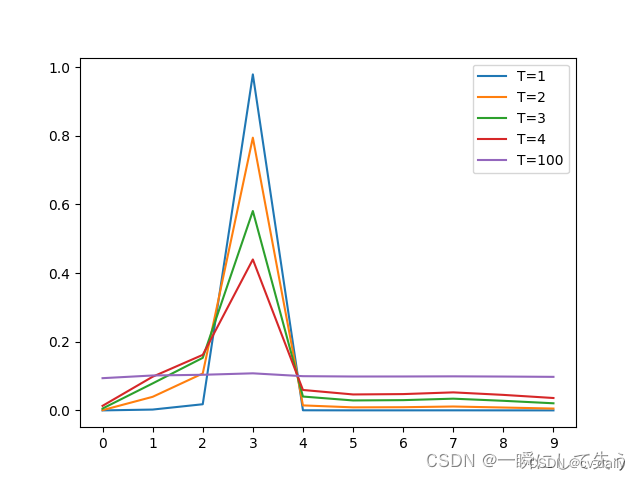
图中,我们可以看出T越大,曲线越平滑。如果T过大就易出现平均主义,就会变得难以预测。
方法一
简单流程如下:
1、数据集上训练一个teacher网络;
2、训练一个student网络"模仿"teacher网络;
3、让小网络模拟大网络的logits(后续讲解);
优点:Teacher可以帮助过滤一些噪声标签,对于Student来说,学习一个连续值比0、1标签的学习效率更高,学到的信息量更大;
logits是指什么?
利用大模型生成的概率作为小模型的"soft target",可以将大模型的泛化能力转移到小模型,在这个迁移阶段可以使用相同的训练集或单独的数据集来训练大模型;
当soft target熵很高的时候,训练时能够比hard targets提供更多的信息和更少的梯度方差,所以小模型通常可以使用更少的训练样本和更大的学习率;
注意:这里的soft target表示具体的概率值,通常将0、1值的输出称为hard target;
1、teacher网络的输出作为student网络的soft label,也就是软标签,输出的值是连续值;
2、student网络的输出有两个分支,一个为soft predictions,一个为hard predictions,其中hard表示硬标签的意思,输出的值为one-hot形式;
3、最终的Loss为student网络的输出分别与teacher网络的soft labels、实际的hard labels计算损失值,最终将二者的Loss值进行结合;
使用蒸馏的一些建议:
 1.2特征蒸馏
1.2特征蒸馏
参考:https://blog.csdn.net/qq_15821487/article/details/120868224
https://blog.csdn.net/weixin_45250844/article/details/126448414
纯粹的logits蒸馏可能会引起学生网络难以学习的情况,因此考虑到可以结合特征蒸馏,具体是需要在教师和学生网络的中间层做feature之间的map,但因为往往特征蒸馏会因为中间层特征尺度不一致的情况,导致蒸馏过程需要额外的线性匹配,与此同时,实现难度也因此高了一点点。
特征蒸馏参考PaddlePaddle_BERT模型蒸馏,蒸馏包括中间层的蒸馏和预测层的蒸馏。
蒸馏层的选择
知识的蒸馏通常是通过让学生模型学习相关的蒸馏相损失函数实现,在本实验中,蒸馏的学习目标由两个部分组成,分别是中间层的蒸馏损失和预测层的蒸馏损失。其中,中间层的蒸馏包括对Embedding层的蒸馏、对每个Transformer layer输出的蒸馏、以及对每个Transformer中attention矩阵(softmax之前的结果)的蒸馏,三者均采用的是均方误差损失函数。而预测层蒸馏的学习目标则是学生模型输出的logits和教师模型输出的logits的交叉熵损失。
蒸馏层的映射
由于教师模型是12层,学生模型的层数少于教师模型的层数,因此需要选择一种layer mapping的方式。论文中采用了一种固定的映射方式,当学生模型的层数为教师模型的1/2时,学生第i层的attention矩阵,需要学习教师的第2i+1层的attention矩阵,Transformer layer输出同理。
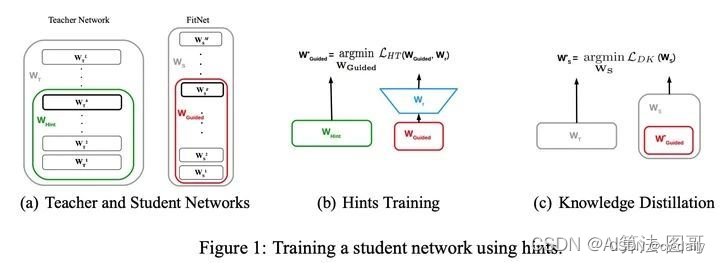
第一阶段:首先选择待蒸馏的中间层(即Teacher的Hint layer和Student的Guided layer),如图中绿框和红框所示。由于两者的输出尺寸可能不同,因此,在Guided layer后另外接一层卷积层,使得输出尺寸与Teacher的Hint layer匹配。接着通过知识蒸馏的方式训练Student网络的Guided layer,使得Student网络的中间层学习到Teacher的Hint layer的输出.
第二阶段: 在训练好Guided layer之后,将当前的参数作为网络的初始参数,利用知识蒸馏的方式训练Student网络的所有层参数,使Student学习Teacher的输出。由于Teacher对于简单任务的预测非常准确,在分类任务中近乎one-hot输出,因此为了弱化预测输出,使所含信息更加丰富,作者使用Hinton等人论文《Distilling knowledge in a neural network》中提出的softmax改造方法,即在softmax前引入 缩放因子,将Teacher和Student的pre-softmax输出均除以 。也就是上面我们讲的加了温度的softmax。
疑问:特征维度不匹配的时候,可以选择线性匹配和卷积层。这里加一个卷积层,那这个卷积层参与训练吗?不参与训练的话每次用随机值吗?感觉不太合理。
BERT的蒸馏似乎多一些:https://zhuanlan.zhihu.com/p/273378905
二、logist蒸馏(软标签+硬标签loss)代码实现
参考代码:https://github.com/Adlik/yolov5 此方法d_feature暂时不支持。
还有一个代码暂时没有用到:https://github.com/Sharpiless/Yolov5-distillation-train-inference
两种应该差不多。
https://cloud.tencent.com/developer/article/2160509
yolov5间的模型蒸馏,相同结构的。
配置参数
parser.add_argument('--t_weights', type=str, default='./weights/yolov5s.pt',
help='initial teacher model weights path')
parser.add_argument('--t_cfg', type=str, default='models/yolov5s.yaml', help='teacher model.yaml path')
parser.add_argument('--d_output', action='store_true', default=False,
help='if true, only distill outputs')
parser.add_argument('--d_feature', action='store_true', default=False,
help='if true, distill both feature and output layers')
加载教师模型
Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
# 这里添加加载教师模型
# Teacher model
LOGGER.info(f'Loaded teacher model {t_cfg}') # report
t_ckpt = torch.load(t_weights, map_location=device) # load checkpoint
t_model = Model(t_cfg or t_ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device)
exclude = ['anchor'] if (t_cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = t_ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, t_model.state_dict(), exclude=exclude) # intersect
t_model.load_state_dict(csd, strict=False) # load
损失函数:
def compute_distillation_output_loss(p, t_p, model, d_weight=1):
t_ft = torch.cuda.FloatTensor if t_p[0].is_cuda else torch.Tensor
t_lcls, t_lbox, t_lobj = t_ft([0]), t_ft([0]), t_ft([0])
h = model.hyp # hyperparameters
red = 'mean' # Loss reduction (sum or mean)
if red != "mean":
raise NotImplementedError("reduction must be mean in distillation mode!")
##三部分的损失都使用nn.MSELoss
DboxLoss = nn.MSELoss(reduction="none")
DclsLoss = nn.MSELoss(reduction="none")
DobjLoss = nn.MSELoss(reduction="none")
# per output
for i, pi in enumerate(p): # layer index, layer predictions
t_pi = t_p[i]
t_obj_scale = t_pi[..., 4].sigmoid()
# BBox
b_obj_scale = t_obj_scale.unsqueeze(-1).repeat(1, 1, 1, 1, 4)
t_lbox += torch.mean(DboxLoss(pi[..., :4], t_pi[..., :4]) * b_obj_scale)
# Class
if model.nc > 1: # cls loss (only if multiple classes)
c_obj_scale = t_obj_scale.unsqueeze(-1).repeat(1, 1, 1, 1, model.nc)
# t_lcls += torch.mean(c_obj_scale * (pi[..., 5:] - t_pi[..., 5:]) ** 2)
t_lcls += torch.mean(DclsLoss(pi[..., 5:], t_pi[..., 5:]) * c_obj_scale)
# t_lobj += torch.mean(t_obj_scale * (pi[..., 4] - t_pi[..., 4]) ** 2)
t_lobj += torch.mean(DobjLoss(pi[..., 4], t_pi[..., 4]) * t_obj_scale)
t_lbox *= h['box']
t_lobj *= h['obj']
t_lcls *= h['cls']
# bs = p[0].shape[0] # batch size
loss = (t_lobj + t_lbox + t_lcls) * d_weight
return loss
s_loss, loss_items = compute_loss(pred, targets.to(device)) #pred是三个特征层的输出,三个特征层的输出作为软标签。(32,3,60,60,9),(32,3,30,30,9),(32,3,15,15,9).
d_outputs_loss = compute_distillation_output_loss(pred, t_pred, model, d_weight=10)
if opt.d_feature:
d_feature_loss = compute_distillation_feature_loss(s_f, t_f, model, f_weight=0.1)
loss = d_outputs_loss + s_loss + d_feature_loss
else:
loss = d_outputs_loss + s_loss
三、特征蒸馏代码实现
可以指定蒸馏任意层的特征。
参考:https://blog.csdn.net/liuhao3285/article/details/133895411?spm=1001.2014.3001.5502
修改yolov5/train.py loss.py yolo.py















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









