







5 Experimental Setup
说明
选择80%的药物对 作为训练集,剩下两个10%分别作为验证集和测试集
选择80%的副作用(边)来训练模型,10%的drug 对来选择模型参数。
同时,会以 additional 向量
x
x
x 的形式 把其他所需的信息(比如药物自身的side effect)集成到模型中去
为了避免产生环同时没有信息泄露,我们保证:
- 我们所给出的多药物副作用仅仅出现在多药物中,而不会出现在一个药物自己的效用或副作用当中
- 我们要预测的这些 side effect 是不会以 side feature 向量的方式出现在某一个节点中的
其他方法
由于不清楚现阶段是否有其他可以预测drug pair的side effect的模型,Decagon与一下方法比较性能:
- RESCAL tensor decomposition,用矩阵分解的方法,把矩阵分为两个带有可训练参数矩阵与一个T矩阵的乘积,从而得到结果
- DEDICOM tensor decomposition ,与上述方法相似,只不过更适用于稀疏矩阵,所以分解成更多的矩阵相乘的形式
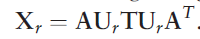
- DeepWalk 神经嵌入,这个方法基于一个偏置的随机游走过程探索节点在网络中的邻居,为每个节点学习一个 d 维的神经向量。之后为每一个 边类型,都训练一个回归分类器
- 连接药物特征:这种方法基于 主成分分析 表示药物与其作用的蛋白质的反应为每一个药物构建一个特征向量。然后药物对,就是两个药物向量的连接,然后使用机器学习的方法预测药物作用类型
对每种方法的参数设定:使用了”网格搜索“方法和一个验证集。对于那些不是 多边预测的方法,找到了那些表现最好的单边预测结果
性能是通过三个指标来计算的:
- AUROC
- AUPRC
- AP@50
都是越高的数值代表更高的性能
补充
AUROC
假设我们有一个概率二元分类器,比如逻辑回归。
在讨论ROC曲线(接受者操作特征曲线)之前,我们需要理解混淆矩阵(confusion matrix)的概念。一个二元预测可能有4个结果:
我们预测0,而真实类别是0:这被称为真阴性(True Negative),即,我们正确预测类别为阴性(0)。比如,杀毒软件没有将一个无害的文件识别为病毒。
我们预测0,而真实类别是1:这被称为假阴性(False Negative),即,我们错误预测类别为阴性(0)。比如,杀毒软件没有识别出一个病毒。
我们预测1,而真实类别是0:这被称为假阳性(False Positive),即,我们错误预测类别为阳性(1)。比如,杀毒软件将一个无害的文件识别为病毒。
我们预测1,而真实类别是1:这被称为真阳性(True Positive),即,我们正确预测类别为阳性(1)。比如,杀毒软件正确地识别出一个病毒。
我们统计模型做出的预测,数一下这四种结果各自出现了多少次,可以得到混淆矩阵:

在上面的混淆矩阵示例中,在分类的50个数据点中,45个分类正确,5个分类错误。
当比较两个不同模型的时候,使用单一指标常常比使用多个指标更方便,下面我们基于混淆矩阵计算两个指标,之后我们会将这两个指标组合成一个:
真阳性率(TPR),即,灵敏度、命中率、召回,定义为TP/(TP+FN)。从直觉上说,这一指标对应被正确识别为阳性的阳性数据点占所有阳性数据点的比例。换句话说,TPR越高,我们遗漏的阳性数据点就越少。
假阳性率(FPR),即,误检率,定义为FP/(FP+TN)。从直觉上说,这一指标对应被误认为阳性的阴性数据点占所有阴性数据点的比例。换句话说,FPR越高,我们错误分类的阴性数据点就越多。
为了将FPR和TPR组合成一个指标,我们首先基于不同的阈值(例如:0.00; 0.01, 0.02, …, 1.00)计算前两个指标的逻辑回归,接着将它们绘制为一个图像,其中FPR值为横轴,TPR值为纵轴。得到的曲线为ROC曲线,我们考虑的指标是该曲线的AUC,称为AUROC。
下图展示了AUROC的图像:

在上图中,蓝色区域对应接受者操作特征曲线(AUROC)。对角虚线为随机预测器的ROC曲线:AUROC为0.5. 随机预测器通常用作基线,以检验模型是否有用。
AP@50(Average Precision at 50%)

网格搜索(grid searching)
Grid Search:一种调参手段;穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。(为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search)、
存在的问题
原始数据集划分成训练集和测试集以后,其中测试集除了用作调整参数,也用来测量模型的好坏;这样做导致最终的评分结果比实际效果要好。(因为测试集在调参过程中,送到了模型里,而我们的目的是将训练模型应用在unseen data上)
解决方法
对训练集再进行一次划分,分成训练集和验证集,这样划分的结果就是:原始数据划分为3份,分别为:训练集、验证集和测试集;其中训练集用来模型训练,验证集用来调整参数,而测试集用来衡量模型表现好坏。
总结
交叉验证经常与网格搜索进行结合,作为参数评价的一种方法,这种方法叫做grid search with cross validation。sklearn因此设计了一个这样的类GridSearchCV
说到底其实人家已经帮我们做好了(摊手……)















 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









