







目录
1.简介
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。上述机制通常被称为注意力机制
综上,注意力机制主要有两个方面:决定需要关注输入的哪部分;分配有限的信息处理资源给重要的部分。
在深度学习中,注意力可以借助重要性权重向量来实现:在预测或推断一个元素时,如图片中的像素点或句中的一个词,我们使用注意力向量来判断,它与其他元素有多强的关联性,然后对加权后的向量求和以逼近最后的目标值(target)。
2.注意力机制的诞生
注意力机制最早于2014年在计算机视觉中提出。但是本文的讨论以机器翻译任务上的seq2seq模型为例。
Seq2Seq模型: 将一个输入序列(source)转化为另一个序列(target),两个序列都可以是不定长的。
场景:
- 多语言机器翻译(文本或语音)
- 问答对话对话生成系统
- 将句子解析为语法树
结构:循环神经网络结构
- 编码器:处理序列输入并压缩信息到一个固定长度的上下文向量中。上下文向量被当做是输入序列的语义概要。
- 解码器:由上下文向量初始化,并每次产生一个转码输出。
源输入和目标输出的语义对齐问题由上下文向量学习和控制。上下文向量处理三方面的信息:
- 编码器的隐藏状态
- 解码器的隐藏状态
- 源输入和目标输出的对齐
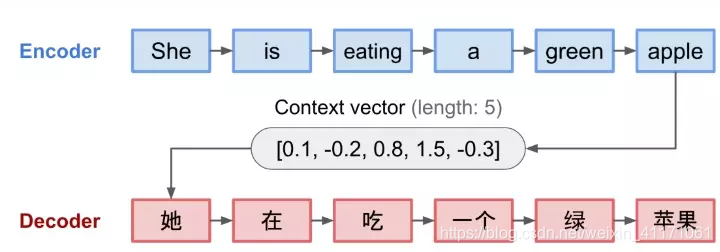
缺点: 固定长度上下文向量无法记忆长句子。
解决方法: 提出注意力机制(Bahdanau 2015)。注意力机制考虑了上下文向量和所有序列输入的信息,构建了“连接”。每一个输出元素下的连接的权重都是自动学习的。上下文向量已经考虑了整体输入序列信息,不需要担心遗忘的问题。
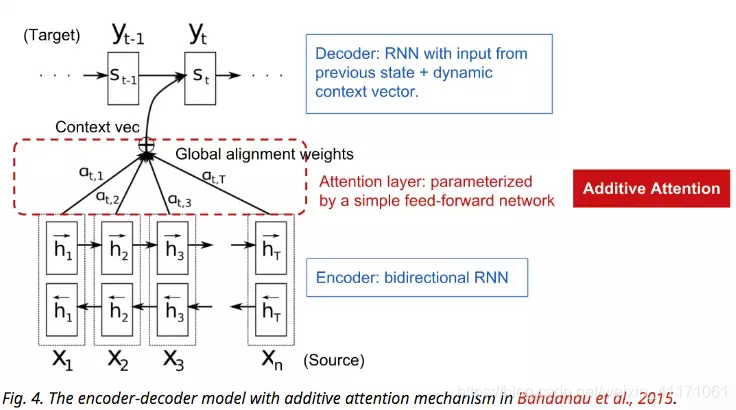
3.不同类别的计算原理
计算步骤:
- 在所有输入信息上计算注意力分布
- 根据注意力分布来计算输入信息的加权平均
3.1.普通模式注意力
定义:
- 和任务有关的查询向量 q \bm q q
- 注意力变量 z ∈ [ 1 , N ] z\in [1,N] z∈[1,N]表示被选择信息的索引位置。即 z = i z=i z=i表示选择了第 i i i个输入信息
- 在给定 q \bm q q和 X X X下,选择第 i i i个输入信息的概率 α i \alpha_i αi称为注意力分布(Attention Distribution)
- s ( x i , q ) s(x_i, \bm q) s(xi,q)为注意力打分函数
计算注意力分布:
α i = p ( z = i ∣ X , q ) = s o f t m a x ( s ( x i , q ) ) = e x p ( s ( x i , q ) ) ∑ j = 1 N e x p ( x j , q ) \alpha_i=p(z=i|X,\bm q)\\=softmax(s(x_i,\bm q))\\=\frac{exp(s(x_i,\bm q))}{ \sum_{j=1}^{N}exp(x_j,\bm q)} αi=p(z=i∣X,q)=softmax(s(xi,q))=∑j=1Nexp(xj,q)exp(s(xi,q))
注意力打分函数:
- 加性模型 s ( x i , q ) = v T t a n h ( W x i + U q ) s(x_i,\bm q)=v^Ttanh(Wx_i+U\bm q) s(xi,q)=vTtanh(Wxi+Uq)
- 点积模型 s ( x i , q ) = x i T q s(x_i,\bm q)=x_i^T\bm q s(xi,q)=xiTq
- 缩放点积模型 s ( x i , q ) = x i T q d s(x_i,\bm q)=\frac{x_i^T\bm q}{\sqrt d} s(xi,q)=dxiTq
- 双线性模型 s ( x i , q ) = x i T W q s(x_i,\bm q)=x_i^TW\bm q s(xi,q)=xiTWq
其中, W , U , v W,U,v W,U,v为可学习的网络参数, d d d为输入信息的维度。
理论上,加性模型和点积模型的复杂度差不多,但是点积模型在实现上可以更好地利用矩阵乘积,从而计算效率更高。但当输入信息的维度 d d d比较高,点积模型的值通常有比较大方差,从而导致softmax函数的梯度会比较小。因此,缩放点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









