







📌Java八股--集合(下)
- ConcurrentHashMap底层原理
- ConcurrentHashMap如何能够兼顾线程安全和效率?
- ConcurrentHashMap能否取代Hashtable?
- 除了拉链法和红黑树你还能想到什么解决哈希冲突的问题?
- ConcurrentHashMap是如果保证线程安全的呢?
- ConcurrentHashMap是如何获取size()的呢?会遇到什么问题?
- SynchronizedMap和 ConcurrentHashMap 有什么区别?
- ConcurrentHashMap和HashTable的区别;
- ConcurrentHashMap 的并发度是多少?
- ConcurrentHashMap 迭代器是强一致性还是弱一致性?
- ConcurrentHashMap如何保证高效,为什么是线程安全,为什么比HashTable优秀,分段锁机制;
- ConcurrentHashMap原理,1.7和1.8的区别,put,get,size,扩容,
- 怎么保证线程安全的,为什么用synchronized,分段锁有什么问题,hash算法做了哪些优化
- hashmap中如何优化哈希算法
- ConcurrentHashMap中如何优化哈希算法
- ConcurrentHashMap和hashtable区别,都能实现同步线程安全,ConcurrentHashMap好在哪?怎么实现的
Java后端各科最全八股自用整理,获取方式见:
ConcurrentHashMap底层原理
ConcurrentHashMap如何能够兼顾线程安全和效率?
在JDK7,Java使用了分段锁机制实现ConcurrentHashMap。简而言之,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,它通过继承ReentrantLock来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个Segment是线程安全的,也就实现了全局的线程安全;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。
concurrencyLevel:Segment数(并行级别、并发数)。默认是 16,也就是说开放定址法 ConcurrentHashMap 有16个Segments,所以理论上,这个时候,最多可以同时支持16个线程并发写,只要它们的操作分别分布在不同的 Segment上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。

在JDK1.7之前ConcurrentHashMap是一个Segment数组,Segment通过继承ReentrantLock来进行加锁,所以每次需要加锁的操作锁住的是一个segment,这样只要保证每个Segment是线程安全的,也就实现了全局的线程安全。
在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
ConcurrentHashMap能否取代Hashtable?
Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。 ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。
ConcurrentHashMap可以取代Hashtable,因为它提供了更好的并发性能和可伸缩性。ConcurrentHashMap是在Java 5中引入的,它比Hashtable更加高效,并且支持更多的并发操作。
除了拉链法和红黑树你还能想到什么解决哈希冲突的问题?
解决Hash冲突方法有:开放定址法、再哈希法、链地址法(HashMap中常见的拉链法)、简历公共溢出区。
- 开放定址法也称为再散列法,如果p=H(key)出现冲突时,则以p为基础,再次hash,p1=H§,如果p1再次出现冲突,则以p1为基础,以此类推,直到找到一个不冲突的哈希地址pi。因此开放定址法所需要的hash表的长度要大于等于所需要存放的元素,而且因为存在再次hash,所以只能在删除的节点上做标记,而不能真正删除节点
- 再哈希法(双重散列,多重散列),提供多个不同的hash函数,R1=H1(key1)发生冲突时,再计算R2=H2(key1),直到没有冲突为止。这样做虽然不易产生堆集,但增加了计算的时间。
- 链地址法(拉链法),将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行,链表法适用于经常进行插入和删除的情况。
- 建立公共溢出区,将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区
注意开放定址法和再哈希法的区别是
- 开放定址法只能使用同一种hash函数进行再次hash,再哈希法可以调用多种不同的hash函数进行再次hash
ConcurrentHashMap是如果保证线程安全的呢?
在JDK1.7之前ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
ConcurrentHashMap是如何获取size()的呢?会遇到什么问题?
JDK1.7
因为ConcurrentHashMap是可以并发插入数据的,所以在准确计算元素时存在一定的难度,一般的思路是统计每个Segment对象中的元素个数,然后进行累加,但是这种方式计算出来的结果并不一样的准确的,因为在计算后面几个Segment的元素个数时,已经计算过的Segment同时可能有数据的插入或则删除,在1.7的实现中,采用了如下方式:
先采用不加锁的方式,连续计算元素的个数,最多计算3次:
1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;
2、如果前后两次计算结果都不同,则给每个Segment进行加锁,再计算一次元素的个数;
JDK1.7中的ConcurrentHashMap的size方法,计算size的时候会先不加锁获取一次数据长度,然后再获取一次,最多三次。比较前后两次的值,如果相同的话说明不存在竞争的编辑操作,就直接把值返回就可以了。但是如果前后获取的值不一样,那么会将每个Segment都加上锁,然后计算ConcurrentHashMap的size值。
JDK1.8
先利用sumCount()计算,然后如果值超过int的最大值,就返回int的最大值。但是有时size就会超过最大值,这时最好用mappingCount方法。sumCount有两个重要的属性baseCount和counterCells,如果counterCells不为空,那么总共的大小就是baseCount与遍历counterCells的value值累加获得的。
ConcurrentHashMap节点的数量= baseCount+counterCells每个cell记录下来的节点数量
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
SynchronizedMap和 ConcurrentHashMap 有什么区别?
SynchronizedMap 一次锁住整张表来保证线程安全,所以每次只能有一个线程来访为 map。
ConcurrentHashMap 使用分段锁来保证在多线程下的性能。一次锁住一个桶。ConcurrentHashMap 默认将hash 表分为 16 个桶,诸如get,put,remove 等常用操作只锁当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有 16 个写线程执行,并发性能的提升是显而易见的。
ConcurrentHashMap和HashTable的区别;
1. 底层数据结构:
JDK1.7 的 ConcurrentHashMap 底层采用 分段数组+链表 实现,而 JDK1.8 的 ConcurrentHashMap 实现跟 HashMap1.8 的数据结构一样,都是 数组+链表/红黑二叉树。
Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似,都是采用 数组+链表 的形式。数组是 HashMap 的主体,链表则是为了解决哈希冲突而存在的;
2. 实现线程安全的方式:
① 在 JDK1.7 的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段( Segment ),每一把锁只锁容器其中的一部分数据,这样多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高了并发访问率。 到了 JDK1.8,并发控制使用 synchronized 和 CAS 来操作
② Hashtable (同一把锁) : 使用 synchronized 来保证线程安全,效率非常低下。一个线程访问同步方法时,当其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程就不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈,效率就越低。
Hashtable
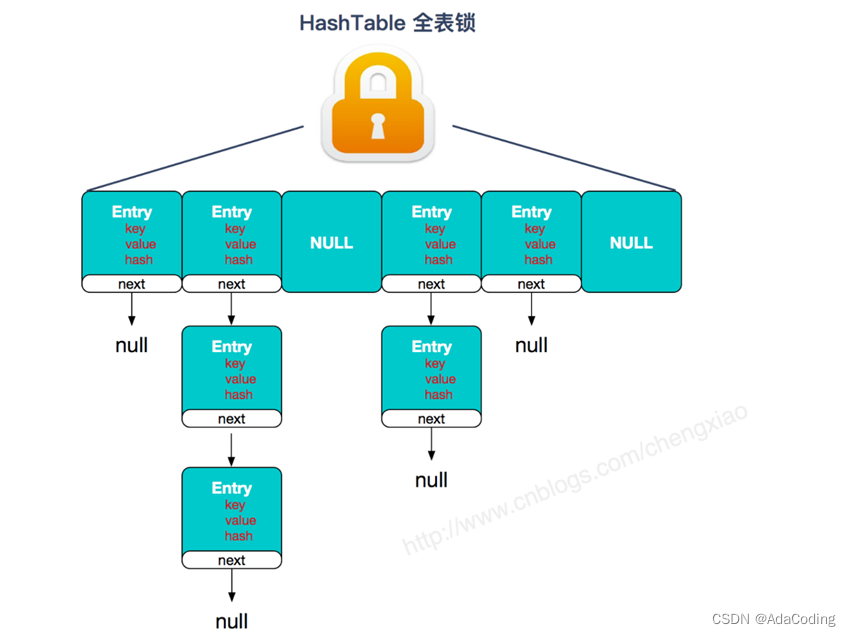
JDK1.7 的 ConcurrentHashMap
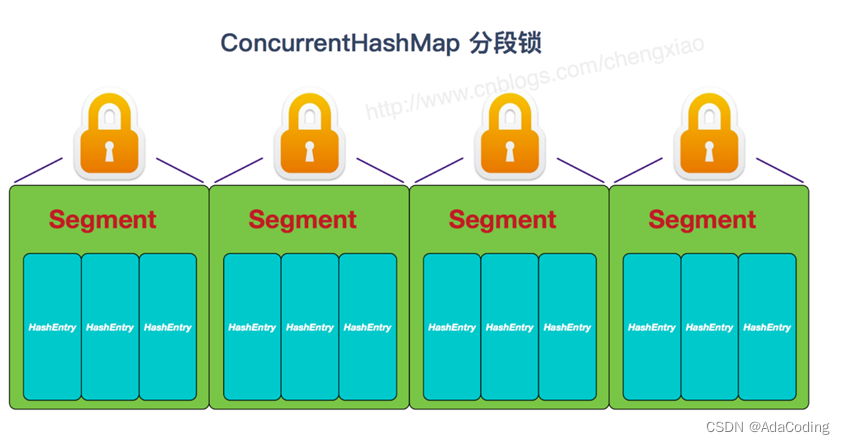
JDK1.8 的 ConcurrentHashMap(TreeBin: 红黑二叉树节点;Node: 链表节点)
ConcurrentHashMap 的并发度是多少?
在JDK1.7中,并发度默认是16,这个值可以在构造函数中设置。如果自己设置了并发度,ConcurrentHashMap 会使用大于等于该值的最小的2的幂指数作为实际并发度,也就是比如你设置的值是17,那么实际并发度是32。
ConcurrentHashMap 迭代器是强一致性还是弱一致性?
与HashMap迭代器是强一致性不同,ConcurrentHashMap 迭代器是弱一致性。
ConcurrentHashMap 的迭代器创建后,就会按照哈希表结构遍历每个元素,但在遍历过程中,内部元素可能会发生变化,如果变化发生在已遍历过的部分,迭代器就不会反映出来,而如果变化发生在未遍历过的部分,迭代器就会发现并反映出来,这就是弱一致性。
这样迭代器线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。想要深入了解的小伙伴,可以看这篇文章[为什么ConcurrentHashMap 是弱一致的](http://ifeve.com/ConcurrentHashMap -weakly-consistent/)
ConcurrentHashMap如何保证高效,为什么是线程安全,为什么比HashTable优秀,分段锁机制;
ConcurrentHashMap原理,1.7和1.8的区别,put,get,size,扩容,
怎么保证线程安全的,为什么用synchronized,分段锁有什么问题,hash算法做了哪些优化
https://blog.csdn.net/Mind_programmonkey/article/details/111035733
1. ConcurrentHashMap原理
JDK7,Java使用了分段锁机制实现ConcurrentHashMap。简而言之,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,它通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。
concurrencyLevel: Segment 数(并行级别、并发数)。默认是 16,也就是说 ConcurrentHashMap 有16个Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
JDK1.7
ConcurrentHashMap是一个Segment数组,Segment通过继承ReentrantLock来进行加锁,所以每次需要加锁的操作锁住的是一个segment,这样只要保证每个Segment是线程安全的,也就实现了全局的线程安全。
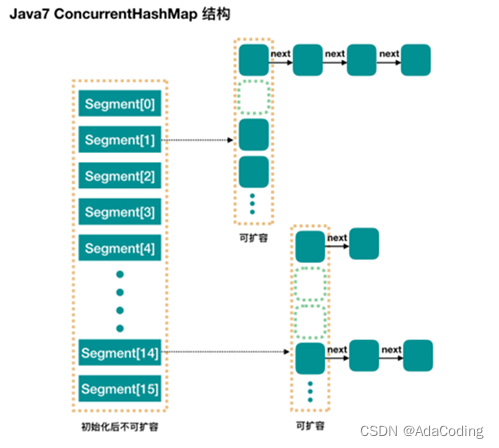
缺点:在于分成很多段时会比较浪费内存空间(不连续,碎片化); 操作map时竞争同一个分段锁的概率非常小时,分段锁反而会造成更新等操作的长时间等待; 当某个段很大时,分段锁的性能会下降。
JDK1.8
ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
为什么不用ReentrantLock而用synchronized ?
- 减少内存开销:如果使用ReentrantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要进行同步。
- 内部优化:synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。
2. ConcurrentHashMap线程安全
在JDK1.7之前ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
ConcurrentHashMap JDK1.7: 使用分段锁机制实现;
ConcurrentHashMap JDK1.8:则使用数组+链表+红黑树数据结构和CAS原子操作实现;
3. ConcurrentHashMap 扩容
https://segmentfault.com/a/1190000021237438
扩容的时机
put()添加元素完毕后,通过 addCount() 检查元素总量 size 是否超过阈值 sizeCtrl。putAll()添加大量元素之前,通过 tryPresize() 检查是否需要扩容。treeifyBin()桶中元素由链表转成树结构之前,如果数组容量小于 64(MIN_TREEIFY_CAPACITY),放弃转换红黑树,通过 tryPresize() 检查是否需要扩容。put()、computeIfAbsent()、computeIfPresent()等方法操作 HashMap 元素时,发现元素节点类型为 ForwardingNode,则通过 helpTransfer() 检查当前线程是否加入扩容。
JDK1.7扩容
segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] table进行扩容,扩容后,容量为原来的 2 倍。
每个Segment对象相当于一个HashMap,扩容是仅限于本Segment,也就是对应的HashMap进行扩容,支持多线程扩容的。每个Segment内部的扩容逻辑和HashMap中一样。
JDK1.8扩容
https://shuyi.tech/archives/con-col-02-concurrent-hashmap-resize

table数组的扩容,一般是新建一个2倍大小的数组,这个过程由一个单线程完成,不允许并发操作;数据迁移,可多线程操作。在扩容的过程中,如果有其他线程在put,那么这个put线程会帮助去进行元素的转移,虽然叫转移,但是其实是基于原数组上的Node信息去生成一个新的Node,也就是原数组上的Node不会消失,因为在扩容的过程中,如果有其他线程在get也是可以的。
transfer()方法分析
transfer()方法是真正的扩容方法,会创建一个容量为原数组容量的2倍的新node数组,并且将原数组的元素迁移到新的数组中,并且把新的数组赋值给成员变量table。
concurrentHashMap支持多线程参与数据的迁移,首先计算每个线程负责的数据迁移的范围, 迁移的时候会把当前迁移的node修改为ForwardingNode,(其他线程判断当前节点如果是ForwardingNode节点,就跳过,避免重复迁移。)然后分别针对链表和红黑树两种情况进行数据的迁移。
1.链表:
遍历链表计算每个节点在新数组的下标位置,计算出的结果只有两种情况
- a.计算出的新数组下标和原数组下标位置一样
- b.计算出的新数组下标为(原数组下标 + 原数组的容量)
如果是a情况,将数据存在低位链表,如果是b情况存在在高位链表,然后赋值在新数组对应的下标位置。
2.红黑树:
遍历红黑树,计算每个节点在新数组的下标位置,计算的结果也是一样的两种结果 如果是a情况,将数据存在低位树,如果是b情况存在在高位树,如果高位树或低位树的长度小于6,那么将高位树或低位树为链表,然后分别赋值到新数组中
扩容 transfer 方法很难!!!
4. ConcurrentHashmap怎么算size
因为ConcurrentHashMap是可以并发插入数据的,所以在准确计算元素时存在一定的难度,一般的思路是统计每个Segment对象中的元素个数,然后进行累加,但是这种方式计算出来的结果并不一样的准确的,因为在计算后面几个Segment的元素个数时,已经计算过的Segment同时可能有数据的插入或则删除。
JDK7
在1.7的实现中,采用了如下方式:
先采用不加锁的方式,连续计算元素的个数,最多计算3次:
1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;
2、如果前后两次计算结果都不同,则给每个Segment进行加锁,再计算一次元素的个数;
JDK8
先利用sumCount()计算,然后如果值超过int的最大值,这时最好用推荐的mappingCount方法,返回值是long类型。sumCount有两个重要的属性baseCount和counterCells,如果counterCells不为空,那么总共的大小就是baseCount与遍历counterCells的value值累加获得的。
ConcurrentHashMap节点的数量= baseCount+counterCells每个cell记录下来的节点数量
在没有并发的情况下,使用一个 baseCount volatile 变量就足够了,当并发的时候,CAS 修改 baseCount 失败后,就会使用 CounterCell 类了,会创建一个这个对象,通常对象的 volatile value 属性是 1。在计算 size 的时候,会将 baseCount 和 CounterCell 数组中的元素的 value 累加,得到总的大小,但这个数字仍旧可能是不准确的。
//返回int
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 : (n > (long) Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) n);
}
final long sumCount() {
CounterCell[] as = counterCells;
CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null) sum += a.value;
}
}
return sum;
}
//返回long
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
5. ConcurrentHashMap的put方法
https://juejin.cn/post/7045955943296679949
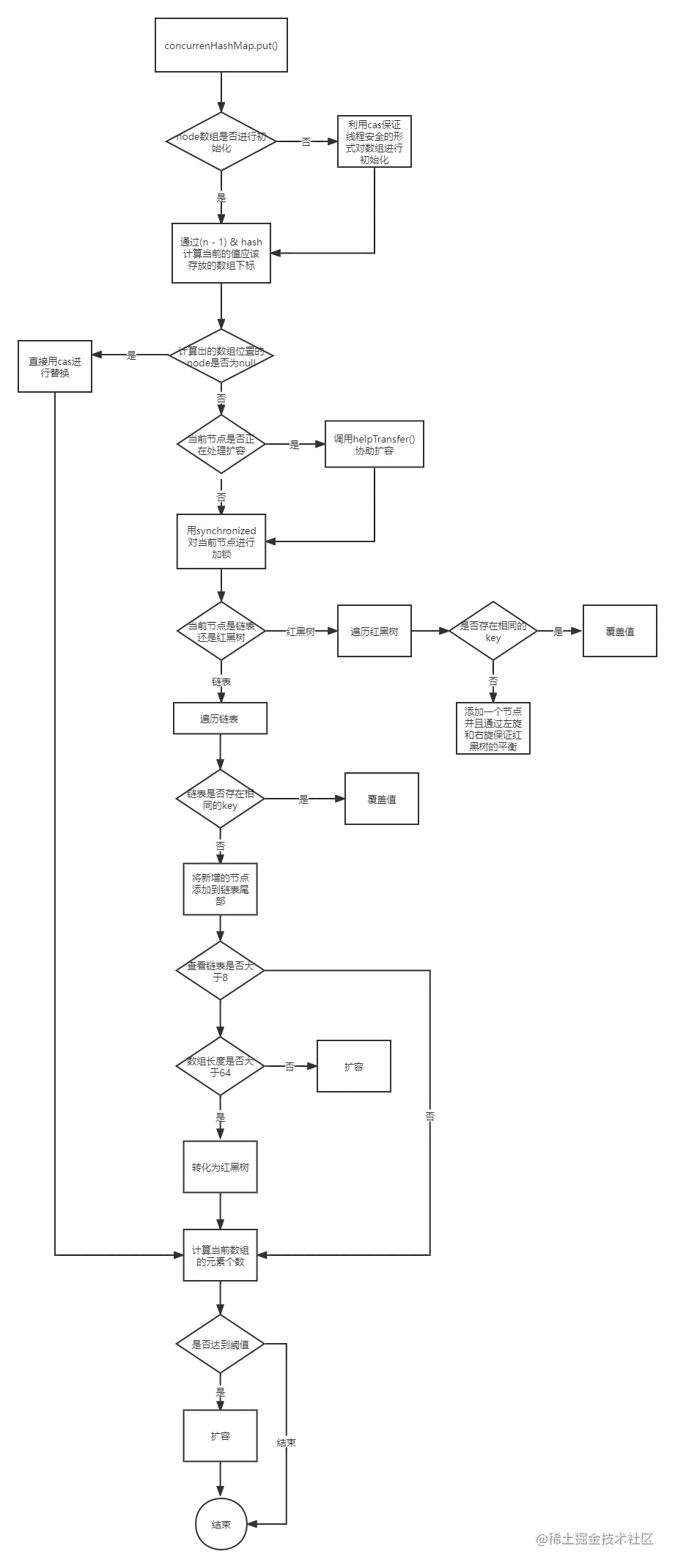
put()方法会调用putVal()方法:
-
如果当前数组没有初始化那么会先调用initTable()方法初始化数组;
-
然后根据计算好的数组下标查看当前下标下是否为null,如果是null,那么利用cas保证线程安全直接进行替换;如果不是null,那么需要解决hash冲突的问题,分链表和红黑树两种情况分别进行处理。
- a.链表:遍历链表,如果有相同的key 进行覆盖的操作;否则添加到链表的尾部(尾插法),添加完元素之后判断链表的长度是否大于等于8,大于8 那么会调用treeifyBin()方法。
- b.红黑树:遍历红黑树,如果有相同的key,进行覆盖操作;如果没有,那么构建红黑树的节点添加到红黑树,并且通过左旋或者右旋保证红黑树的平衡。
-
最后调用addcount()计算数组的总元素个数。
final V putVal(K key, V value, boolean onlyIfAbsent) {
//键和值都不能为空 否则抛出空指针异常
if (key == null || value == null) throw new NullPointerException();
//计算key的hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
//1 如果tab 为空 那么需要先初始化数组
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//2 通过 tabAt 方法查询当前数组下标位置是否有值,如果没有值,接用cas进行替换即可
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
//3 MOVED 如果在进行扩容,则先进行扩容操作
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//onlyIfAbsent true表示不能覆盖原有的值 默认是false
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
//如果存在相同的key 并且value不为空 直接返回已存在的值
return fv;
// 4 就是把元素放入槽内
//如果以上条件都不满足,那就要进行加锁操作,也就是存在hash冲突,锁住链表或者红黑树的头结点
else {
V oldVal = null;
//针对node进行加锁
synchronized (f) {
if (tabAt(tab, i) == f) {
// fh>=0,表示当前table下标为 i 的位置是个链表
if (fh >= 0) {
// binCount 用于记录链表长度,后面判断转化为红黑树时会用到
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//遍历链表 如果存在有相同的key 而且允许被覆盖 那么直接覆盖原有的值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//遍历到链表的尾部 证明是尾插法添加链表节点
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
// 如果f是红黑树结构 ,就需要将节点put进红黑树了
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
//也就是存在key相同的并且允许被覆盖就覆盖旧的值 不然就根据红黑树的规则添加到树中
//putTreeVal() 解决hash冲突的逻辑和链表一样 但是会涉及到树的左旋和右旋
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
//查看链表长度是否达到了树化的阈值(默认是8)
//这里并不是说达到了阈值就会树化,而是要满足数组长度大于64而且链表长度大于等于阈值两个条件才会树化 否则会先进行扩容来减少链表的长度
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 总元素个数累加1,统计size,并且检查是否需要扩容
addCount(1L, binCount);
return null;
}
6. ConcurrentHashMap的get方法
- 计算 hash 值,根据 hash 值找到数组中对应位置: (n - 1) & h
- 根据该位置处结点性质进行相应查找
- 如果该位置为 null,那么直接返回 null ;
- 如果该位置处的节点刚好就是我们需要的,返回该节点的值;
- 如果该位置节点的hash值小于 0,说明正在扩容,或者是该位置是红黑树,后面我们再介绍 find 方法
- 如果以上 3 条都不满足,那就是链表,进行遍历比对即可
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 1 判断头节点是否就是我们需要的节点
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 2 如果头节点的 hash 小于 0,说明 正在扩容,或者该位置是红黑树
else if (eh < 0)
// 参考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k)
return (p = e.find(h, key)) != null ? p.val : null;
// 如果以上 3 条都不满足,那就是链表,进行遍历比对即可
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
hashmap中如何优化哈希算法
这里,其实分了3个步骤:
- 计算hashcode,作为操作数1
h = key.hashCode() - 将第一步的hashcode,右移16位,作为操作数2
h >>> 16 - 操作数1 和 操作数2 进行异或操作,得到最终的hashcode
//java7的下标算法
/**
* 根据key计算hashcode,计算完之后进行散列处理
* 避免与数组长度进行或运算时,总是得到相同的值
*/
final int hash(Object k) {
int h = hashSeed;
// if (0 != h && k instanceof String) {
// return sun.misc.Hashing.stringHash32((String) k);
// }
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//java8的下标算法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
ConcurrentHashMap中如何优化哈希算法
https://www.cnblogs.com/grey-wolf/p/13069173.html
在concurrentHashMap中,其主要是
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
这里主要是使用spread方法来计算hash值:
这里和HashMap相比,多了点东西,也就是多出来了:
& HASH_BITS;
这个有什么用处呢?
因为(h ^ (h >>> 16))计算出来的hashcode,可能是负数。这里,和 HASH_BITS进行了相与:
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
1111 1111 1111 1111 1111 1111 1111 1111 假设计算出来的hashcode为负数,因为第32位为1 0111 1111 1111 1111 1111 1111 1111 1111
0x7fffffff 进行相与 0111 ..................................
这里,第32位,因为0x7fffffff的第32位,总为0,所以相与后的结果,第32位也总为0 ,所以,这样的话,hashcode就总是正数了,不会是负数
ConcurrentHashMap和hashtable区别,都能实现同步线程安全,ConcurrentHashMap好在哪?怎么实现的
更多后端全部八股点击👉👉【闲鱼】https://m.tb.cn/h.5yHpgkY?tk=O8bhWpn1NBD CZ8908 「我在闲鱼发布了【京985计算机硕士自用后端八股文出售,不同于市面上的几块钱八】」
点击链接直接打开
Java后端各科最全八股自用整理,获取方式见:
整理不易🚀🚀,关注和收藏后拿走📌📌欢迎留言🧐👋📣
欢迎专注我的公众号AdaCoding 和 Github:AdaCoding123

















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









