







一、概述
- 数据的存储可以使用数据库,也可以使用文件。
- 数据库保持了数据的完整性和关联性,且使用数据更安全、可靠。而使用文件存储数据则非常简单、易用,如果要处理得数据结构不复杂,则不必安装数据库管理系统等运行环境,使用文件系统即可。
- Python提供了os、os.path、shutil、pickle等模块处理文件。
1、什么是文件
- 文件是存储在外部存储介质(如:硬盘、U盘、闪存条等)中的数据集合。
- 文件名格式:
主文件名[. 扩展名]
例如:程序文件中保存着程序,数据文件中保存着数据(如案例1中的example1.py是程序文件,AddressBook.txt是数据文件。
2、文件的分类
(1)根据文件依附介质
根据文件依附的介质,可分为普通文件和设备文件。
- 普通文件:存储在外部存储介质上的文件。
- 设备文件:如显示器、键盘。
(2)根据文件的组织方式
根据文件的组织方式,可分为顺序读写文件和随机读写文件。
- 顺序读写文件:按照文件所存储的数据的顺序从头到尾进行访问。
- 随机读写文件:存储的数据通常是有结构的,每条数据记录长度相等,因此可以通过计算直接访问文件中的特定记录。
(3)根据文件的存储形式
根据文件的存储形式,可分为文本文件(ASCII码文件)和二进制文件。
例如:将整数32767分别存储在这两种数据文件中。

(4)按照操作系统对磁盘文件的读写方式
- 按照操作系统对磁盘文件的读写方式,文件系统可分为:
- 缓冲文件系统
- 非缓冲文件系统
- 缓冲区:为了提高程序访问文件的速度而开辟的一块内存。
- Python语言的文件处理函数:
- 带缓冲区的标准I/O函数
- 不带缓冲的系统I/O函数
3、标准I/O函数的执行过程

4、文本文件和二进制文件的特点
(1)文本文件特点
- 基本是字符串,不包括诸如字体、字号、颜色等信息。Python源代码文件和HTML文件等都属于文本文件。
- 可使用任何文本编辑器进行编辑,对人来说相对容易阅读和修改。
- 对程序来说,无法直接阅读文本文件。通常,每种文本文件都需要使用相应的分析程序来阅读,例如,Python使用专用分析程序来帮助阅读.py文件,而要阅读HTML文件,需要使用专用于HTML的分析程序。
- 通常比等价的二进制文件大。需要通过网络发送大型文本文件时,一般要进行压缩(如压缩成zip格式),以提高传输速度和节省磁盘空间。
(2)二进制文件的特点
- 通常是人无法直接阅读的,且使用常规的文本编辑器无法查看。在文本编辑器中打开二进制文件时,显示的是一堆乱码。有些类型的二进制文件(如JPEG图像)需要使用特殊查看器显示其内容。如Word文档、PDF、图像和可执行程序等。
- 占据的空间通常比等价的文本文件小。
- 对程序来说,可以直接阅读二进制文件。虽然二进制文件各不相同,但通常无需编写复杂的分析程序来读取它们。
二、文件的常见操作
- 打开文件
- 建立磁盘上的文件与程序中的文件对象相关联
- 文件操作
- 读取、写入
- 复制、删除
- 定位
- 其他:追加、计算等
- 关闭文件
- 切断文件与程序的联系
- 写入磁盘,并释放文件缓冲区
1、文件的创建
- 文件的打开或创建可以使用open函数。该函数可以指定处理模式,设置打开的文件为只读、只写或可读写状态。
- 格式1:
open(file, [mode[, buffering]])—>file object - 格式2:
上下文管理器(context manager)方式:
with open(file, [mode[, buffering]]) as file object name
说明:
- 参数file是被打开的文件名。若文件file不存在,open()将创建该文件,然后再打开该文件。
- 参数mode是指文件的打开模式(默认r)。打开模式如表8-1。
- 参数buffering设置缓存模式。0表示无缓冲;1表示行缓冲;如果大于1则表示缓冲区的大小,,-1(或者任何负数,默认为-1)代表使用默认的缓冲区大小。以字节为单位。
- open()返回1个file对象,file对象可以对文件进行各种操作。
表8-1:文件的打开模式(mode)

关于file类:
- file类用于文件管理,可以对文件进行创建、打开、读写、关闭等操作。
- 文件的处理一般分为三个步骤:
- 创建并打开文件,使用open()函数返回1个file对象。
- 调用file对象的read()、write()等方法处理文件。
- 调用close()方法关闭文件,释放file对象占用的资源(若使用格式2,可省略此步骤)。
表8-2:file类的常用属性和方法
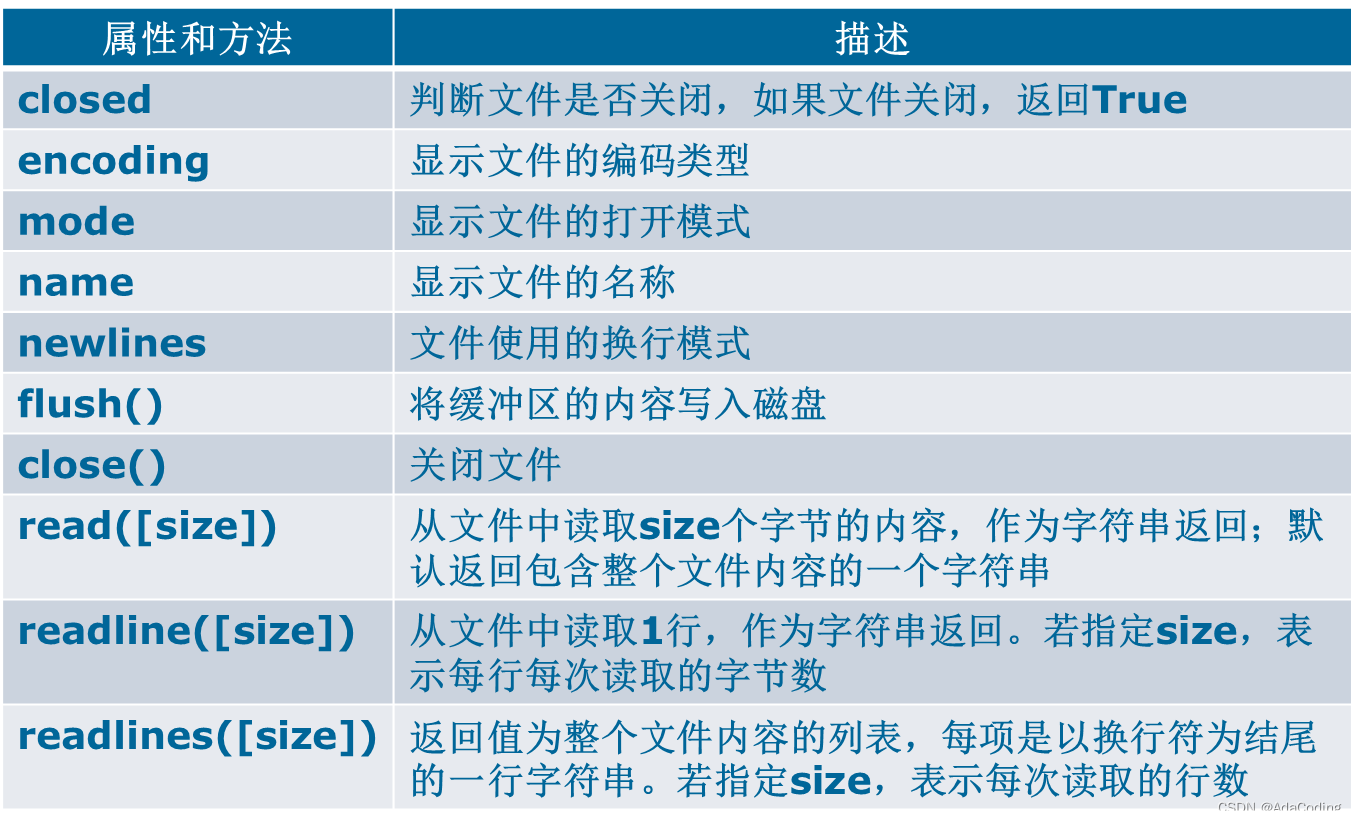
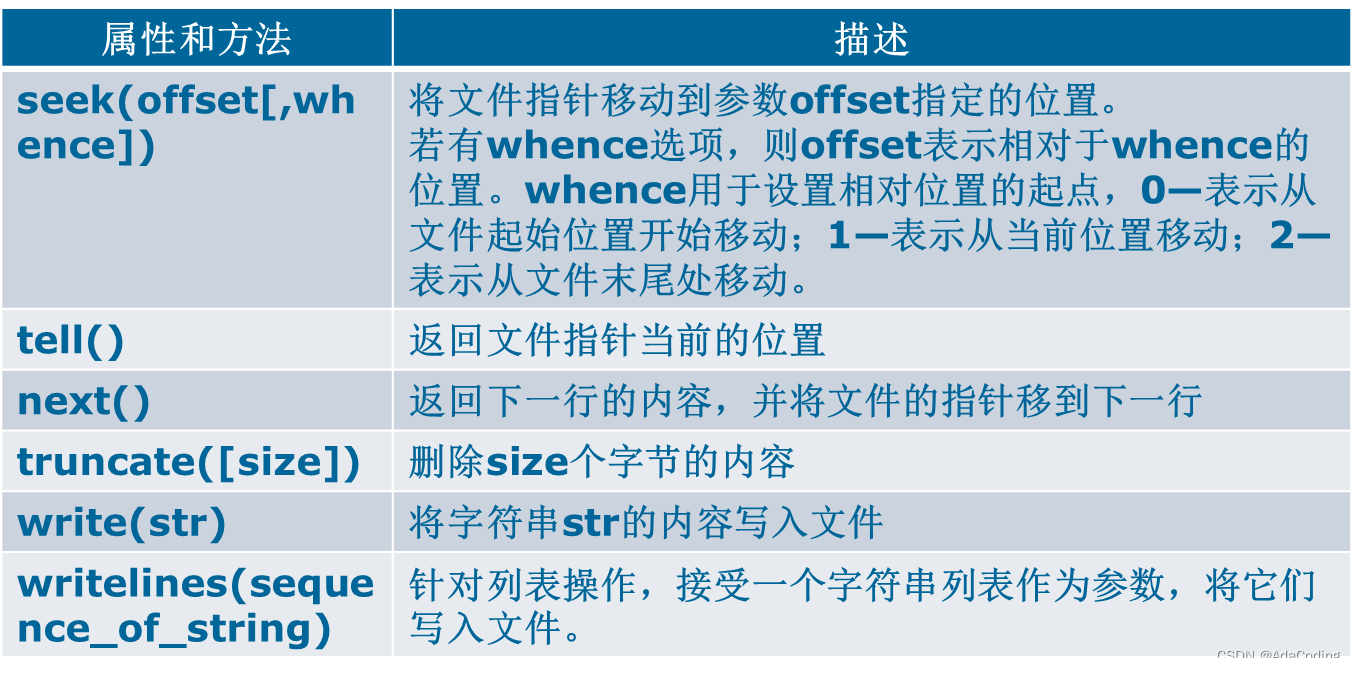
说明:
- 文件的顺序读写是指打开文件后,按照从前向后的顺序依次进行数据的读/写操作;而随机读写可以直接使文件指针指向某个位置,并对该位置的数据进行读/写操作,即读/写数据的位置不按固定顺序、可以随机指定。
- 当以文本方式打开文件后,只支持以文件首作为参照位置进行文件指针的移动;而以二进制方式打开文件后,可以支持全部的三种参照位置。通过seek方法实现的文件随机读写主要用于二进制文件。
例8-1:文件的创建、写入和关闭(方式一)


方式二:


例8-2:在文件尾添加内容


2、文件的读取
文件的读取有三种方法,包括:
- readline()
- readlines()
- read()
(1)按行读取方式readline()
- readline()每次读取文件中的一行,需要使用永真表达式循环读取文件。但当文件指针移动到文件的末尾时,依然使用readline()读取文件将出现错误。因此程序中需要添加1个判断语句,判断文件指针是否移动到文件的尾部,并且通过该语句中止循环。
例8-3:使用readline()读文件


(2)多行读取方式
- 函数readlines()可一次性读取文件中多行数据。例如:readlines(2),可读入两行数据。
- 使用readlines()读取文件,需要通过循环访问readlines()返回的内容。
例8-4:使用readlines()读文件

(3)一次性读取方式
- 读取文件最简单的方法是使用read(),read()将从文件中一次性读出所有的内容,并赋值给1个字符串变量。
- 但这种方式占内存最大。
- 若read()带有参数,则读入指定字节数。例如,read(5),读入5个字节的数据。
例8-5:使用read()读文件


例8-6:使用read()返回指定字节的内容



3、文件的写入
- 从计算机内存向文件写入数据。
- 可以使用write()、writelines()方法写入文件。
- 例8-1使用write()方法将字符串写入文件,而writelines()方法可将列表中存储的字符串序列写入文件。
例8-7:使用writelines()写文件


将字符串插入到文件开头:
- 相比在文件末尾添加字符串,将字符串写入文件开头不那么容易,因为操作系统没有提供这样的支持。
- 解决的方法是:将文件读取到一个字符串中,将新文本插入到该字符串,再将这个字符串写入原来的文件。
例8-8:将字符串插入到文件开头


例8-9:
将文件companies.txt 的字符串前加上序号1、2、3、…后写到另一个文件scompanies.txt中。

源程序:

4、文件的删除
- 删除文件需要使用os模块和os.path模块。
- os模块提供了对系统环境、文件、目录等操作系统级的接口函数。
- 表8-3列出了os模块常用的文件处理函数。
- 注意:os模块的open()函数与内置的open()函数的用法不同。
表8-3:os模块常用的文件处理函数

表8-4:os.path模块常用函数
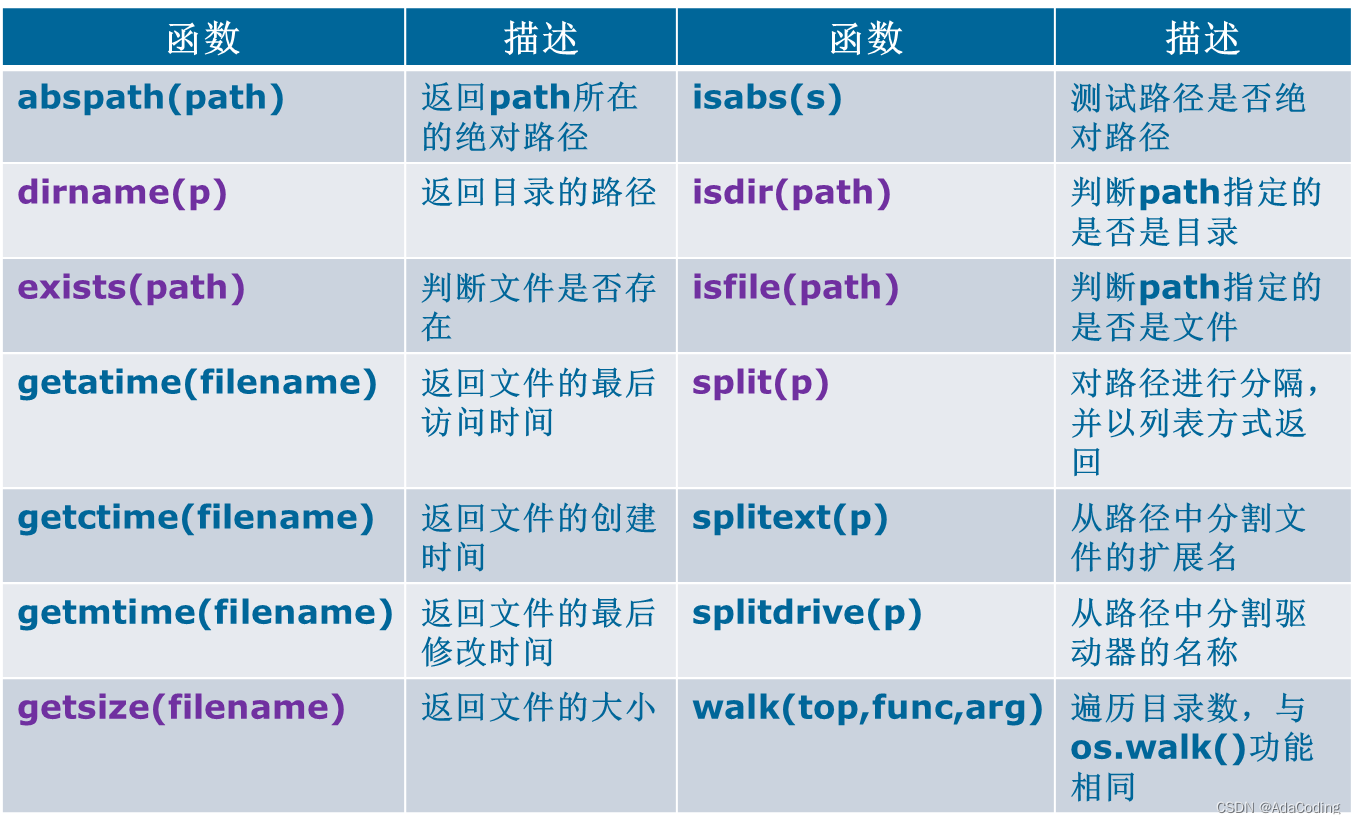
例8-10:文件的删除

5、文件的复制
- file类并没有提供直接复制文件的方法,但可以使用read()、write()方法来实现复制文件的功能。
例8-11:用read()、write()实现文件复制

复制文件的其他方法:
- shutil模块是另一个文件、目录的管理接口,提供了一些用于复制文件、目录的函数。
- 其中,copyfile()函数可以实现文件的复制,move()函数可以实现文件的移动。
copyfile(src, dst)
move(src, dst)
- 其中,参数src表示源文件的路径,dst表示目标文件的路径,均为字符串类型。
例8-12:使用shutil模块实现文件的复制和移动

6、文件的重命名
- os模块的函数rename()可以对文件或目录进行重命名。
- 在实际应用中,经常需要将某一类文件修改为另一种类型,即修改文件的后缀名。可以通过函数rename()和字符串查找函数来实现。
例8-13:修改文件名

例8-14:批量修改文件的扩展名

7、文件内容的搜索和替换
- 文件内容的搜索和替换可以使用字符串查找和替换来实现。
- 例8-15:从hello.txt文件中统计字符串’hello’出现的次数。
程序及执行结果:


例8-16:将hello.txt中的字符串’hello’全部替换为’hi’,并将结果存入hello2.txt中

8、处理二进制文件
- python中,通常使用struct和pickle模块处理二进制文件。
- 可以使用struct.pack、pickle.dump将数据结构存储到磁盘,之后再用struct.unpack、pickle.load从磁盘获取数据结构。
- struct和pickle不能用于读写特殊格式的二进制文件,如各种格式的图像文件。对这种格式的文件,要用专用模块处理(如:PIL库)。
(1)用struct模块读写二进制文件

格式表

例如:pack和unpack应用

例8-17:使用pack方法将一个整数、一个浮点数和一个布尔型对象存入一个二进制文件中

例8-18:使用unpack方法读取file2.dat的内容


(2)用pickle模块读写二进制文件
- pickle.dump(obj, file)可对任意Python对象格式化,并将结果数据流写入到文件对象中。
- pickle.load(file)—解格式化对象。将文件中的数据解析为一个Python对象。
例如:dump和load应用

例8-19:使用dump方法将一个整数、一个浮点数和一个布尔型对象存入一个二进制文件中

例8-20:使用load方法读取file4.dat内容


例8-21:二进制文件存取
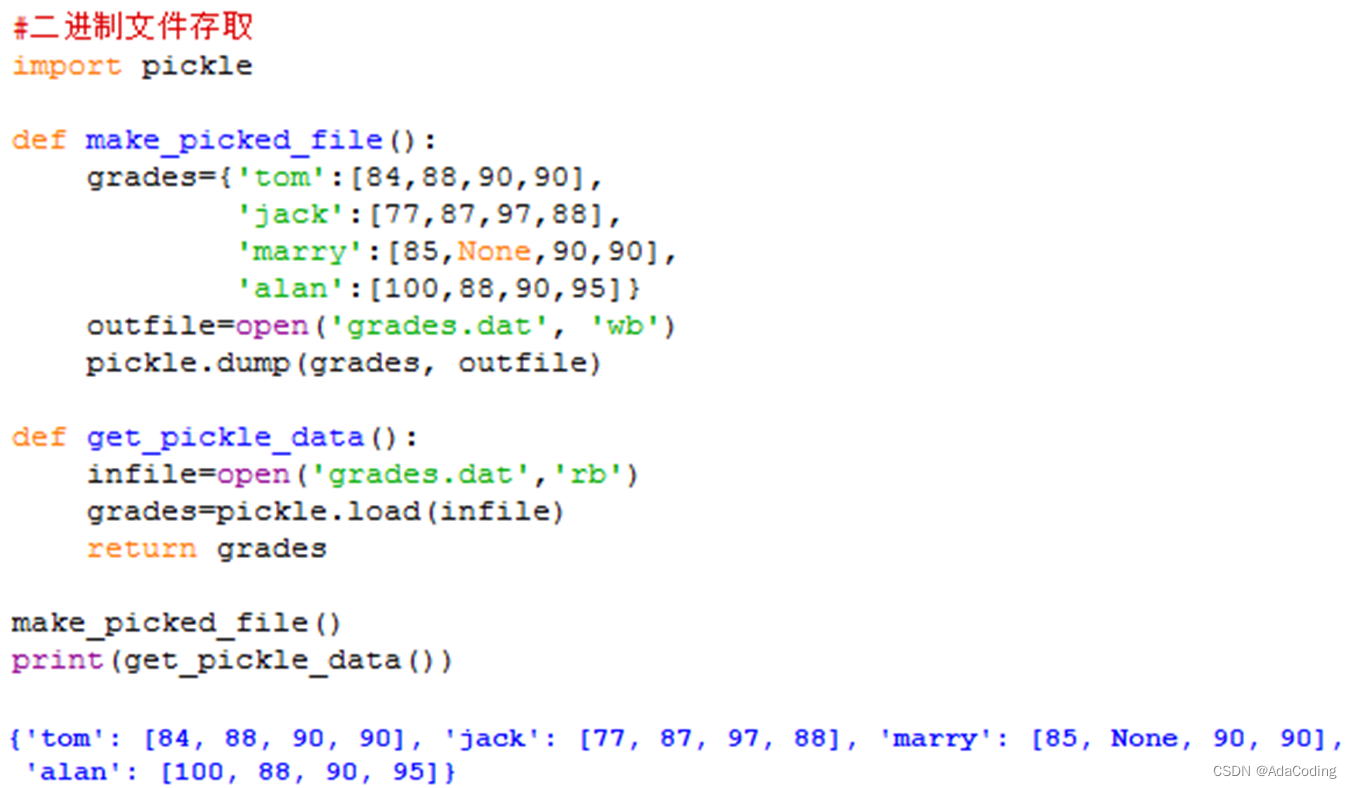
9、其他持久化模块简介(选学)
- shelve(内置)
- csv(内置)
- openpyxl(第三方库,需安装)
(1)shelve模块简介
- 可将对象保存到文件里面,缺省(即默认)的数据存储文件是二进制的。
- 提供基本的存储操作,通过构造一个简单的数据库,像操作字典一样按照键存储和获取本地的Python对象,使其可以跨程序运行而保持持久化。可以作为一个简单的数据存储方案。
- 键—必须是字符串,且是唯一的
- 值—任何类型的Python对象
常用操作:
- 将任何数据对象,保存到文件中去
d = shelve.open(filename)- open函数在调用时返回一个shelf对象,通过该对象可以存储内容
- 类似字典形式访问,可读可写
d[key] = data
value = d[key]
del d[key]
- 操作完成后,记得关闭文件
d.close()
例8-22:shelve模块应用
创建shelve对象(类字典对象)

访问shelve对象:


对shelve对象的增、删、改操作:

循环遍历shelve对象:


(2)处理结构化文本文件—csv模块
- csv模块是处理csv文件的内置模块,csv是Comma-Separated Values的缩写,是一种国际通用的一维、二维数据存储格式,其对应文件的扩展名为.csv,可使用Excel软件直接打开。
- 是用文本文件形式储存的表格数据,其特点为:
- 值没有类型,所有值都是字符串
- 不能指定字体颜色等样式
- 不能指定单元格的宽高,不能合并单元格
- 没有多个工作表
- 不能嵌入图像图表
csv模块读操作:
- 文件读取—reader
re = csv.reader()- 接受一个可迭代对象(比如csv文件),能返回一个生成器,可以从其中解析出内容
- 文件读取—DictReader
re = csv.DictReader()- 与reader类似
- 但返回的每一个单元格都放在一个元组内
csv模块写操作:
- 文件写操作
- 当文件不存在时,自动生成
- 支持单行写入和多行写入
w = csv.writer()
w.writerrow(row)
w.writerows(rows)
- 字典数据写入
w = csv.DictWriter()
w.writeheader()
w.writerow(row)
w.writerows(rows)
例8-23:csv模块应用
有如下表格数据:

存储为csv格式文件为(文件名:test_csv.csv):

用reader读文件:


用DictReader读文件:


用DictReader读取csv的某一列,可以用列的标题查询


写文件—向csv文件中写入一行新数据


使用二维列表处理csv文件:
- 处理CSV文件,可以不使用CSV模块,用Python的二维列表也可以处理。
- 创建CSV格式文件:可将二维列表对象输出为CSV格式文件。方法为:采用遍历循环和字符串的join()方法相结合。
- 读取CSV格式文件:从CSV格式文件读入二维数据,并将其表示为二维列表对象。
例8-24:用二维列表处理CSV文件
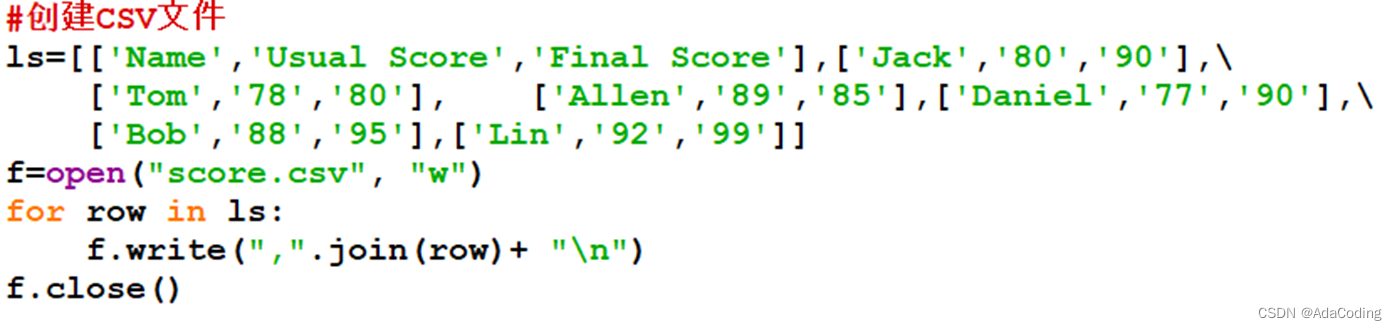

(3)处理结构化文本文件—openpyxl模块
- openpyxl模块
- 用来读写扩展名为xlsx/xlsm/xltx/xltm的文件
- Workbook类是对工作簿的抽象
- Worksheet类是对表格的抽象
- Cell类是对单元格的抽象
- 操作之前先导入第三方库
- 安装: pip install openpyxl
- 导库: from openpyxl import workbook
创建Excel文件
- 一个Workbook对象代表一个Excel文档,使用该方法创建一个Worksheet对象后才能打开一个表。操作为:
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
读取Excel文件
from openpyxl import load_workbook
wb = load_workbook(filename)
ws = wb.active
获取单元格信息
- 获取Cell对象
c = wb[‘sheet’][‘A1’]
c = wb[‘sheet’].cell(row=1,column=1)
- c.coordinate : 返回单元格坐标
- c.value : 返回单元格的值
- c.row : 返回单元格所在的行坐标
- c.column : 返回单元格所在列坐标
例8-25:openpyxl模块应用
有如下Excel文件,文件名为test_xls.xlsx。

读取excel文件内容:


将数据写入excel文件:


课堂练习:
课堂练习
三、OS模块的使用
- 通过os模块及os.path模块可以方便地使用操作系统的相关功能。
- 使用之前,需要先通过“import os”或“import os.path”将其导入。
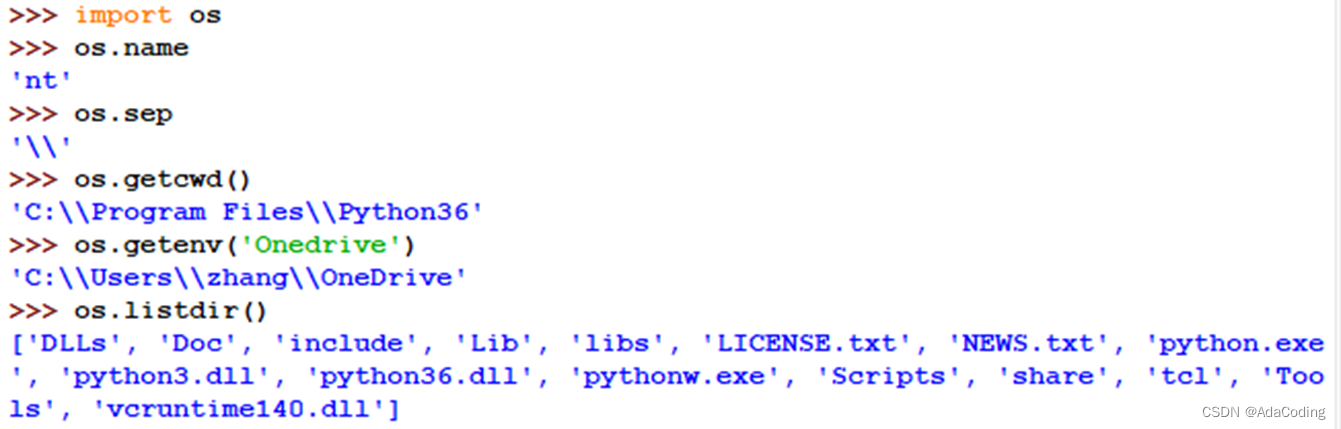
1、基础操作

例如:
2、目录创建和删除

例如:

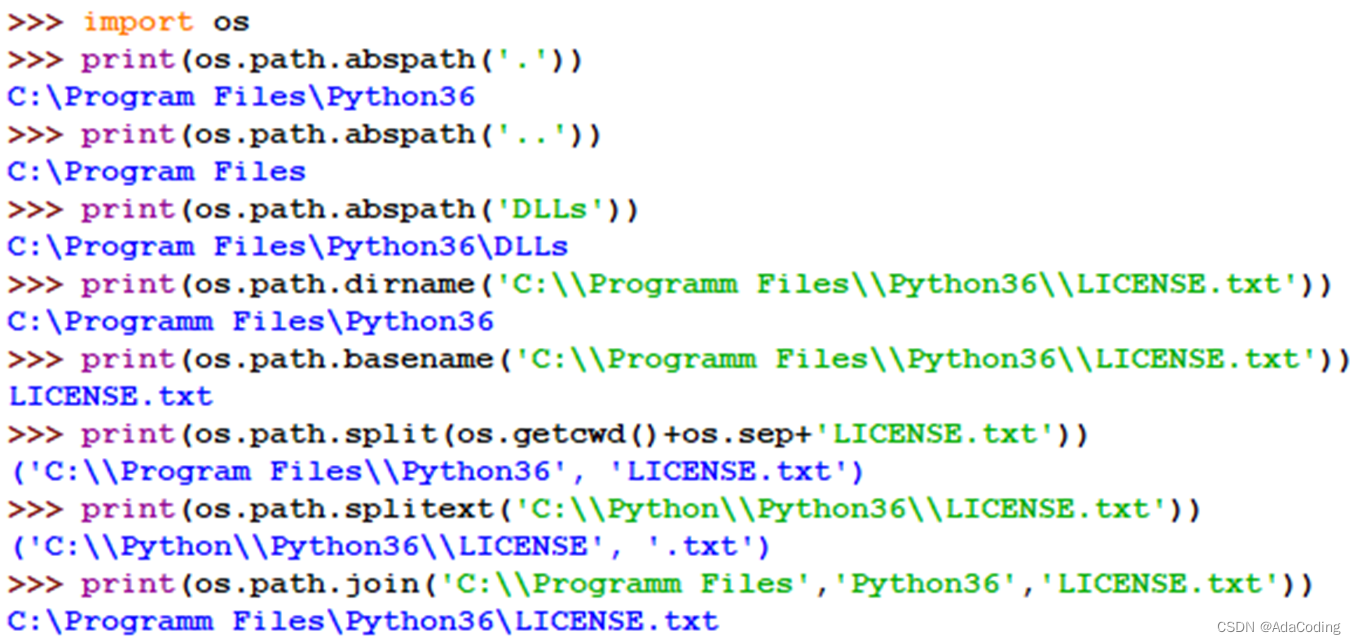
3、获取绝对路径、路径分离和连接
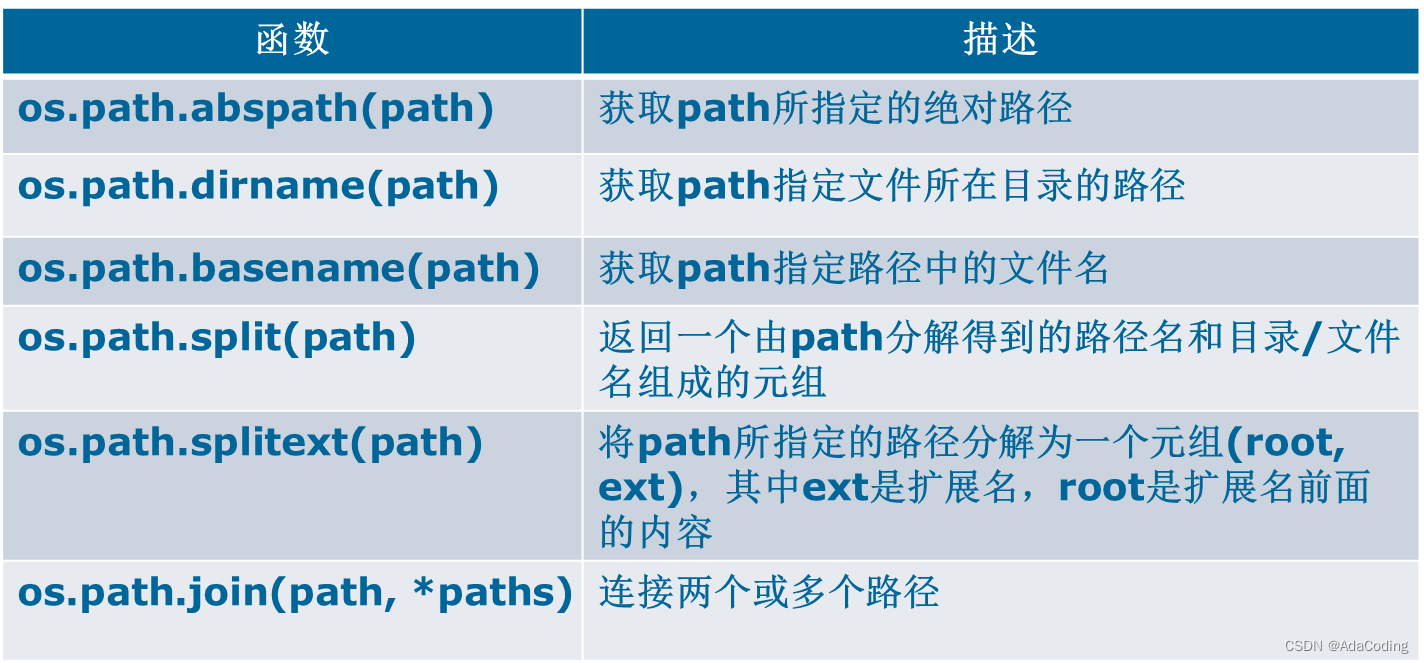
说明:
- 相对路径是指相对于当前工作目录指定的路径;
- “.”表示当前目录,而“…”表示上一层目录;
- 绝对路径是指从最顶层目录开始所给出的完整的路径;
- 编写程序时应尽量使用相对路径,这样当把编写好的程序从一台机器复制到另一台机器上时也可以正常运行;而如果使用绝对路径,则通常需要根据另一台机器的目录结构对程序中使用的所有绝对路径做修改,造成了工作量的增加。
例如:
4、其他有关操作
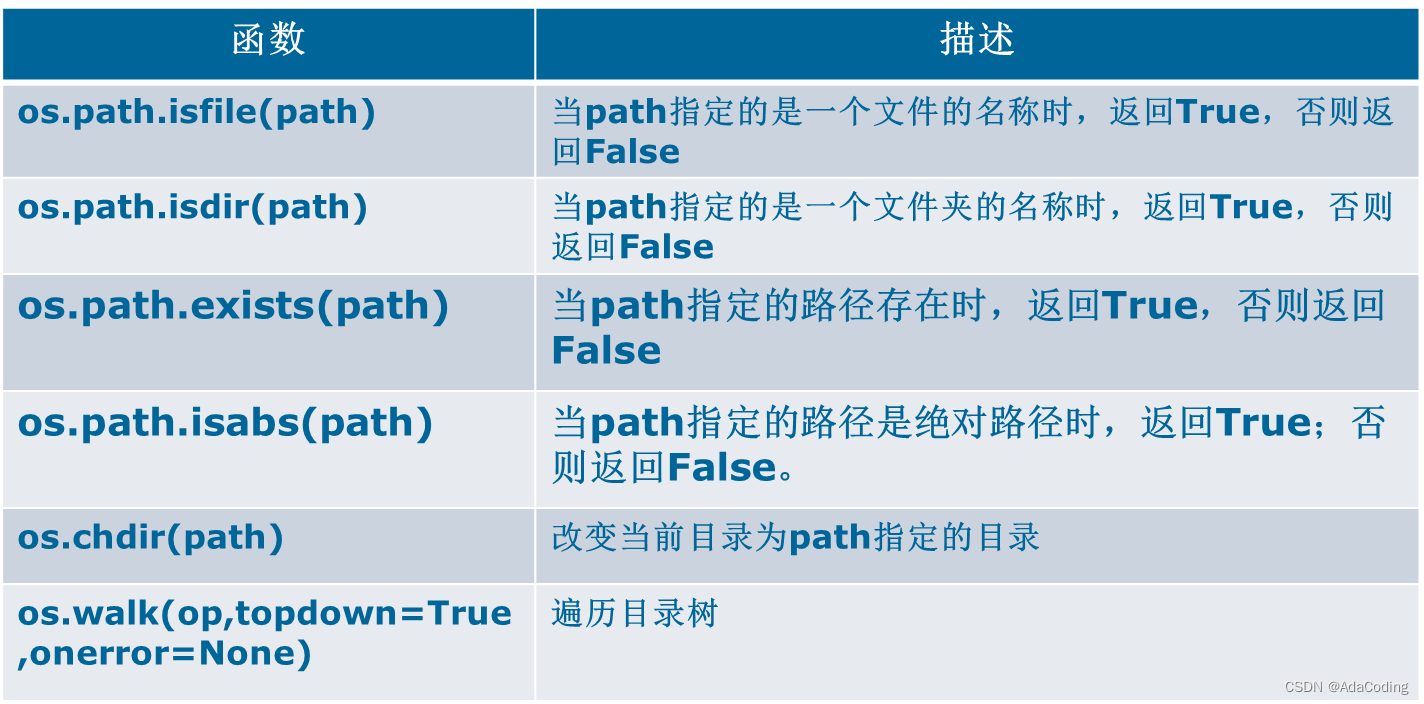
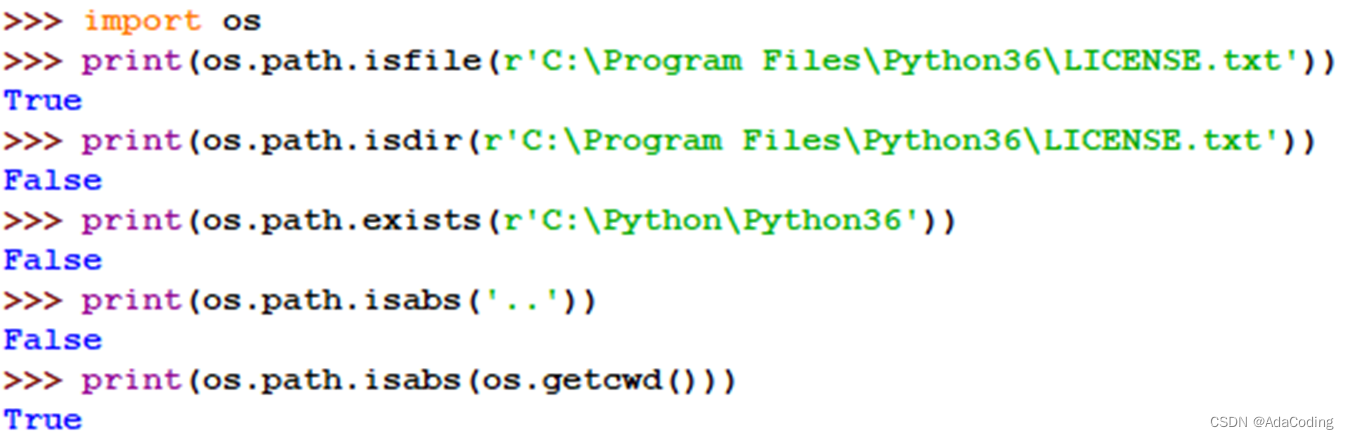
例如:
例8-26:用递归函数遍历目录d:\Python34\lib

执行结果:

例8-27:使用os.walk()遍历目录

说明:
- os.walk()返回的是一个三元组:tupple(dirpath, dirnames, filenames),
- 其中第一个为起始路径,第二个为起始路径下的文件夹,第三个是起始路径下的文件。若是多级目录,每循环一次,进入下一级目录,直到下级再无子目录为止;
- dirpath是一个string,代表目录的路径;
- dirnames是一个list,包含了dirpath下所有子目录的名字;
- filenames是一个list,包含了非目录文件的名字。这些名字不包含路径信息,如果需要得到全路径,需要使用 os.path.join(dirpath, name)。
例8-28:返回当前目录中的文件和文件夹

例8-29:返回当前目录或指定目录中的.py文件

例8-30:返回当前目录中所有文件的大小总和

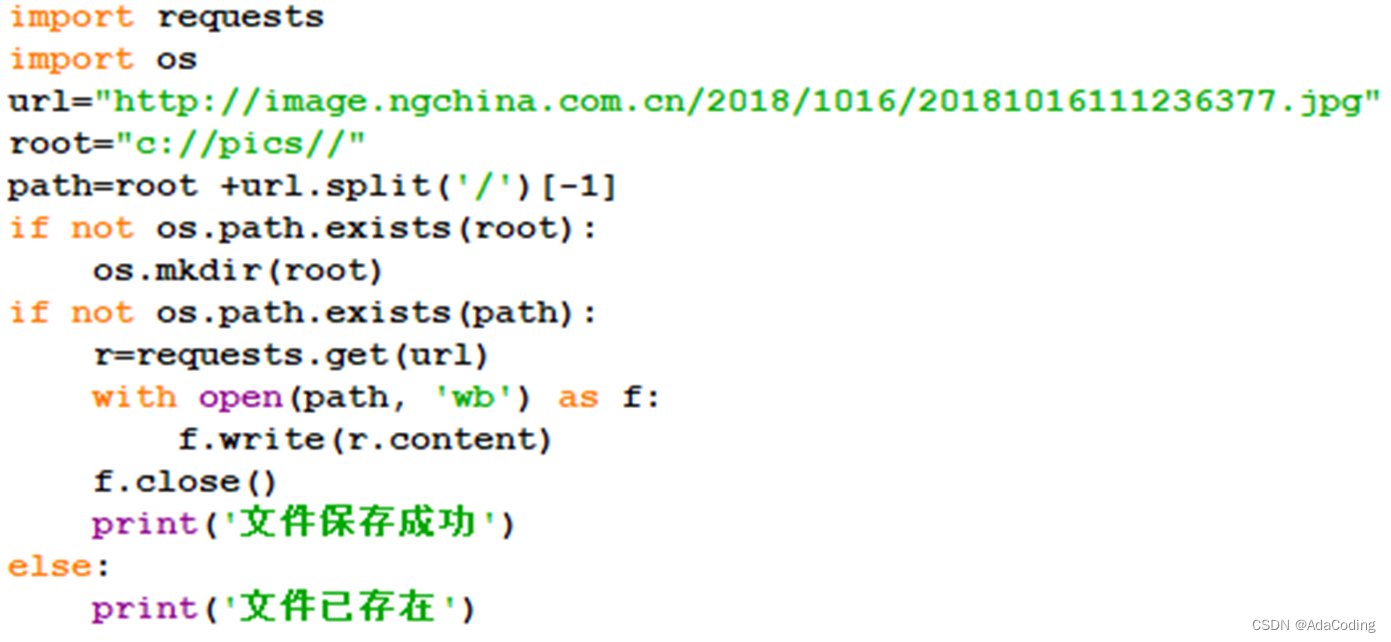
例8-31:从国家地理网站上爬取照片并保存到本地磁盘
整理不易🚀🚀,关注和收藏后拿走📌📌欢迎留言🧐👋📣✨
快来关注我的公众号🔎AdaCoding 和 GitHub🔎 AdaCoding123
















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









