







📌秋招八股--场景题-全部知识
- `美团`
- `阿里`
- `腾讯`
- `字节`
- 实现简单限流算法
- 如何优化粒度, 滑动窗口
- 简单思维题, 满100享受120优惠, 和打八折哪个划算.
- 两个文件中存在一些字符串, 寻找哪些字符串存在于两个文件中.小文件如何做, 大文件如何做
- 消费者和生产者模式你了解吗?
- 开放设计题:设计一个阻塞队列,实现多生产者多消费者模型?
- 开放设计题:给定一个数组,存储A B C D等object,存在A1 A2 A3这样的优先级,问如何设计这个object,并且给定一个指定object,比如A1 B2 C3 如何精准匹配,并根据优先级进行取出最匹配的值。
- 开放算法题:给了一个图,里面存放着ABCDEFG链表节点,每个节点都有自己的前驱后驱指针数组,问:如何根据这个链表以及里面的数组信息,给他们进行安排到指定的层数?(类似于树结构)。
- 设计一个线程安全的链表(不允许使用现有结构)
- 如何设计一个短链系统?
- 设计一个算法,给定 a、b 两个文件,各存放 50 亿个 URL,每个 URL 各占 64B,内存限制是 4G。请找出 a、b 两个文件共同的 URL。
- 设计题:千万级、亿级整数数据,拥有4GB不连续的内存,设计一个双端队列结构,首尾都可以入出队,存入这些数据
- 1. 实现一个阻塞队列(使用Semaphore)
- 2. 写一个SQL,找出过去一小时中游戏平均分最高的前20个用户的 游戏平均分、uid、user_name
- 3.实现前缀树
Java后端各科最全八股自用整理,获取方式见:
美团
网站如何承受高流量
集群处理 负载均衡
负载均衡的方式 不是算法 是方式
我答了nginx dns负载均衡 lvs
上线服务后是如何把流量打到该服务的
面试官提示 是服务发现 服务注册相关的
如何设计一个红绿灯系统 重点考虑可扩展性 可维护性 基本从面向对象设计原则 设计模式这个方向答的
如何设计一个银行账户系统 考虑安全性 稳定性
银行系统高并发如何处理
阿里
口述了一个统计数据的场景题
如果这个统计数据场景不用MySQL,而是用Java来实现,怎么做
如果数据量过大,内存放不下呢
用面向对象的思想解决上面提出的问题,创建出父类,子类,方法,说一下思路
下一个场景,口述了一个登录场景,同学用线程池做登录校验,会有什么问题
如何解决这些问题
你给出的方案弊端在哪里,还有哪些方案
腾讯
一个场景:内存只有一个G,而其他地方有几十亿的数字,现在给定一个数字,如何快速判断这个数字是否存在在那些数字当中
https://blog.csdn.net/v_JULY_v/article/details/6279498
建一个bitmap的表,对应数字存在即相应bit位置1,遍历一遍过后,查看给定数字对应的bit位是否为1
方法一:分治法
- 依然可以用分治法解决,方法与前面类似,就不再次赘述了。
方法二:位图法bitmap
- 40 亿个不重复整数,我们用 40 亿个 bit 来表示,初始位均为 0,那么总共需要内存:4,000,000,000b≈512M。
- 我们读取这 40 亿个整数,将对应的 bit 设置为 1。接着读取要查询的数,查看相应位是否为 1,如果为 1 表示存在,如果为 0 表示不存在。
方法总结
- 判断数字是否存在、判断数字是否重复的问题,位图法是一种非常高效的方法。
字节
实现简单限流算法
https://juejin.cn/post/6870396751178629127
https://z.itpub.net/article/detail/B049B6F216829EDD0827E97BC1AA9100
令牌桶算法
- 面对突发流量的时候,我们可以使用令牌桶算法限流。
令牌桶算法原理:
- 有一个令牌管理员,根据限流大小,定速往令牌桶里放令牌。
- 如果令牌数量满了,超过令牌桶容量的限制,那就丢弃。
- 系统在接受到一个用户请求时,都会先去令牌桶要一个令牌。如果拿到令牌,那么就处理这个请求的业务逻辑;如果拿不到令牌,就直接拒绝这个请求。
如何优化粒度, 滑动窗口
简单思维题, 满100享受120优惠, 和打八折哪个划算.
- 便宜20
- 100*0.8=80 便宜20
两个文件中存在一些字符串, 寻找哪些字符串存在于两个文件中.小文件如何做, 大文件如何做
双层循环
小文件字符串作为外层循环,大文件字符串作为内层循环,进行查找
消费者和生产者模式你了解吗?
开放设计题:设计一个阻塞队列,实现多生产者多消费者模型?
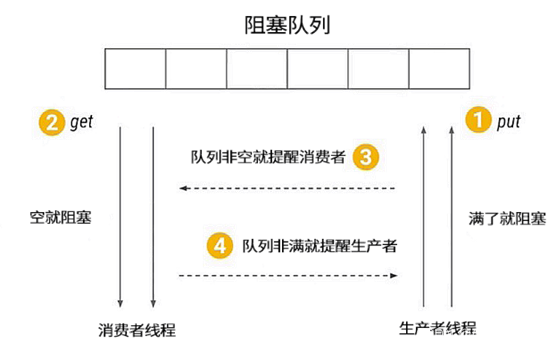
那么什么时候阻塞线程需要被唤醒呢?有两种情况。
- 第一种情况是当消费者看到阻塞队列为空时,开始进入等待,这时生产者一旦往队列中放入数据,就会通知所有的消费者,唤醒阻塞的消费者线程。
- 另一种情况是如果生产者发现队列已经满了,也会被阻塞,而一旦消费者获取数据之后就相当于队列空了一个位置,这时消费者就会通知所有正在阻塞的生产者进行生产,这便是对生产者消费者模式的简单介绍。
- 可以利用BlockingQueue实现生产者-消费者为题,阻塞队列完全可以充当共享数据区域,就可以很好的完成生产者和消费者线程之间的协作。
开放设计题:给定一个数组,存储A B C D等object,存在A1 A2 A3这样的优先级,问如何设计这个object,并且给定一个指定object,比如A1 B2 C3 如何精准匹配,并根据优先级进行取出最匹配的值。
开放算法题:给了一个图,里面存放着ABCDEFG链表节点,每个节点都有自己的前驱后驱指针数组,问:如何根据这个链表以及里面的数组信息,给他们进行安排到指定的层数?(类似于树结构)。
设计一个线程安全的链表(不允许使用现有结构)
-
对于链表这类的数据结构,无非就涉及到增删改查四种基本操作,我们只要保证在对链表进行增删改查时是线程安全的即可。在绝大多数情况下,读的操作多于增删改的操作,所以可以考虑使用JUC包下的读写锁类
ReentrantReadWriteLock,当进行读操作时获取读锁,进行增删改操作时获取写锁。这样可以保证多个线程可以同时读取链表中的数据,某个时刻只有一个线程能对链表进行增删改。 -
ReentrantReadWriteLock可以参考:ReentrantReadWriteLock读写锁。
final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public returnVal read(params){
lock.readLock().lock();
try {
// read data
}finally {
lock.readLock().unlock();
}
}
public returnVal add_delete_update(params){
lock.writeLock().lock();
try {
// add or delete or update data
}finally {
lock.writeLock().unlock();
}
}
如何设计一个短链系统?
(这个其实是之前的面试题,觉得有意思就一起放在这儿了)
- 这道题是我一面的面试题,只不过我觉得挺有意思,我就放在这了,因为当时考虑的十分不周全,只想到了里面一丢丢的思路,但整个设计思路我觉得还是挺考验基础的,包含重定向、短链生成算法(哈希算法、自增序列算法)、follow up也有用户自定义短链接的设计思路等等。
- 这个大家直接去百度一下就可以找到这道系统设计题的各种思路,大家不用死记硬背,只需看一遍有个大致的印象,因为这道题似乎面试中也不太经常出现。
设计一个算法,给定 a、b 两个文件,各存放 50 亿个 URL,每个 URL 各占 64B,内存限制是 4G。请找出 a、b 两个文件共同的 URL。
https://juejin.cn/post/6844904003998842887
https://www.modb.pro/db/196359
- 这种题
腾讯会经常出,就是海量数据问题,在内存限制下完成一些大文件的筛选过滤。 - 如果大家想一网打尽的话还是推荐看看
左程云的那本算法书上的其中一章(只推荐这一章,可以找找pdf版或者看看别人有没有,没必要为了这一章去买书)。
解答思路
- 每个 URL 占 64B,那么 50 亿个 URL占用的空间大小约为 320GB。
5, 000, 000, 000 * 64B ≈ 5GB * 64 = 320GB- 由于内存大小只有 4G,因此,我们不可能一次性把所有 URL 加载到内存中处理。
- 对于这种类型的题目,一般采用分治策略 ,即:把一个文件中的 URL 按照某个特征划分为多个小文件,使得每个小文件大小不超过 4G,这样就可以把这个小文件读到内存中进行处理了。
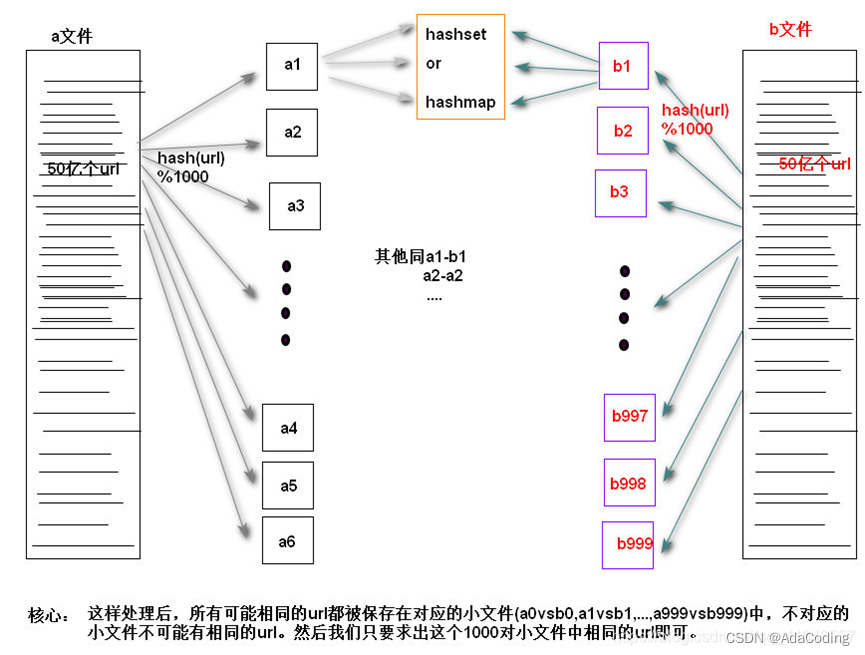
思路如下 :
- 首先遍历文件 a,对遍历到的 URL 求
hash(URL) % 1000,根据计算结果把遍历到的 URL 存储到a0, a1, a2, ..., a999,这样将文件a分成1000个小文件,每个大小约为 300MB。使用同样的方法遍历文件 b,把文件 b 中的 URL 分别存储到文件b0, b1, b2, ..., b999中。 - 这样处理过后,所有可能相同的 URL 都在对应的小文件中,即 a0 对应
b0, ..., a999对应 b999,不对应的小文件不可能有相同的 URL。那么接下来,我们只需要求出这 1000 对小文件中相同的 URL 就好了。 - 接着遍历
ai(i∈[0,999]),把 URL 存储到一个 HashSet 集合中。然后遍历 bi 中每个 URL,看在 HashSet 集合中是否存在,若存在,说明这就是共同的 URL,可以把这个 URL 保存到一个单独的文件中。
方法总结
- 分而治之,进行哈希取余;
- 对每个子文件进行 HashSet 统计。
设计题:千万级、亿级整数数据,拥有4GB不连续的内存,设计一个双端队列结构,首尾都可以入出队,存入这些数据
1. 实现一个阻塞队列(使用Semaphore)
2. 写一个SQL,找出过去一小时中游戏平均分最高的前20个用户的 游戏平均分、uid、user_name
score(id, uid, score, time)
user(uid, user_name)
3.实现前缀树
Java后端各科最全八股自用整理,获取方式见:
整理不易🚀🚀,关注和收藏后拿走📌📌欢迎留言🧐👋📣✨
快来关注我的公众号🔎AdaCoding 和 GitHub🔎 AdaCoding123
















 5198
5198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









