






Stable Diffusion,作为一种革命性的图像生成模型,自发布以来便因其卓越的生成质量和高效的计算性能而受到广泛关注。不同于以往的生成模型,Stable Diffusion在生成图像的过程中,采用了独特的扩散过程,结合深度学习技术,实现了从噪声到清晰图像的逐步演化。本文将深入浅出地解析Stable Diffusion的工作原理,通过详细的图解和实例演示,带领读者全面理解这一前沿技术。
一、Stable Diffusion概览
1.1 模型起源与特点
Stable Diffusion模型源于Diffusion Probabilistic Models,这是一种通过向初始数据添加高斯噪声,然后学习逐步去除噪声以恢复原始数据的生成模型。Stable Diffusion通过优化训练过程,提高了生成效率和图像质量,同时降低了计算资源的需求,使其成为图像生成领域的一个里程碑。
1.2 主要组件
- 扩散过程:模型的核心,通过一系列步骤将图像从纯噪声状态逐步还原为清晰图像。
- 反向扩散过程:学习从噪声到图像的逆向映射,是生成图像的关键。
- 条件输入:允许模型根据特定的文本描述或其他条件生成图像,增强了生成的可控性和多样性。
二、Stable Diffusion工作原理
2.1 扩散过程
在扩散过程中,Stable Diffusion将原始图像逐渐添加噪声,直到图像完全变为随机噪声。这一过程可以表示为一系列随机变量的分布转移,即:
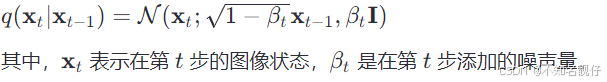
编辑
2.2 反向扩散过程
反向扩散过程是模型学习的重点,其目标是从噪声中逐步恢复图像。Stable Diffusion通过一个深度神经网络(通常是一个U-Net架构)学习以下条件分布:

编辑
2.3 条件生成
Stable Diffusion支持条件生成,即根据特定的输入(如文本描述)生成图像。这一特性通过在U-Net中加入额外的条件编码器实现,确保生成的图像与给定的条件相匹配。
三、Stable Diffusion图解
3.1 扩散过程图解
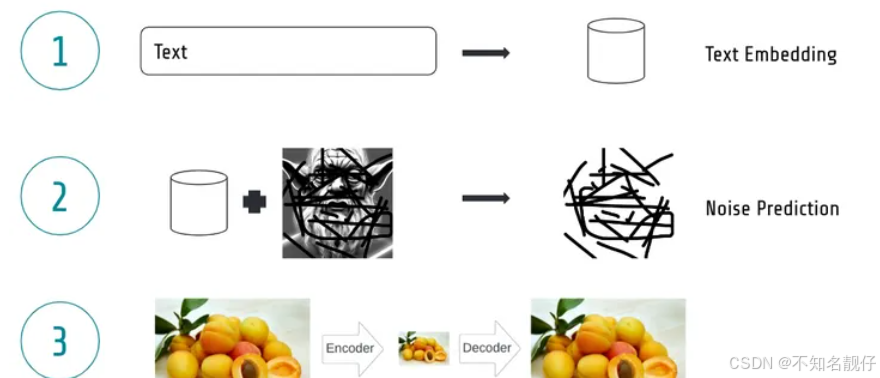
编辑
图中展示了一个图像从清晰状态逐渐变为噪声的过程。每一步,模型都会添加一定量的噪声,直到图像完全模糊。
3.2 反向扩散过程图解
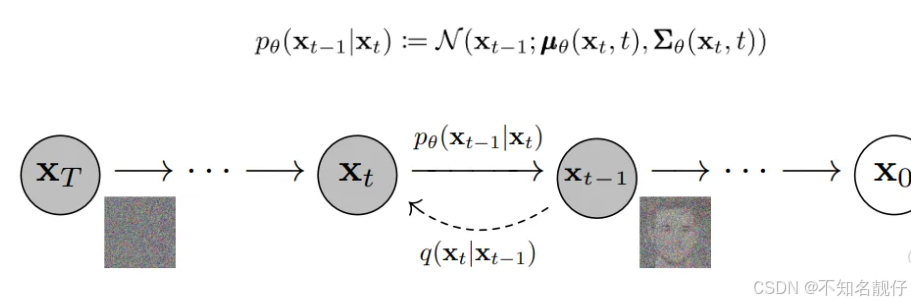
编辑
这一图解展示了从噪声逐步恢复到清晰图像的过程。通过深度神经网络预测噪声并逐步去除,最终生成清晰的图像。
四、Stable Diffusion与其它模型的对比
4.1 与GAN的对比
- 稳定性:Stable Diffusion相比GAN更稳定,不易出现模式崩溃或生成质量波动。
- 生成质量:两者均能生成高质量图像,但Stable Diffusion在保持多样性的同时,生成的图像更加一致和稳定。
4.2 与VAE的对比
- 灵活性:Stable Diffusion在生成图像时更具灵活性,可以更容易地控制生成过程和结果。
- 训练难度:Stable Diffusion的训练相对简单,而VAE可能需要复杂的调优以获得良好性能。
五、Stable Diffusion的未来展望
随着技术的不断发展,Stable Diffusion模型有望在图像生成、视频合成、3D建模等多个领域展现更广泛的应用。其高效、稳定和可控的特性,将为AI生成内容带来更多的可能性,推动创意产业的革新。
六、结语
Stable Diffusion作为图像生成领域的一项突破性成果,不仅在学术界引起了轰动,也为广大开发者和创意工作者提供了强大的工具。通过本文的解析,我们不仅理解了Stable Diffusion的工作原理,还看到了它在实际应用中的巨大潜力。随着技术的不断进步,我们有理由相信,Stable Diffusion将在未来的AI生成内容领域发挥更加重要的作用。















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









