






引言
强化学习是除了监督学习和无监督学习之外的另一种机器学习方法。
监督学习:是从标记好的训练数据中学习模型。
无监督学习:是从未标记的数据中发现模式、结构或关系,而无需提前知道预期的输出标签。
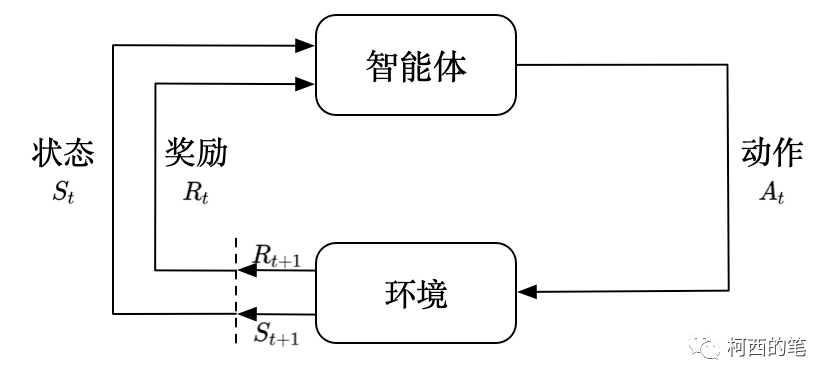
强化学习:其重点是让智能体(agent)从与环境的交互中学习,以达到最大化某种形式的累积奖励。在强化学习中,智能体采取一系列行动来实现特定目标,然后根据环境的反馈(奖励或惩罚)来调整其行为策略。
强化学习有哪些好处?
适用于复杂环境:强化学习能够处理复杂、不确定和动态的环境,其中传统的监督学习和无监督学习方法可能无法有效应对。
自动化学习:强化学习不需要大量手工标记的训练数据,而是通过与环境的交互自动学习。这使其适用于一些领域,其中标记数据难以获得,成本高昂或不实际。
针对长期目标进行优化: 强化学习本质上侧重于长期奖励最大化,因此适用于行动可带来长期后果的场景。它特别适合每一步都无法立即获得反馈的现实情况,因为它可以从延迟的奖励中学习。
强化学习基本元素
智能体(Agent):智能体是强化学习系统的主体,它是进行学习和决策制定的实体。智能体可以是机器人、虚拟角色、自动驾驶汽车,或任何需要在环境中采取行动的实体。
环境(Environment):环境是智能体所处的外部世界,它包括智能体与其互动的所有事物和条件。环境可以是仿真环境、现实世界、游戏环境等。智能体通过与环境互动来获取信息和奖励。
状态(State):状态是描述环境的一个关键因素,它是一个包含有关环境的信息的表示。状态可以是连续的(如传感器数据)或离散的(如棋盘上的棋子位置)。智能体的目标是在不同的状态下采取行动以获得最大的奖励。
动作(Action):动作是智能体可以执行的操作或决策,它们是智能体与环境互动的方式。动作可以是连续的(如控制机器人的关节运动)或离散的(如在棋盘上移动一枚棋子)。
奖励(Reward):奖励是环境提供给智能体的反馈信号,用于评估智能体采取特定动作的好坏。奖励通常是一个数值,表示动作的质量或对智能体的性能产生的影响。智能体的目标是最大化长期累积的奖励。
策略(Policy):策略是智能体在特定状态下选择动作的规则或函数。策略可以是确定性的,即对于每个状态都有一个确定的最佳动作,也可以是随机的,即在每个状态下选择动作的概率分布。
价值函数(Value Function):价值函数用于评估状态或状态-动作对的好坏。它指示在特定状态下采取行动的长期回报期望值。有两种主要类型的价值函数:状态值函数(评估状态的好坏)和动作值函数(评估状态-动作对的好坏)。
回报(Return):回报是智能体在一个时间步骤或一系列时间步骤中获得的累积奖励。强化学习的目标通常是最大化长期回报,这要求智能体能够制定长期规划。
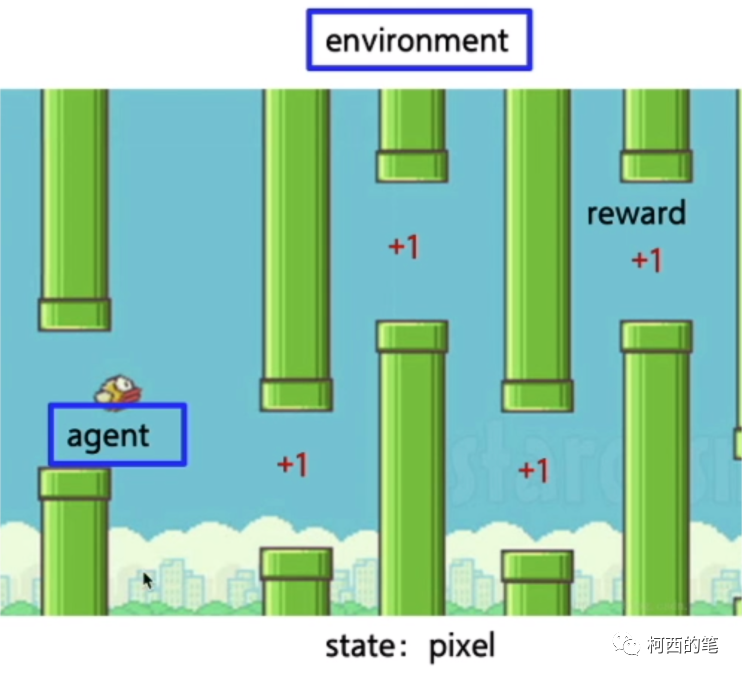
| Agent | 小鸟 |
| Environment | 鸟周围的环境(包括:鸟,水管,天空) |
| State | 鸟目前的位置(即整幅窗口图像) |
| Action | 上下移动 |
| Reward | 顺利过一个水管+1 |
| Policy | 根据前方水管空隙以及小鸟前进速度选择上移或者下移。 |
| Value Function | 状态函数:状态可以表示小鸟的垂直位置、水管的位置、小鸟的速度等。状态值函数V(s)表示在状态s下智能体可以获得的期望回报。 动作函数:动作可以表示小鸟是否跳跃或不跳跃。动作值函数Q(s, a)表示在状态s下采取动作a后,智能体可以获得的期望回报。 |
| Return | 最终游戏通关,或者游戏失败时获得的总分。 |
如果用一个神经网络来玩这个游戏,一般要这样实现:用某一时刻的游戏界面图片作为输入,输出应该执行的动作,即上下移动。这可以看成一个分类问题,但麻烦的是,要训练这样一个神经网络,我们将会需要大量的图片,而且,我们需要专业的玩家在每个时刻做出正确的动作,才能获得标签(label)。这样就太笨拙了,“人”学习一个游戏,并不需要另一个人告诉我们每种可能的游戏界面下分别做什么动作,我们需要的只是偶尔的反馈:告诉我们现在是对的,能得分,技巧我们可以自然地找到。
这就是强化学习擅长的事情,利用稀疏且有延迟的标签,这就种标签就是奖励。只基于这些奖励,“人”就可以学习怎样在环境中做出适当的行为。
算法分类
强化学习的三种方法:基于价值(value-based)、基于策略(policy-based)以及上两种的结合方法。下文将会对应的找几种算法进行详细的介绍。
基于价值(value-based)
在介绍DQN之前,我们首先需要先了解下Q-learning。Q-learning 是一种基于价值的强化学习算法,用于解决马尔可夫决策过程(MDP)问题。其目标是学习一个Q函数,Q(s, a),它给出了在状态s采取动作a的预期回报。
Q-learning 的更新公式如下:
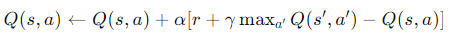
其中:
s 和a 是当前状态和动作。
r 是采取动作后的即时奖励。
s′ 是采取动作后的新状态。
α 是学习率。
γ 是折扣因子,表示未来奖励的重要性。
DQN
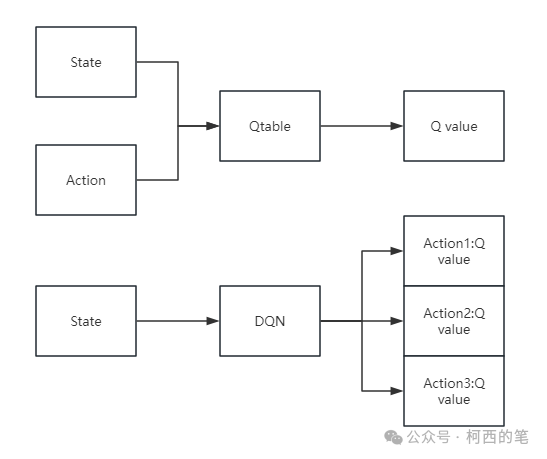
DQN实际上,总体思路还是用的Q-learning的思路,不过对于给定状态选取哪个动作所能得到的Q值,却是由一个深度神经网络来计算的了。
固定Target Q网络:Q-Learning中用来计算target和预测值的Q是同一个Q,也就是说使用了相同的神经网络。这样带来的一个问题就是,每次更新神经网络的时候,target也都会更新,这样会容易导致参数不收敛。回忆在有监督学习中,标签label都是固定的,不会随着参数的更新而改变。因此DQN在原来的Q网络的基础上又引入了一个Target Q网络,即用来计算target的网络。它和Q网络结构一样,初始的权重也一样,只是Q网络每次迭代都会更新,而target Q网络是每隔一段时间才会更新。既有2个网络,结构如下所示:
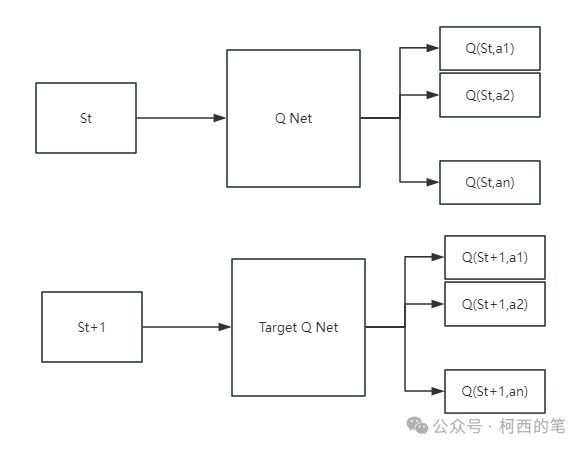
ϵ−greedy策略:其实这里涉及到了强化学习中一个非常重要的概念,叫Exploration & Exploitation,探索与利用。前者强调发掘环境中的更多信息,并不局限在已知的信息中;后者强调从已知的信息中最大化奖励。而ϵ−greedy策略兼具了探索与利用,它以ϵ的概率从所有的action中随机抽取一个,以1−ϵ的概率抽取分数最高的动作。强化学习正是因为有了探索Exploration,才会常常有一些出人意表的现象,才会更加与其他机器学习不同。
经验回放:已知一个状态St,通过Q Net得到各种动作的Q值然后用
ϵ−greedy策略选择动作at,将at输入到环境中,得到St+1和rt,将(St,at,St+1,r),存入到缓冲区,然后从缓冲区中随机抽取小批量样本进行学习,从而打破数据之间的相关性,提高学习稳定性。
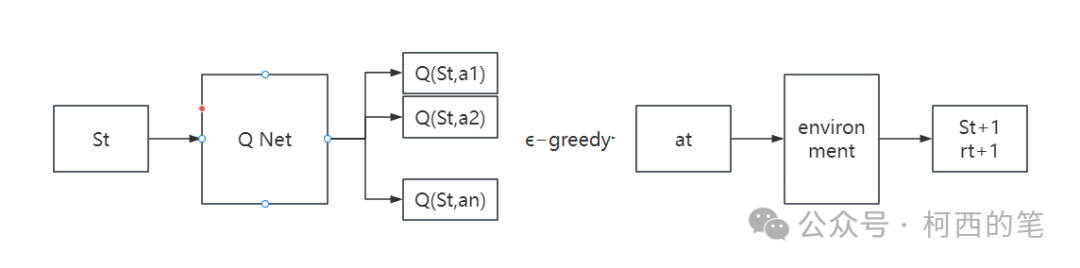
工作流程:
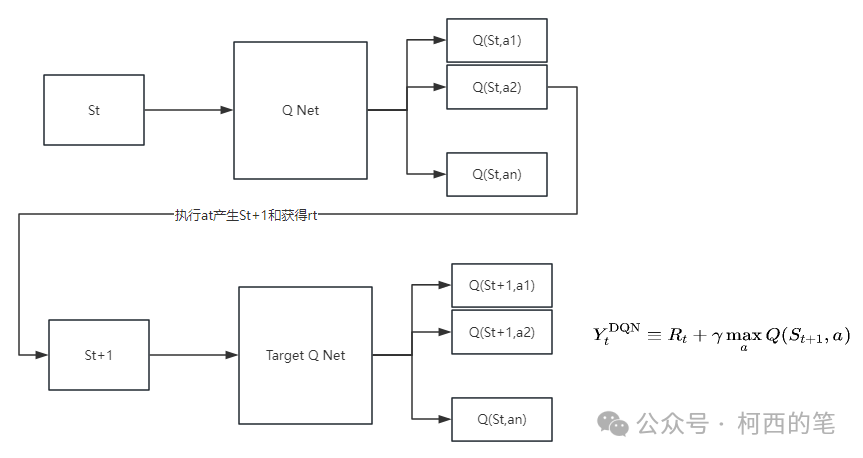
损失函数:
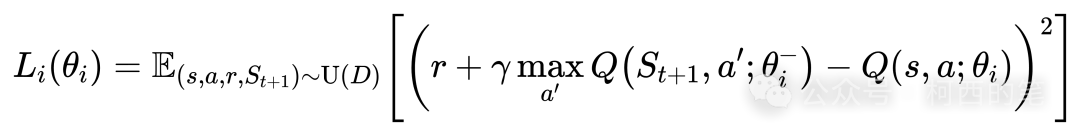
仔细看这个公式其实就是利用的MSE损失函数。每次只要传入一组(s,a,r,St+1),即当前所处状态s,当前选择的动作a,做出动作a后获得的奖励r,以及做出动作a后转移到的下一状态St+1。这四个值都可以在模拟一局游戏时取到,而且每模拟一局游戏能取到非常多组数据。在论文中作者提出了经验回放(experience replay)的采集数据方法,即事先采样足够多组的数据放入一个固定容量的经验池中,然后每次训练时从该经验池中随机取出一个batch的数据进行梯度下降更新参数。值得注意的是这一个batch的数据训练完成后是放回经验池的,也就是说下次训练时是可以复用的。只有当产生新的数据时,才会更新经验池。当一轮训练完成,更新完模型参数后,再根据该模型提供的策略进行模拟游戏,产生新的数据并放入经验池中,由于该经验池是有最大容量的,所以最早的一些数据会被新的数据替代。像这样每玩几局游戏训练一次(玩游戏的同时其实是在更新训练数据),极大地提升了训练的效率。
DDQN
DDQN与DQN大部分都相同,只有一步不同,那就是在选择Q(St+1,a)的过程中,DQN总是选择Target Q网络的最大输出值。而DDQN不同,DDQN首先从Q网络中找到最大输出值的那个动作,然后再找到这个动作对应的Target Q网络的输出值。用图像表示即为:
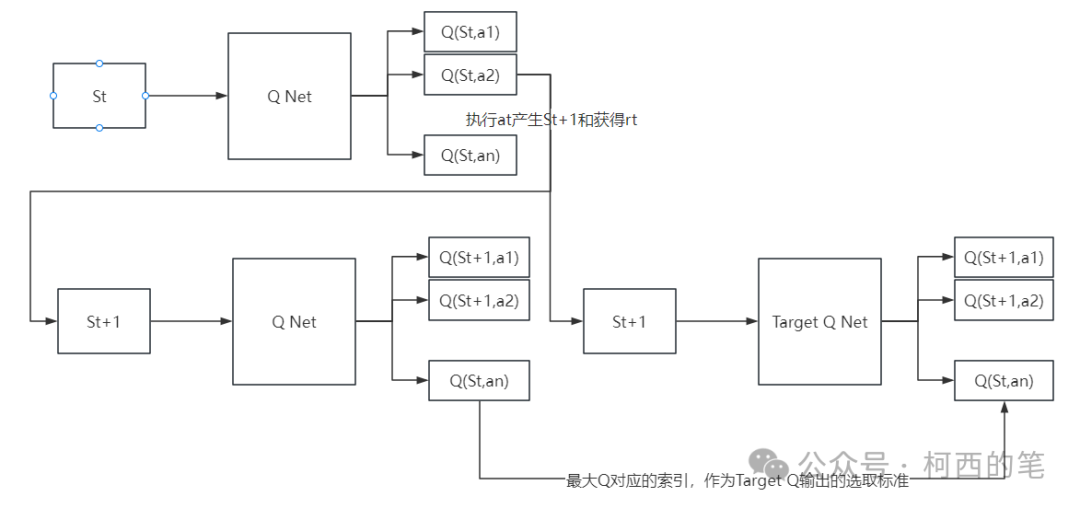
如上图所示,根据St和at是可以确定当前的Q(St,a)值的,假设这里值为Q(St,a1)。此处根据ϵ−greedy策略筛选的,那么执行动作a1,就可以确定St+1,然后将St+1输入到Q Net中,得到各种不同的Q值。此处筛选据最大Q值对应的动作,假设这里筛选了a2。然后将St+1输入到Target Q Net中,找到a2对应的Q值Q(St+1,a2)。最后Q(St,a1)作为网络预测值,而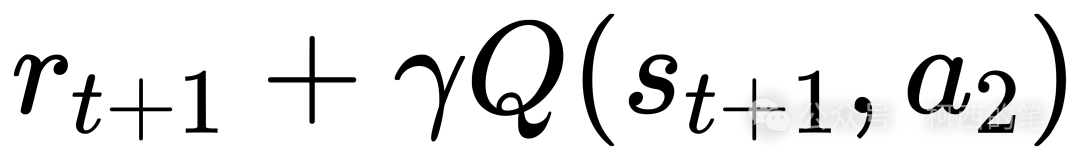 作为网络的实际值,接着进行一系列的反向传播。
作为网络的实际值,接着进行一系列的反向传播。
Dueling-DQN
Dueling DQN算法提出了一种新的神经网络结构——对偶网络(duel network)。网络的输入与DQN和DDQN算法的输入一样,均为状态信息,但是输出却有所不同。如下图所示,上面是我们传统的DQN,下面是我们的Dueling DQN。在原始的DQN中,神经网络直接输出的是每种动作的 Q值, 而 Dueling DQN 每个动作的Q值,是由状态价值V和优势函数A确定的,即Q = V + A。
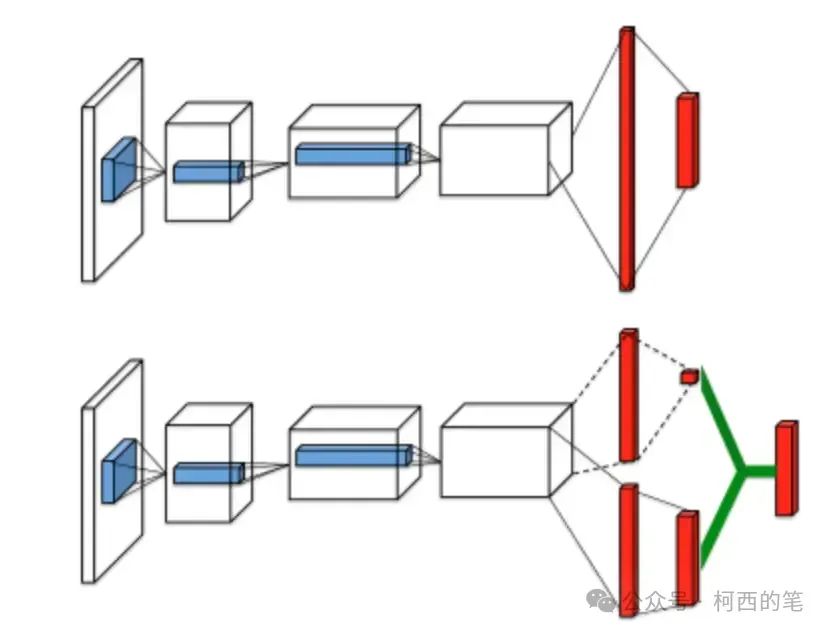
什么是优势函数?我们可以简单理解为,对于一个特定的状态,采取一个动作所能得到的价值与这个状态能得到的平均价值的区别。如果采取的动作得到的价值比平均价值大,那么优势函数为正,反之为负。
简单的使用Q = V + A可以么?当然不行,因为对于一个确定的Q,有无数种V和A的组合可以得到Q。因此我们需要对A进行一定的限定,通常将同一状态下的优势函数A的均值限制为0。所以,我们的Q值计算公式如下:
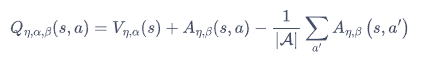
基于策略(policy-based)
PG
前面我们介绍的DQN及其相关变种都是基于价值的强化学习算法,在给定一个状态下,计算采取每个动作的价值,我们选择有最高Q值(在所有状态下最大的期望奖励)的行动。如果我们省略中间的步骤,即直接根据当前的状态来选择动作,也就引出了强化学习中的另一种很重要的算法,即策略梯度(Policy Gradient, PG)。
而现实生活中,很多决策的行动空间是高维甚至连续(无限)的,比如自动驾驶中,汽车下一个决策中方向盘的行动空间,就是一个从[-900°,900°](假设方向盘是两圈半打满)的无限空间中选一个值,如果我们用Q系列算法来进行学习,则需要对每一个行动都计算一次reward,那么对无限行动空间而言,哪怕是把行动空间离散化,针对每个离散行动计算一次reward的计算成本也是当前算力所吃不消的。这是对Q系列算法提出的第一个挑战:无法遍历行动空间中所有行动的reward值。
此外,现实中的决策往往是带有多阶段属性的,说白了就是:“不到最后时刻不知输赢”。以即时策略游戏(如:星际争霸,或者国内流行的王者荣耀)为例,玩家的输赢只有在最后游戏结束时才能知晓,谁也没法在游戏进行过程中笃定哪一方一定能够赢。甚至有可能发生:某个玩家的每一步行动看起来都很傻,但是最后却能够赢得比赛,比如,Dota游戏中,有的玩家虽然死了很多次,己方的塔被拆了也不管,但是却靠着偷塔取胜(虽然这种行为可能是不受欢迎的)。诸如此类的情形就对Q系列算法提出了第二个挑战,Agent每执行一个动作(action)之后的奖励(reward)难以确定,这就导致Q值无法更新。
那么,难道深度强化学习就不能处理诸如上述两类情形的问题了吗?答案当然是否定的,这就衍生出了基于PG的系列深度强化学习算法。
蒙特卡罗策略梯度reinforce算法是策略梯度最简单的也是最经典的一个算法。

其主要步骤如下:
采样完整轨迹:从当前策略中采样一条完整的轨迹(从起始状态到终止状态的状态-动作-奖励序列)。
计算回报:对于每条轨迹,计算从当前时间步到结束时间步的累计回报。
更新策略参数:使用梯度上升法,根据策略梯度定理更新策略参数。
DDPG
深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法的主要网络结构为以下四个:
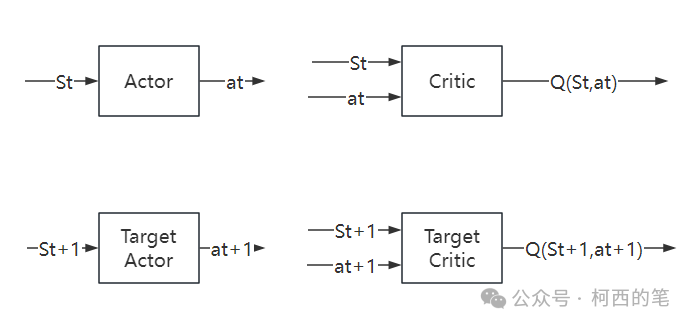
Actor网络输入是状态,输出是动作。Critic网络输入是状态和动作,输出是对应的Q值。Actor网络的目的是根据状态St,能够输出使得Q(St,at)值最大的动作at,这个,at越能使Q(St,at)大,说明网络训练地越好。
Critic网络的目的是根据状态动作对(St,at)能够输出其action value Q(St,at),这个Q值越精确,就说明网络训练地越好。
Actor网络和Target Actor网络的区别是,Actor网络是每步都会在经验池中更新,而Target Actor网络是隔一段时间将Actor的网络参数软拷贝(软拷贝的意思是Actor的网络参数按照一定百分比加权到Target Actor网络,即:
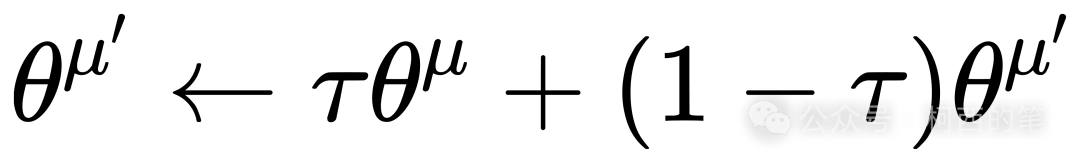 ,其中𝜏是一个很小的数)到Target Actor网络中,实现Target Actor网络的更新。这种“滞后”更新是为了保证在训练Actor网络时训练的稳定性。Critic网络和Target Critic网络也是一样。
,其中𝜏是一个很小的数)到Target Actor网络中,实现Target Actor网络的更新。这种“滞后”更新是为了保证在训练Actor网络时训练的稳定性。Critic网络和Target Critic网络也是一样。
产生experience:
已知一个状态S0,通过actor网络得到动作a'0,然后再加噪声N得到动作a0 = a'0 + N(噪声是为了保证一定的探索),然后将a0输入到环境中,得到S1和r1,这样就得到一个experience:(S0,a0,S1,r1),然后将experience放入经验池中。
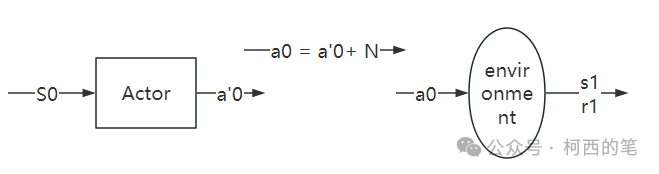
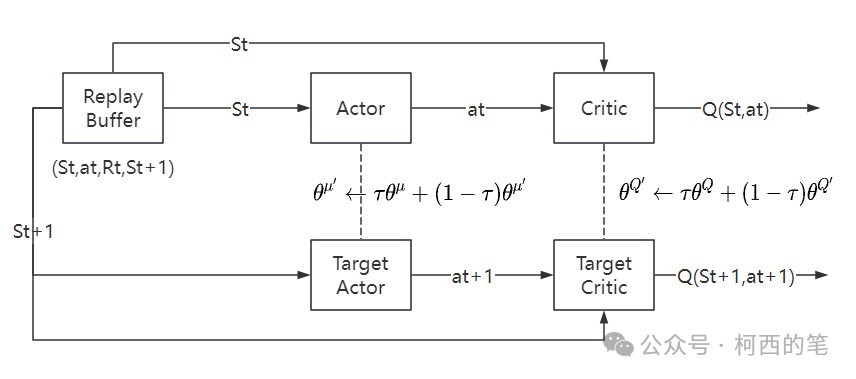
工作流程:
总结
在传统的 DQN 基础上,有两种非常容易实现的变式——Double DQN 和 Dueling DQN,Double DQN 解决了 DQN 中对Q值的过高估计,而 Dueling DQN 能够很好地学习到不同动作的差异性,在动作空间较大的环境下非常有效。基于策略的DDPG适用于连续动作空间,更适合处理高纬的状态和动作空间。
参考:
http://www.nature.com/nature/journal/v518/n7540/abs/nature14236.html
Double-DQNhttps://arxiv.org/pdf/1509.06461v3.pdf
https://arxiv.org/pdf/1511.06581.pdf
https://zhuanlan.zhihu.com/p/362076700
https://blog.csdn.net/xz15873139854/article/details/108179193
















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











