







前言:
PCI Express(Peripheral Component Interconnect Express),简称PCIe,是一种高速串行计算机扩展总线标准,用于将主板与多种硬件设备连接起来。它是由PCI-SIG开发的,旨在取代旧的PCI、PCI-X和AGP总线标准。
PCIe具有以下几个基本概念和特性:
- 串行通信
与旧的PCI标准使用并行总线不同,PCIe使用点对点的串行连接,每个设备都有自己的专用连接,极大地提高了带宽和系统的可扩展性。 - 链路宽度
PCIe连接被称为“链路”,它由一组1、2、4、8、12、16或32条通道(lanes)组成,表现形式为x1、x2、x4、x8、x16和x32。“x”的前缀代表通道(lane)的数量,在不同的设备和应用中,链路的宽度可以不同。例如,显卡通常使用x16链路,以提供最高的传输速率。 - 数据传输速率
每条通道都有自己的独立数据传输速率,这取决于PCIe的版本。例如,PCIe 3.0的每个通道的速率是8 GT/s (GigaTransfers per second),PCIe 4.0是16 GT/s等。 - 编码
从PCIe 3.0开始,使用128b/130b的编码方式,用130位传输128位数据,之前的PCIe 1.x和2.x使用8b/10b编码。 - 热插拔
PCIe支持热插拔,即可以在不关闭计算机电源的情况下添加、替换或移除设备。 - 中断
PCIe使用MSI(Message Signaled Interrupts)或MSI-X(MSI的扩展)来代替过去基于引脚的中断机制。这样减少了中断共享的问题并提高了效率。 - 电源管理
PCIe总线支持高级的电源管理,在不同的操作模式下可以调整电源使用,以节约能源或提供更高的性能。 - 兼容性
PCIe设计考虑了向下兼容,意味着较新的PCIe总线可与老一代设备配合工作。 - 应用
PCIe用于连接包括显卡、固态驱动器、以太网卡、Wi-Fi适配器、声卡等多种内部设备,也被用于雷电接口等外部扩展。
PCIe一直在不断发展中,每一代的新规范都会带来更高的速度和更好的性能,以满足高速计算和大数据传输的需求。
1 组成
PCIe相对于PCI总线的另一个大的优势是其的Scalable Performance,即可以根据应用的需要来调整PCIe设备的带宽。如需要很高的带宽,则采用多个Lane(比如显卡);如果并不需要特别高的带宽,则只需要一个Lane就可以了(比如说网卡等)。
和PCI-X总线一样,由于非常高的传输速度,PCIe是一种点对点连接的总线,而不像PCI那样的共享总线。但是PCIe总线系统可以通过Switch连接多个PCIe设备,也可以通过PCIe桥连接传统的PCI和PCI-X设备。一个简单的PCIe总线系统的拓扑结构图如下所示:
注:这里的Switch实际上包含了多个类似于PCI总线中桥的概念。
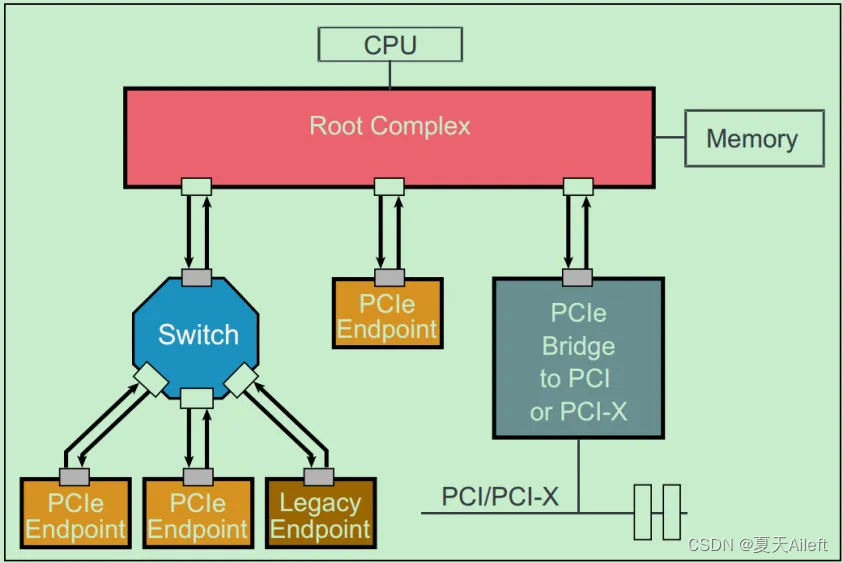
图中的Root Complex经常被称为RC或者Root。在PCIe的Spec中,并没有特别详细的关于Root Complex的定义,从实际的角度来讲,可以把Root Complex理解为CPU与PCIe总线系统通信的媒介。Endpoint处于PCIe总线系统拓扑结构中的最末端,一般作为总线操作的发起者(initiator,类似于PCI总线中的主机)或者终结者(Completers,类似于PCI总线中的从机)。显然,Endpoint只能接受来自上级拓扑的数据包或者向上级拓扑发送数据包。所谓Lagacy PCIe Endpoint是指那些原本准备设计为PCI-X总线接口的设备,但是却被改为PCIe接口的设备。而Native PCIe Endpoint则是标准的PCIe设备。其中,Lagacy PCIe Endpoint可以使用一些在Native PCIe Endpoint禁止使用的操作,如IO Space和Locked Request等。Native PCIe Endpoint则全部通过Memory Map来进行操作,因此,Native PCIe Endpoint也被称为Memory Mapped Devices(MMIO Devices)。
1.1 根组件(Root Complex)
根桥设备,是PCIe最重要的一个组成部件; Root Complex主要负责PCIe报文的解析和生成。RC接受来自CPU的IO指令,生成对应的PCIe报文,或者接受来自设备的PCIe TLP报文,解析数据传输给CPU或者内存。
RC的作用:
configuration请求总是从RC发起
1.2 交换设备(Switch)
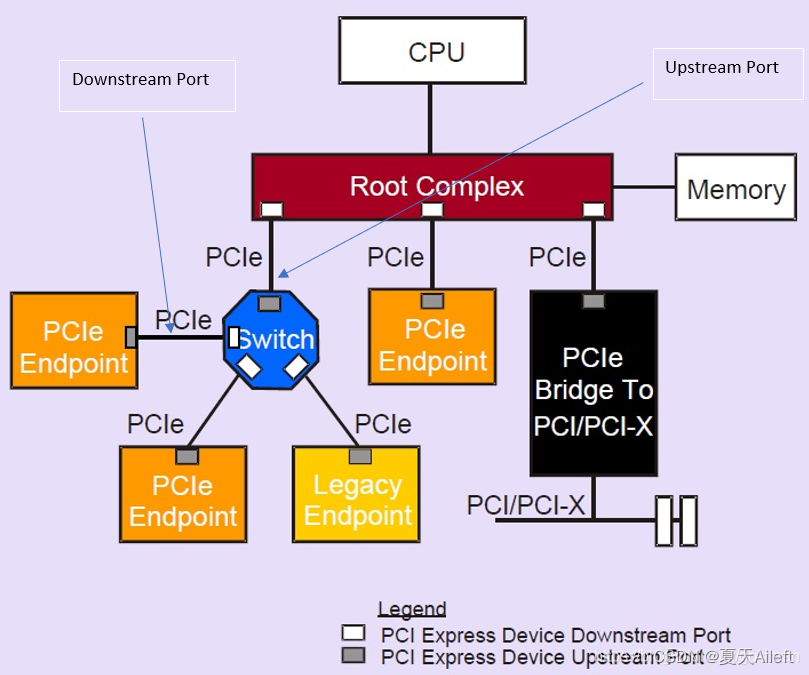
PCIe的转接器设备,目的是扩展PCIe总线。和PCI并行总线不同,PCIe的总线采用了高速差分总线,并采用端到端的连接方式, 因此在每一条PCIe链路中两端只能各连接一个设备, 如果需要挂载更多的PCIe设备,那就需要用到switch转接器。switch在linux下不可见,软件层面可以看到的是switch的上行口(upstream port, 靠近RC的那一侧) 和下行(downstream port)。
备注:一个switch 只有一个upstream port, 可以有多个downstream port.
1.3 终端设备(Endpoint)
PCIe终端设备,是PCIe树形结构的叶子节点。比如网卡,NVME卡,显卡都是PCIe ep设备。
1.3.1 EP的作用:
响应配置请求。
响应IO请求。
响应Memory请求。
发起Memory请求。
1.3.2 EP的分类:
Legacy Endpoint (Legacy EP)
Legacy Endpoint是指在PCIe早期版本中兼容传统PCI设备的端点。这些设备在设计上保留了对老旧PCI硬件或软件互操作性的支持。Legacy Endpoints通常使用传统的中断处理机制,如INTx(其中x是一个代表中断线路的字母,比如INTA, INTB等),即通过电气信号进行中断,而不是通过消息信号中断(MSI)或扩展的消息信号中断(MSI-X)的模式。这使得老式的PCI系统能够与这些新型的PCIe设备相兼容。
PCIe Endpoint (PCIe EP)
PCIe Endpoint是专门设计用于PCI Express架构的设备,它利用PCIe提供的串行通信以及先进的特性,如内存映射I/O,MSI/MSI-X中断和高速数据传输。与Legacy Endpoints相比,PCIe Endpoints不支持传统的PCI中断和总线特性,它们完全依赖于PCIe的通信协议和数据传输机制。
Root Complex Integrated Endpoint (RC Integrated EP)
Root Complex Integrated Endpoint是集成在root complex中的端点设备。在PCIe架构中,Root Complex是连接CPU和内存子系统的元件,控制着PCIe拓扑的最高层,并提供一个或多个PCIe端口。Root Complex Integrated Endpoint直接集成在主板的芯片组或处理器中,与外置的PCIe Endpoint装置有所区别。这种集成有助于减少物理空间、节约成本和能源,并提升数据传输的效率。常见的集成端点可能包括集成图形处理单元(iGPU)或内置I/O控制器等。
总的来说,这三种类型的Endpoints提供了在PCI Express架构中与系统其他部分通信的不同方式和性能级别。随着技术的发展,Legacy Endpoints现在很少见,而现代系统更倾向于采用专门为PCIe设计的Endpoints或有着Root Complex集成功能的集成Endpoints。
拓扑图
2 PCIE分层结构
和很多的串行传输协议一样,一个完整的PCIe体系结构包括应用层、事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer)。其中,应用层并不是PCIe Spec所规定的内容,完全由用户根据自己的需求进行设计,另外三层都是PCIe Spec明确规范的,并要求设计者严格遵循的。
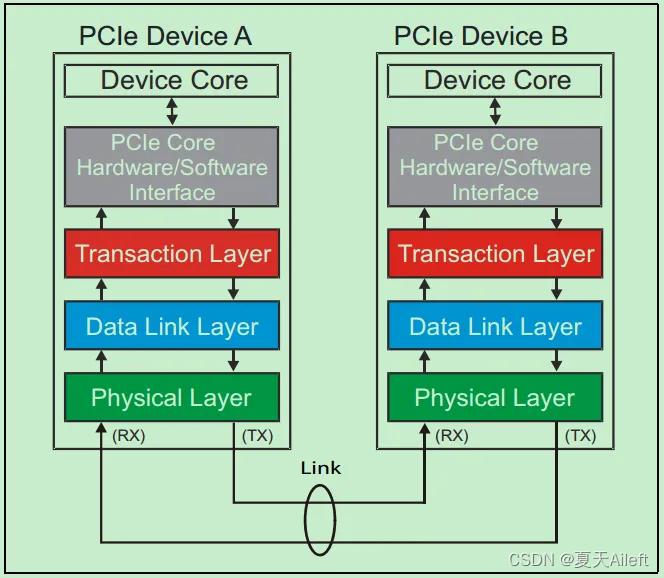
一个简化的PCIe总线体系结构如上图所示,其中Device Core and interface to Transaction Layer就是我们常说的应用层或者软件层。这一层决定了PCIe设备的类型和基础功能,可以由硬件(如FPGA)或者软硬件协同实现。如果该设备为Endpoint,则其最多可拥有8项功能(Function),且每项功能都有一个对应的配置空间(Configuration Space)。如果该设备为Switch,则应用层需要实现包路由(Packet Routing)等相关逻辑。如果该设备为Root,则应用层需要实现虚拟的PCIe总线0(Virtual PCIe Bus 0),并代表整个PCIe总线系统与CPU通信。
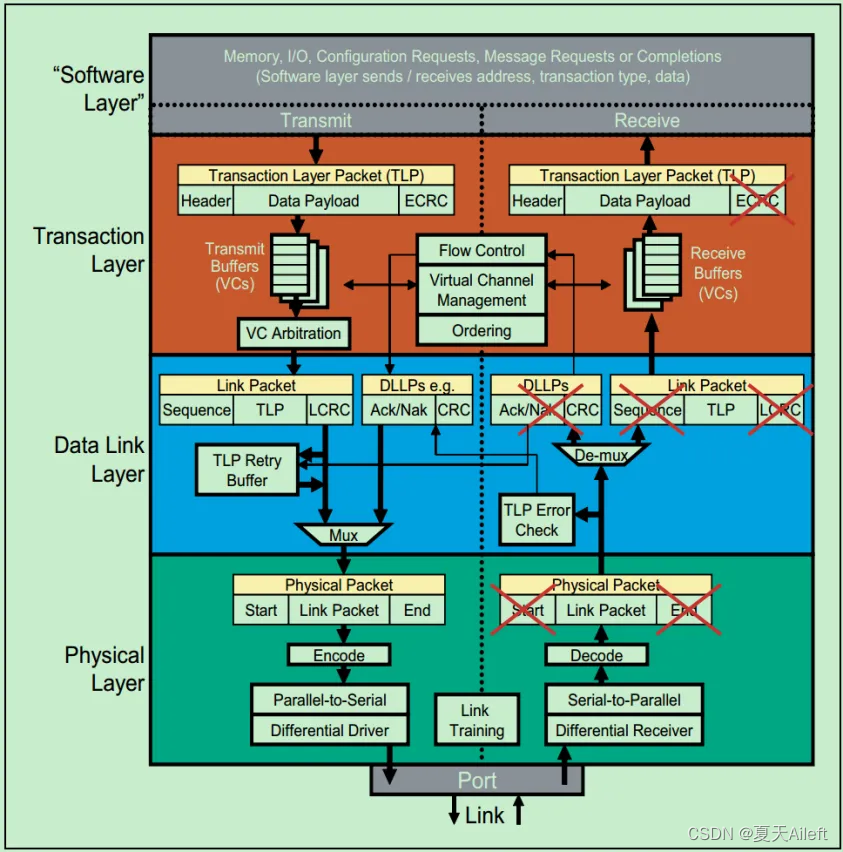
2.1 事务层(Transaction Layer):
接收端的事务层负责事务层包(Transaction Layer Packet,TLP)的解码与校检,发送端的事务层负责TLP的创建。此外,事务层还有Qo(Quality of Service)和流量控制(Flow Control)以及Transaction Ordering等功能。
2.1 数据链路层(Data Link Layer):
数据链路层负责数据链路层包(Data Link Layer Packet,DLLP)的创建,解码和校检。同时,本层还实现了Ack/Nak的应答机制。
2.3 物理层(Physical Layer):
物理层负责Ordered-Set Packet的创建于解码。同时负责发送与接收所有类型的包(TLPs、DLLPs和Ordered-Sets)。当前在发送之前,还需要对包进行一些列的处理,如Byte Striping、Scramble(扰码)和Encoder(8b/10b for Gen1&Gen2, 128b/130b for Gen3& Gen4)。对应的,在接收端就需要进行相反的处理。此外,物理层还实现了链路训练(Link Training)和链路初始化(Link Initialization)的功能,这一般是通过链路训练状态机(Link Training and Status State Machine,LTSSM)来完成的。
需要注意的是,在PCIe体系结构中,事务层,数据链路层和物理层存在于每一个端口(Port)中,也就是说Switch中必然存在一个以上的这样的结构(包括事务层,数据链路层和物理层的)。一个简化的模型如下图所示:
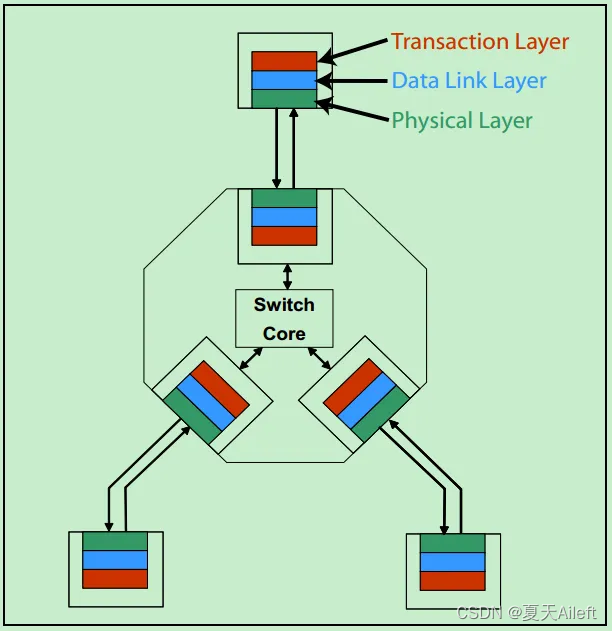
关于事务层,数据链路层和物理层的详细的功能图标如下图所示:
3 PCIE速率计算
链路宽度 (Link Width)
每个通道的数据速率 (Data Rate per Lane)
编码效率 (Encoding Efficiency)
转移速率 (Transfer Rate)
- 链路宽度 (Link Width)
链路宽度是指PCIe连接的通道数量。常见的链路宽度有 x1, x2, x4, x8, x16等,其中x1表示一个通道,x16表示十六个通道。 - 每个通道的数据速率 (Data Rate per Lane)
每个PCIe版本有其固定的数据传输速率。例如,PCIe 3.0的速率是8 GT/s(GigaTransfers per second),而PCIe 4.0是16 GT/s。 - 编码效率 (Encoding Efficiency)
从PCIe 3.0开始,采用了128b/130b的编码方式,意味着每130位数据有128位是有效载荷,编码效率在此种情况下是 128/130 ≈ 98.46%。对于PCIe 1.x/2.x,采用的是8b/10b编码,效率为 80%。 - 转移速率 (Transfer Rate)
这是PCIe通道的“有效”数据传输速率,计算时需要将编码效率考虑在内。
计算示例
以PCIe 3.0 x4为例:
链路宽度:x4(4个通道)
数据速率:8 GT/s(每秒8亿次传输)
编码效率:128b/130b,约等于 98.46%
计算单个通道的有效数据速率:
8 GT/s * 128/130 ≈ 7.88 Gbps(每通道的有效速率)
然后,计算总的有效数据速率:
7.88 Gbps * 4 = 31.52 Gbps
而实际中经常使用字节作为单位,因此我们需要将速率转换成字节为单位。
要注意的是,1字节(Byte) = 8位(bit)。所以:
31.52 Gbps / 8 ≈ 3.94 GB/s(GigaBytes per second)
所以,PCIe 3.0 x4的理论最大传输速率为3.94 GB/s。
PCIE各代的理论速率比较
下表是各个常见的PCIe版本在单通道(x1)上的理论最大传输速率,假设编码效率分别是80%和98.46%:
PCIe版本 每通道速率 编码方式 编码效率 理论最大速率(每通道)
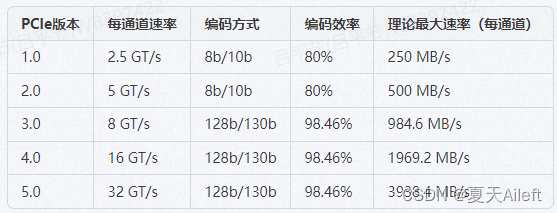
为了得到其他链路宽度(比如x2, x4, x8, x16)的速率,只需将上表中的每通道速度乘以相应的链路宽度即可。注意,上述速率是理论值,实际传输速率可能会因为协议开销、系统延迟等各种因素而有所不同。



















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











