







3.3 CXL.mem
3.3.1 Introduction (介绍)
CXL 内存协议称为 CXL.mem,它是 CPU 和内存之间的事务接口。 跨芯片通信时,它使用 Compute Express Link (CXL) 的物理层和链路层。 该协议可用于多种不同的内存连接选项,包括当内存控制器位于主机 CPU 中时、当内存控制器位于加速器设备中时或当内存控制器移动到内存缓冲芯片时。 它也适用于不同的内存类型(易失性、持久性等)和配置(平面、分层等)。
CPU 中的一致性引擎使用 CXL.mem 请求和响应与内存 (Mem) 连接。 在此配置中,CPU 一致性引擎被视为 CXL.mem 主设备,Mem 设备被视为 CXL.mem 从设备。
CXL.mem 主代理是负责获取 CXL.mem 请求(读取、写入等)的代理,CXL.mem 从属代理是负责响应 CXL.mem 请求(数据、完成等)的代理 .)。
当从属是加速器时,CXL.mem 协议假定存在设备一致性引擎 (DCOH)。 假设该代理负责实现一致性相关功能,例如基于 CXL.mem 命令的设备缓存监听和元数据字段的更新。 对带有元数据的内存的支持是可选的,但这需要提前与主机协商。 协商机制超出了本规范的范围。 如果设备附加内存不支持元数据,DCOH 仍需要使用主机提供的元数据更新来解释命令。 如果设备附加内存支持元数据,则主机可以使用它来实现 CPU 套接字的粗略探听过滤器。
CXL.mem 从主节点到下级节点的交易称为“M2S”,从下级节点到主节点的交易称为“S2M”。
在 M2S 事务中,有两种消息类别:
• 不带数据的请求 - 一般称为请求 (Req):这些请求通常用于读取操作,比如对从设备中的内存或控制寄存器进行读取请求。这些请求不需要传输任何数据,仅需要从设备响应是否可以执行操作或返回其他状态信息。
• 带有数据的请求 - (RwD):这些请求通常用于写入操作,即主设备向从设备发送数据以在其内存或寄存器中写入。请求会包含需要写入的数据。
类似地,在S2M事务中,有两种消息类别:
• 无数据响应 - 一般称为无数据响应 (NDR):当从设备处理完主设备的请求后,如果不需要返回数据,它会发送一个无数据响应。例如,一个读取操作的确认或一个写入操作的完成信号。
• 数据响应 - 一般称为数据响应 (DRS): 如果主设备请求的是读取操作,从设备会在处理完请求后返回数据。这种响应包含了请求读取的数据。
接下来的部分详细描述上述消息类和操作码。
3.3.2 QoS Telemetry for Memory(内存 QoS 遥测)
内存 QoS 遥测是内存设备在 CXL.mem 请求的每个响应消息中指示其当前负载级别 (DevLoad) 的机制。 这使得主机能够根据其负载级别来计量对部分设备、单个设备或设备组的 CXL.mem 请求速率,从而优化这些内存设备的性能,同时限制结构拥塞。 这是
对于包含多种内存类型(例如 DRAM 和持久内存)和/或多逻辑设备 (MLD) 组件的 CXL 层次结构尤其重要。
QoS 遥测的某些方面对于当前的 CXL 内存设备是强制性的,而其他方面是可选的。 CXL 交换机对于支持 QoS 遥测没有独特的要求。 强烈建议主机按照本节中包含的参考模型的指导支持 QoS 遥测。
3.3.2.1 QoS Telemetry Overview(QoS 遥测概述)
QoS 遥测的总体目标是让内存设备向其关联主机提供即时且持续的 DevLoad 反馈,以用于动态调整主机请求速率限制。 如果一个设备或一组设备过载,关联的主机会增加其请求速率限制量。 如果此类设备成为
如果未充分利用,关联的主机会减少其请求速率限制量。 QoS 遥测旨在帮助主机避免补偿过度或补偿不足。
主机内存请求速率限制是可选的,并且主要是特定于实现的。

为了更优化地适应支持多种类型存储器的存储器设备,允许设备实现多个QoS等级,这些QoS等级是已识别的流量组,在这些流量组之间,设备支持差异化的QoS和显着的性能隔离。 例如,同时支持 DRAM 和持久性的设备
内存可能会实现两个 QoS 类别,每个类别对应受支持的内存类型。
提供显着的性能隔离可能需要独立的内部资源; 例如,每个 QoS 类别的单独请求队列。
此版本的规范不提供用于在设备 QoS 类别之间提供带宽管理的架构控制。
MLD 在每个 LD 的基础上提供差异化的 QoS。 MLD 具有架构控制,指定当 MLD 过载时为每个 LD 分配的带宽比例。 当 MLD 未过载时,LD 可以使用超过其分配的带宽部分的内容,最多可达基于最大持续设备带宽的指定部分限制。
CXL 1.1 内存设备的 DevLoad 指示将始终指示轻负载,从而允许这些设备尽可能与支持 QoS 遥测的主机一起运行,尽管它们无法让主机主动计量其内存请求率。 如果任何 CXL 1.1 设备与当前内存设备共享相同的主机调节范围,则使用轻负载而不是最佳负载。 如果 1.1 设备要指示最佳负载,它们将掩盖任何指示轻负载的当前设备的 DevLoad。
3.3.2.2 Reference Model for Host Support of QoS Telemetry(QoS 遥测主机支持的参考模型)
强烈建议主机支持 QoS 遥测,但不是强制性的。
QoS 遥测不为主机 QoS 遥测提供架构控制。 但是,如果主机对给定根端口下方的多组不同的内存设备实施独立节流,则节流必须基于 HDM 范围(称为主机节流范围)。
本节中的参考模型涵盖了主机应如何支持 QoS 遥测的建议方面。 这些方面不是强制性的,但它们应该有助于最大限度地提高 QoS 遥测在优化内存设备性能方面的有效性,同时提供差异化的 QoS 并减少 CXL 结构拥塞。
假设每个主机在节流范围的基础上支持不同的节流级别,由 Throttle[Range] 表示。 Throttle[Range] 通过概念参数 NormalDelta 和 SevereDelta 定期调整。 在给定 Throttle[Range] 的每个采样周期内,主机记录为该限制范围报告的最高 DevLoad 指示,称为 LoadMax。
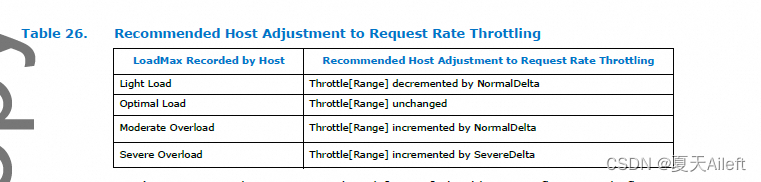
Throttle[Range] 的任何增量或减量不应溢出或下溢合法值。
除非需要更立即的调整,否则预计每 tH 纳秒定期调整 Throttle[Range]。 tH 参数应该可以通过特定于平台的软件进行配置,并且最好可以在每个节流范围的基础上进行配置。
当tH到期时,主机应根据LoadMax更新Throttle[Range],如表26所示,然后将LoadMax重置为其最小值。
往返结构时间是请求消息从主机传输到设备的时间加上响应消息从设备传输到主机的时间之和。 预计 tH 的最佳值略大于相关设备组的平均往返结构时间; 例如,几百纳秒。 为了避免主机过度补偿,在主机进行新的调整之前,接收到的 DevLoad 指示响应流需要时间来反映最后的 Throttle[Range] 调整。
如果主机收到中度过载或严重过载指示,强烈建议主机立即进行节流调整,而无需等待当前tH采样周期结束。 之后,主机应重置 LoadMax,然后等待 tH 纳秒,然后再进行额外的节流调整,以避免过度补偿。
3.3.2.3 Memory Device Support for QoS Telemetry(QoS 遥测的内存设备支持)
3.3.2.3.1 QoS Telemetry Register Interfaces(QoS遥测寄存器接口)
MLD 必须支持 MLD 组件命令集中的一组指定的 MLD 命令,如第 7.6.7.5 节中所述。 这些 MLD 命令提供对各种架构功能、控制和状态寄存器的访问,供 Fabric Manager 通过 FM API 使用。
如果 SLD 支持内存设备命令集,则它必须支持一组指定的 SLD QoS 遥测命令。 参见第 8.2.9.5 节。 这些 SLD 命令提供对各种架构功能、控制和状态字段的访问,以便系统软件通过 CXL 设备寄存器接口进行管理。 每个“架构的 QoS 遥测”寄存器都可以通过上述 MLD 命令、SLD 命令或两者访问。
3.3.2.3.2 Memory Device QoS Class Support(内存设备 QoS 等级支持)
每个CXL存储器设备可以支持一个或多个QoS类别。 预期的典型数量是一到四,但也不排除更高的数量。 如果设备仅支持一种类型的媒体,则它通常支持一种 QoS 类别。 如果设备支持两种类型的媒体,则它通常支持两种 QoS 类别。 支持多个QoS等级的设备被称为多QoS设备。
此版本的规范不提供用于在设备 QoS 类别之间提供带宽管理的架构控制。 尽管如此,强烈建议多 QoS 设备独立跟踪和报告不同 QoS 类的 DevLoad 指示,并且实现提供尽可能多的性能隔离
尽可能在不同的 QoS 类别之间。
3.3.2.3.3 Memory Device Internal Loading (IntLoad)( 存储设备内部加载(IntLoad))
CXL 存储设备必须连续跟踪其内部负载,称为 IntLoad。 多 QoS 设备应基于每个 QoS 类来执行此操作。
设备必须至少根据其内部请求排队来确定 IntLoad。 例如,简单的设备可以监视瞬时请求队列深度以确定要报告四个 IntLoad 指示中的哪一个。 它还可能包含其他
内部资源利用率,如表 27 所示。

IntLoad 确定的实际方法是特定于设备的,但强烈建议多 QoS 设备为每个 QoS 类别实现单独的请求队列。 对于复杂的设备,建议它们根据内部资源利用率来确定 IntLoad,而不仅仅是请求队列深度监控。
尽管本节中描述的 IntLoad 是确定设备响应中返回哪个 DevLoad 指示的主要因素,但根据具体情况,还有其他因素可能会发挥作用。 请参见第 3.3.2.3.4 节和第 3.3.2.3.5 节。
3.3.2.3.4 Egress Port Backpressure
略
3.3.2.3.5 Temporary Throughput Reduction(暂时减少吞吐量)
在某些情况下,设备可能会暂时降低其吞吐量。 设想的示例包括正在进行介质维护的 NVM 设备、由于功率/热量原因而削减其吞吐量的设备以及执行刷新的 DRAM 设备。 如果设备暂时显着降低其吞吐能力,则可以通过在情况发生前不久且仅在真正必要的情况下在其响应中指示中度过载或严重过载来帮助缓解这种情况。 这是一个特定于设备的可选机制。
临时吞吐量减少机制可以向关联主机发出主动的高级警告,然后主机可以及时增加其限制,以避免设备的内部请求队列填满并可能导致入口端口拥塞。 提供高级警告的最佳时间量是高度特定于设备的,并且是多个因素的函数,包括当前请求速率、设备内部缓冲量、吞吐量减少的级别/持续时间以及结构往返时间 。
除非条件真正保证其使用,否则设备不应使用该机制。 例如,如果设备当前处于轻负载状态,则可能没有必要或不适合指示过载状况来为即将发生的事件做准备。
同样,指示过载条件的设备不应继续指示超过真正需要的过载条件。
临时吞吐量减少支持的能力位和临时吞吐量减少启用控制位是架构的 QoS 遥测位,其指示对此可选机制的支持以及启用或禁用它的方法。
3.3.2.3.6 DevLoad Indication by Multi-QoS & Single-QoS SLDs(通过多 QoS 和单 QoS SLD 进行开发负载指示)
对于 SLD,每个响应中返回的 DevLoad 指示由设备的 IntLoad、出口端口拥塞状态和临时吞吐量减少状态的最大值确定,如第 3.3.2.3.3 节、第 3.3.2.3.4 节和第 3.3.2.3.4 节中所述。 3.3.2.3.5。 例如,如果 IntLoad 指示轻负载,出口端口拥塞指示中度过载,并且临时吞吐量减少不指示过载,则响应的结果 DevLoad 指示为中度过载。
3.3.2.3.7 DevLoad Indication by Multi-QoS & Single-QoS MLDs
略
3.3.2.3.8 Egress Port Congestion Measurement Mechanism(出口端口拥塞测量机制)
该硬件机制以滚动百分比为基础测量平均出口端口拥塞情况。
FCBP(流量控制背压):该二进制条件指示出口端口的瞬时状态。 如果端口有可用于传输的消息或 flits,但由于缺乏合适的流量控制信用而无法传输其中任何一个,则为 true。
反压采样间隔寄存器:该架构控制寄存器指定 FCBP 采样的固定间隔(以纳秒为单位)。 它的范围是 0-31。 记录了一百个样本,因此设置为 1 会产生 100 纳秒的历史记录。 设置为 31 会产生 3.1 微秒的历史记录。 设置为 0 会禁用测量机制,并且它必须指示平均拥塞百分比为 0。
BPhist[100] 位数组:存储 FCBP 的 100 个最新样本。 它无法通过软件访问。 反压平均百分比:当读取该架构状态寄存器时,它指示 BPhist[100] 中当前设置位的数量。 其值范围为 0 到 100。
BPhist[100] 和背压平均百分比的实际实现是特定于设备的。 这是一种可能的实现方法:
• BPhist[100] 是移位寄存器
• 背压平均百分比是一个向上/向下计数器
• 对于每个新的 FCBP 样本:
— 如果新样本(尚未在 BPhist 中)和 BPhist 中最旧的样本均为 0b 或均为 1b,则不会对背压平均百分比进行任何更改。
— 如果新样本为 1b,最旧样本为 0b,则增加背压平均百分比。
— 如果新样本为 0b,最旧的样本为 1b,则减少背压
平均百分比。
• Shift BPhist[100],丢弃最旧的样本并输入新样本
3.3.2.3.9 Recent Transmitted Responses Measurement (最近传输的响应测量机制)Mechanism
该硬件机制测量配置时间段的最近 16 个时间间隔内每个 LD 最近传输的响应数量。
完成收集间隔寄存器:该架构控制寄存器指定在活动 Hist 寄存器中对传输的响应进行计数的间隔。 它的范围是0-127。 设置为 1 会产生 16 ns 的历史记录。 设置为 127 会产生约 2 微秒的历史记录。 设置为 0 将禁用测量机制,并且它必须指示
响应计数为 0。
CmpCnt[LD, 16] 寄存器; 这些寄存器跟踪每个 LD 最近传输的响应总数。 CmpCnt[LD, 0] 是计数器,是最新值,而 CmpCnt[LD, 1:15] 是寄存器。 这些寄存器对软件来说不是直接可见的。
对于每个 LD,在每个完成收集间隔结束时:
• 16 个 CmpCnt[LD, *] 寄存器值从较新的值移至较旧的值
• CmpCnt[LD, 15] Hist 寄存器值被丢弃
• CmpCnt[LD, 0] 寄存器被清零,并且它对下一个内部传输的响应进行计数。
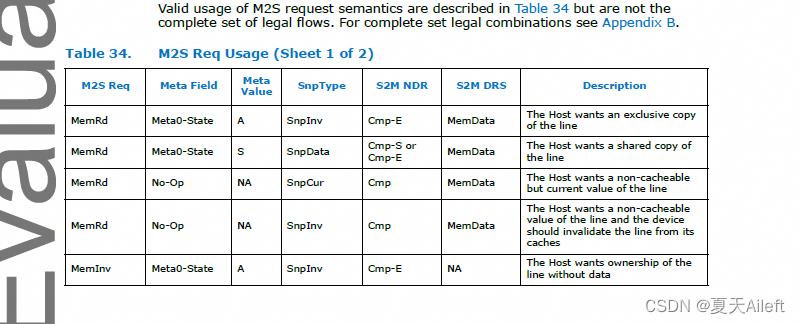
3.3.3 M2S Request (Req)(M2S 请求 (Req))
Req 消息类本质上包含从主设备到从设备的读取、无效和信号。
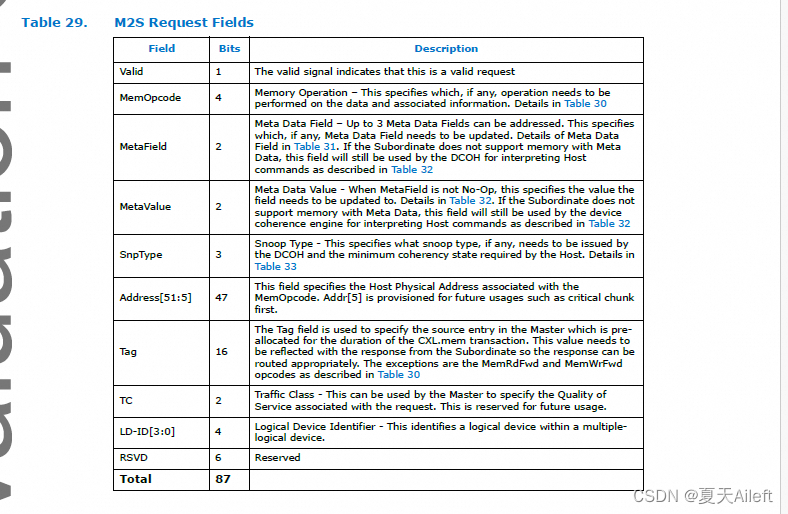
Valid (1 bit): 有效信号表明这是一个有效的请求。如果这个位被设为1,那么接收方应该对这个请求进行处理。
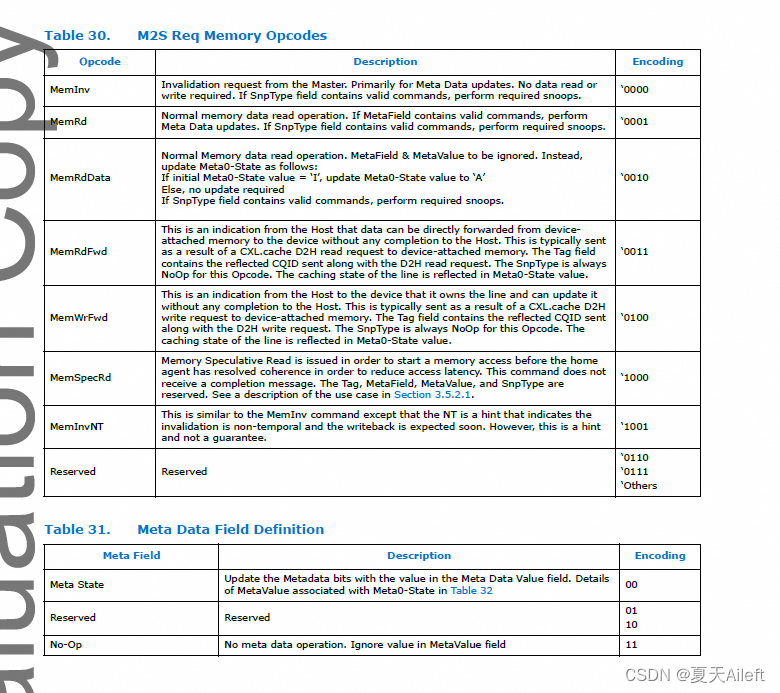
MemOpcode (4 bits): 内存操作码,指定需要对数据和相关信息执行的操作。这在表30中有具体的定义。
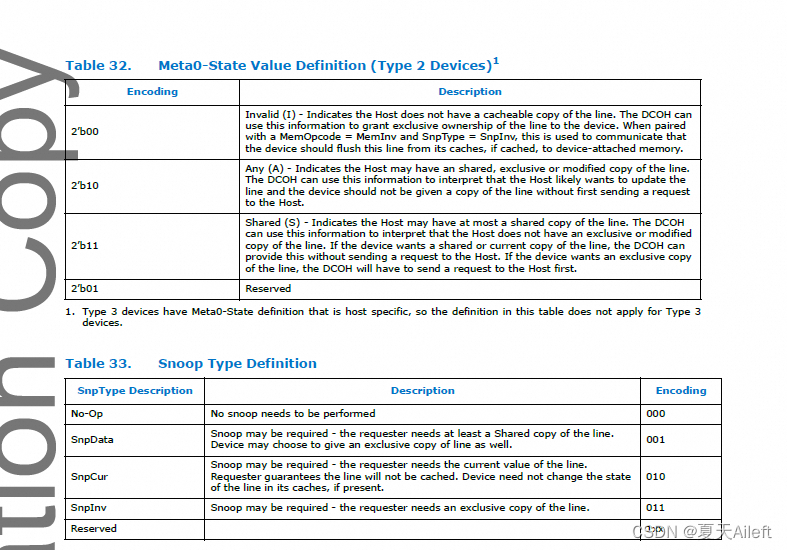
MetaField (2 bits): 元数据字段,可以寻址最多3个元数据字段。这表明哪个元数据字段需要被更新(如果有的话)。元数据字段的详细信息在表31中。如果从设备不支持带元数据的内存,DCOH(Device Coherence Hub)仍将使用该字段来解释主机命令,如表32所述。
MetaValue (2 bits): 元数据值,当MetaField不是无操作(No-Op)时,这指定字段需要更新到的值。详情见表32。如果从设备不支持带元数据的内存,设备一致性引擎会使用此字段来解释主机命令,如表32所述。
SnpType (3 bits): 嗅探类型,指定由DCOH发出的嗅探类型(如果有的话)及主机要求的最低一致性状态。详情见表33。
Address[51:5] (47 bits): 指定与MemOpcode关联的主机物理地址。Addr[5]为未来使用(如关键块首先到达)预留。
Tag (16 bits): 标签字段用于指定Master中预分配的源条目,该条目在CXL.mem事务期间保持分配状态。这个值需要在从设备的响应中反映出来,以便正确路由响应。MemRdFwd和MemWrFwd操作码是例外,如表30所述。
TC (2 bits): 流量类别,主设备可以使用它来指定与请求相关的服务质量。目前保留以备将来使用。
LD-ID[3:0] (4 bits): 逻辑设备标识符,用于识别一个包含多个逻辑设备的单个逻辑设备。
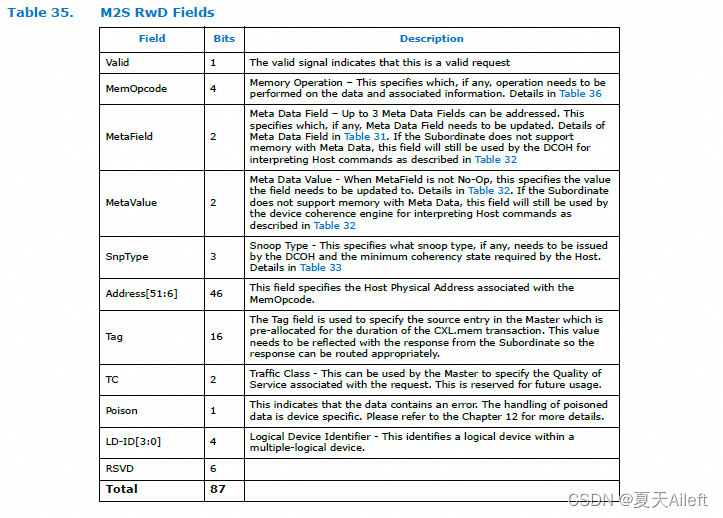
3.3.4 M2S Request with Data (RwD)(带数据的 M2S 请求 (RwD))
带数据的请求 (RwD) 消息类通常包含来自主设备的写入
给下属。
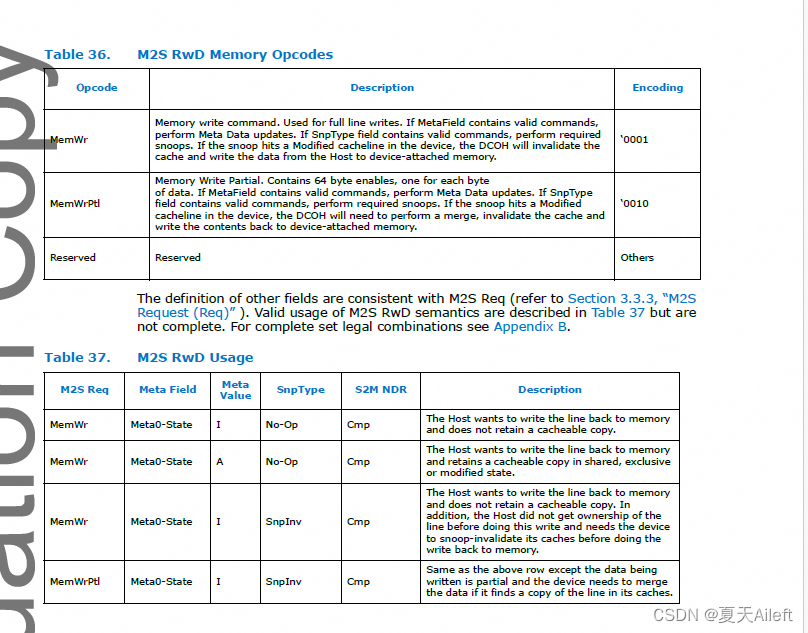
3.3.5 S2M No Data Response (NDR)(S2M 无数据响应 (NDR))
NDR 消息类别包含从下级到主级的完成和指示
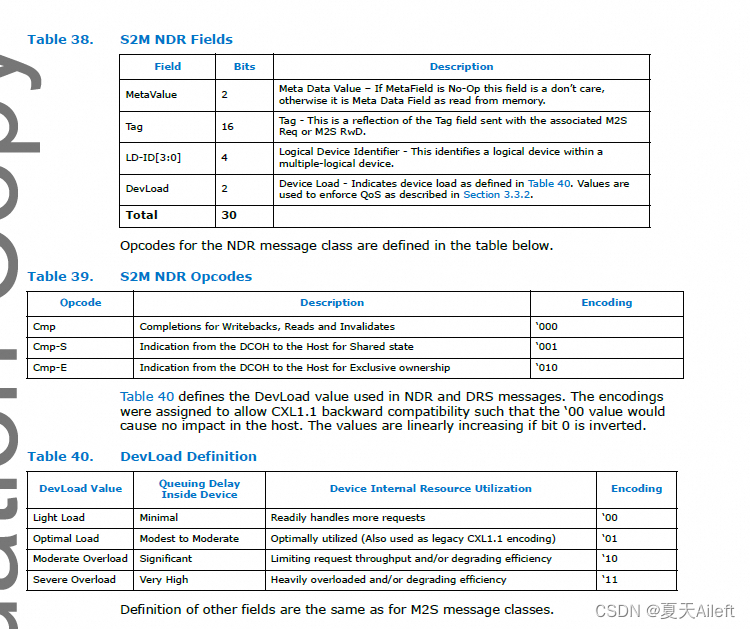
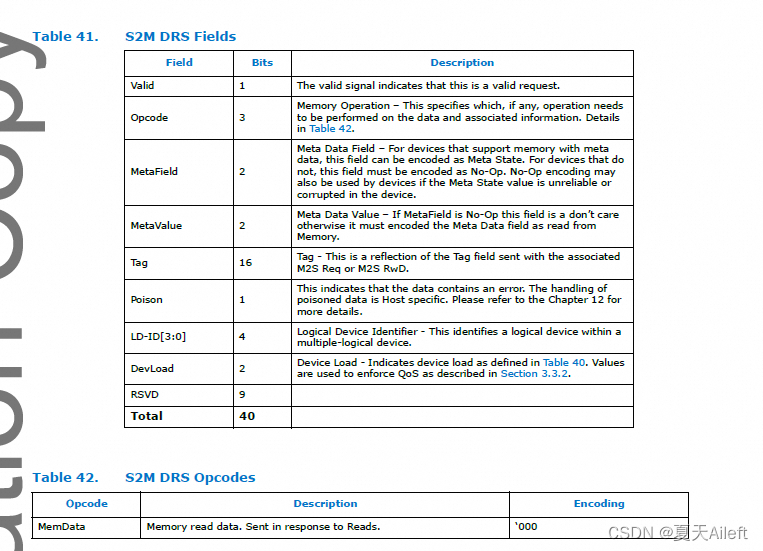
3.3.6 S2M Data Response (DRS)(S2M 数据响应 (DRS))
DRS 消息类包含从从属设备到主设备的内存读取数据。
DRS 消息类别的字段定义如下表所示。
3.3.7 Forward Progress and Ordering Rules
• 每个Req 和RwD 消息类别都需要在多跳结构中的每一跳之间独立记入。 由于目的地缺乏资源而产生的背压是允许的。 然而,这些最终必须耗尽而不依赖于任何其他流量类型。
• 如果请求和MemRdFwd 或MemWrFwd 发送至同一高速缓存行地址,则M2S Req 通道中的CXL.mem 请求不得传递MemRdFwd 或MemWrFwd。
• 原因:如表30 中所述,在M2S Req 通道上发送的MemRdFwd 和MemWrFwd 操作码实际上是对CXL.cache D2H 请求的响应。 某些 CXL.cache D2H 请求的响应位于 CXL.mem M2S Req 通道上的原因是为了确保来自主机的后续请求到同一地址
保持在其后面的顺序。 这允许主机和设备避免竞争条件。
图 40 显示了事务流程的示例。除上述之外,对于 Req、RwD、NDR 和 DRS 消息类别或 Req 消息类别内的不同地址没有排序要求。
• NDR 和DRS 消息类别均需要在源处预先分配。 这保证了响应能够下沉并确保前进。
• 在CXL.mem 上,仅保证写入数据在写入完成后对以后的访问可见。
• CXL.mem 请求需要在设备上取得进展,而不依赖于任何设备发起的请求。 这包括来自 CXL.io 或 CXL.cache 上的设备的任何请求。
• M2S 和S2M 高速缓存行的数据传输必须与其他行没有交错传输。 数据必须按自然块顺序排列,即 64B 传输必须首先完成较低的 32B 一半。
实施说明
有两种绕过设备附加内存的情况,其中消息
M2S RwD 通道可以传递 M2S Req 通道中相同缓存行地址的消息。
- 主机生成的弱有序写入(如图 34 所示)可能会绕过 MemRdFwd 和 MemWrFwd。 结果是弱有序写入可能会绕过设备中较旧的读取或写入。
- 对于设备向主机发起的 RdCurr,主机在解决一致性后将向设备发送 MemRdFwd(如图 37 所示)。 发送 MemRdFwd 后,主机可以拥有该行的独占副本(因为 RdCurr 不会降低目标处的一致性状态),从而允许主机随后修改该行并向该地址发送 MemWr。 这个 MemWr 将
不会针对先前发送的 MemRdFwd 进行排序。
这两个示例都是合法的,因为弱排序存储(在情况#1 中)和 RdCurr(在情况#2 中)不能保证强一致性。
3.4 Transaction Ordering Summary
表 43 记录了上游订购案例,表 44 记录了下游订购案例。 更多详细信息请参见第 3.2.2.1 节(有关 CXL.cache)和第 3.3.7 节(有关 CXL.mem)。 列表示第一个发出的消息,行表示随后发出的消息。 表中的条目表示顺序
两条消息之间的关系。 表项定义如下:
• 是—必须允许第二条消息(行)传递第一条(列)消息,以避免死锁。(发生阻塞时,要求第二条消息传递第一条消息。必须理解公平性,防止饥饿。)
• 是/否—没有订购要求。 第二消息可以选择性地传递第一消息或被第一消息阻止。
• 否– 不得允许第二条消息传递第一条消息。 这是支持协议排序模型所必需的。

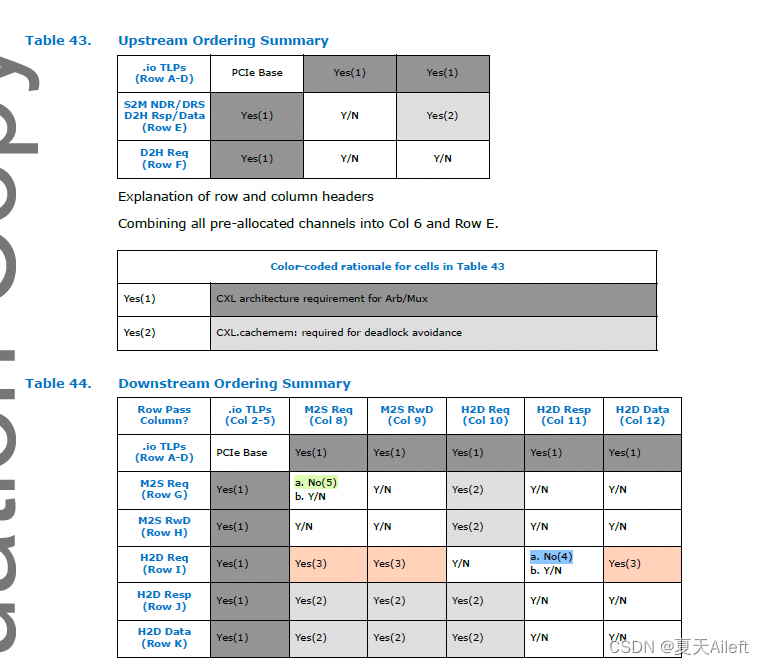
行标题和列标题的说明:
在下行方向,预分配的通道保持独立,因为每个通道都有独特的排序要求。

表项说明:
G8a MemRd*/MemInv* 不得将先前的 MemFwd* 消息传递到相同的缓存行地址。 此规则仅适用于接收 MemFwd* 消息的 Type-2 设备(Type 3 设备不需要实现此规则)。
G8b 规则 G8a 未涵盖的所有其他情况无需订购(是/否)。
I10 当 CXL.cache 设备刷新其缓存时,它必须在发送 CacheFlushed 消息之前等待所有可缓存访问的响应。 这是必要的,因为主机必须仅在所有传输消息完成后观察 CacheFlushed。
I11a 监听不得将先前的 GO* 消息传递到相同的缓存行地址。 GO 消息不携带地址,因此无法从 GO 消息中的 UQID 推断出地址的实现可能需要在所有消息中严格应用此规则。
I11b I11a 未涵盖的其他情况是/否。
3.5 Transaction Flows to Device-Attached Memory
3.5.1 Flows for Type 1 and Type 2 Devices
3.5.1.1 Notes and Assumptions
下面的事务流程图旨在说明主机和设备之间使用第 2.0 节中描述的基于偏差的一致性机制访问设备连接内存的流程。 然而,这些流程并不全面地涵盖每个主机和设备的交互。 下图做出以下假设:
• 该设备包含一个一致性引擎,在下图中称为DCOH。
• DCOH 包含一个Snoop Filter,用于跟踪设备上实现的任何缓存(称为Dev 缓存)。 这不是严格要求的,只要遵守一致性规则,设备就可以自由选择特定于实现的机制。
• DCOH 包含偏差表查找机制。 此操作的实现是特定于设备的。
• 使用红色流程箭头说明的流程的设备特定方面不需要完全符合下图。 这些可以以设备特定的方式来实现。
3.5.1.2 Requests from Host
请注意,无论目标区域的偏置状态如何,本节(来自主机的请求)中显示的流在 CXL 接口上都不会改变。 这实际上意味着设备需要向主机提供一致的响应,如下所示。

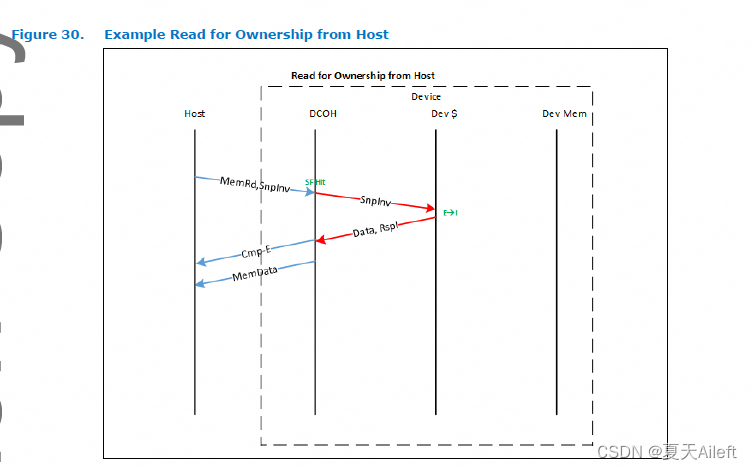
在上面的示例中,主机请求该行的可缓存非独占副本。
请求的非排他性方面是使用“SnpData”语义来传达的。 在此示例中,请求在 DCOH 中命中了窥探过滤器,这导致设备缓存被窥探。 设备缓存将状态从独占降级为共享,并将共享数据副本返回给主机。 使用 Cmp-S 语义向主机告知线路的状态。
在上面的示例中,主机请求该行的可缓存独占副本。 请求的独占方面是使用“SnpInv”语义来传达的,它要求设备使其缓存无效。 在此示例中,请求在 DCOH 中命中了窥探过滤器,这导致设备缓存被窥探。 设备缓存将状态从Exclusive降级为Invalid,并将Exclusive数据副本返回给Host。 使用 Cmp-E 语义向主机告知线路的状态。
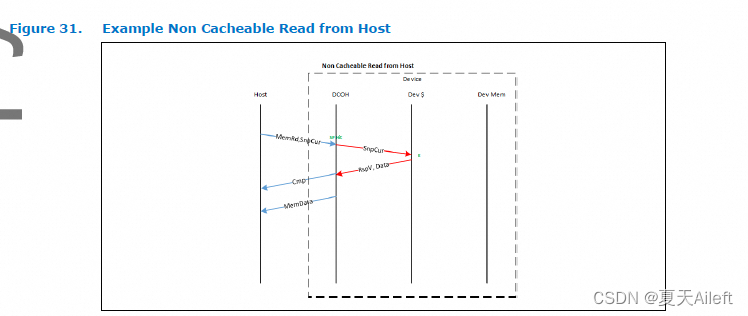
在上面的示例中,主机请求该行的不可缓存副本。 请求的不可缓存方面是使用“SnpCurr”语义来传达的。 在此示例中,请求在 DCOH 中命中了窥探过滤器,这导致设备缓存被窥探。 设备缓存不需要改变其缓存状态; 但是,它提供了数据的当前快照。 主机被告知不允许使用 Cmp 语义缓存该行。

在上面的示例中,主机请求对线路的独占访问,而不要求设备发送数据。 它使用 MemInv 操作码与 MetaValue 为‘10(任意)的设备进行通信,这在本例中很重要。 它还要求设备使用 SnpInv 命令使其缓存无效。 设备使其缓存无效,并为使用 Cmp-E 语义进行通信的主机提供独占所有权。
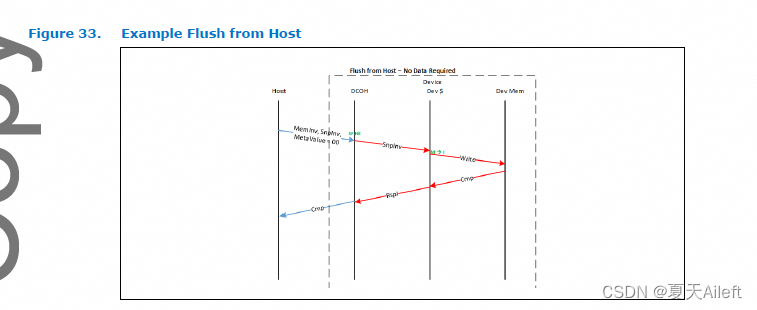
在上面的示例中,主机想要将所有缓存(包括设备缓存)中的一行刷新到设备内存。 为此,它使用 MemInv 操作码、MetaValue 为‘00(无效)和 SnpInv。 设备刷新其缓存并向主机返回 Cmp 指示。
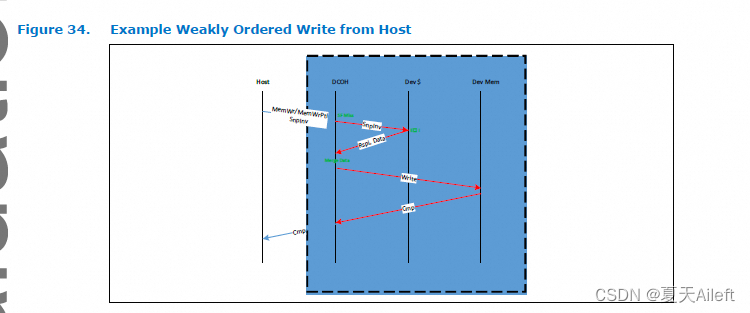
在上面的示例中,主机发出弱有序写入(部分或整行)。 弱有序语义通过嵌入的 SnpInv 进行传达。 在此示例中,设备缓存了该行的副本。 这导致在将其写回内存并向主机发送 Cmp 指示之前在设备内进行合并。

在上面的示例中,主机执行写入操作,同时向设备保证它不再具有该行的有效缓存副本。 事实上,主机不需要监听设备的缓存,这意味着它之前获得了该行的独占副本。
对没有有效缓存副本的保证由 MetaValue '00(无效)表示。
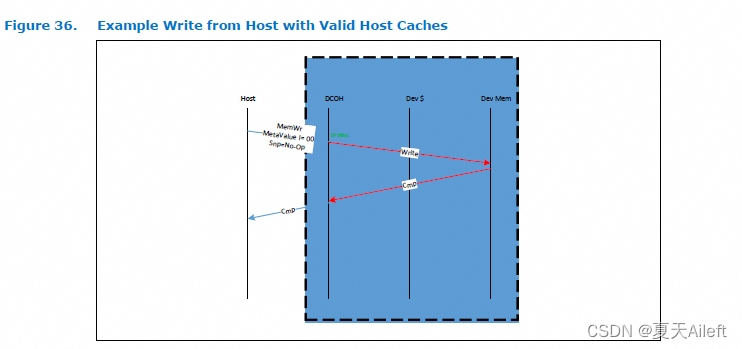
上面的示例与前一个示例相同,只是主机选择在写入后保留该行的有效可缓存副本。 这是使用非“00”(无效)的元值传达给设备的。
3.5.2 Type 2 and Type 3 Memory Flows
略
3.5.2.1 Speculative Memory Read
略
3.6 Flows for Type 3 Devices
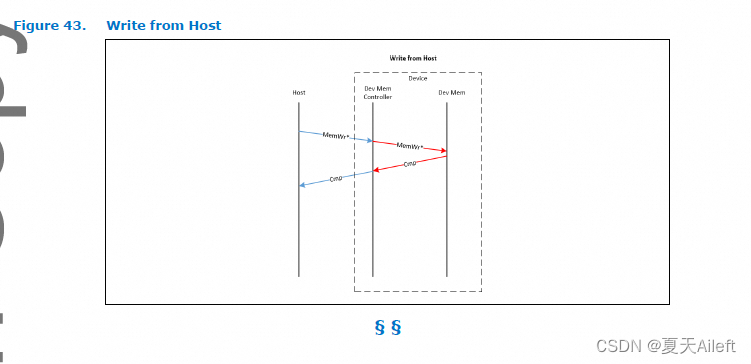
类型 3 设备是内存扩展器,既不缓存主机内存,也不要求主机主动管理设备缓存。 因此,3 类设备没有 DCOH 剂。 因此,主机将这些设备视为分解的内存控制器。 这使得流向 3 类设备的事务流可以简化为只有两个类:读取和写入,如下所示。 图 28 中所示的图例也适用于如下所示的交易流程。
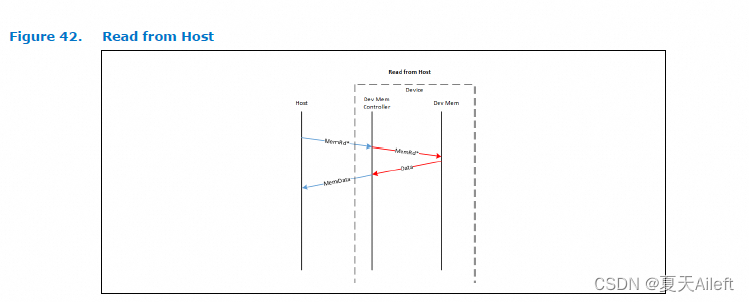
M2S 读取类型 2 设备与类型 3 设备之间的主要区别在于,没有来自类型 3 设备的 S2M NDR 响应消息。 与类型 2 设备一样,对类型 3 设备的写入始终以 S2M NDR Cmp 消息完成。

















 5807
5807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











