







论文链接:https://arxiv.org/pdf/2107.10834.pdf
代码链接:https://github.com/SlongLiu/query2labels
论文研究对象:
1. NUS-WIDE [11]
NUS-WIDE是一个由新加坡国立大学媒体搜索实验室创建的多标签的数据集,包含269,648张图像,81个类。
[11] Tat-Seng Chua, Jinhui Tang, Richang Hong, Haojie Li, Zhiping Luo, and Yantao Zheng. Nus-wide: a real-world web image database from national university of singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, page 48, 2009.
2. PASCAL VOC [18]
PASCAL VOC一个世界级的计算机视觉挑战赛PASCAL VOC的数据集,该论文用了VOC 2007以及VOC 2012数据集,VOC 2007包含5, 011 训练集和4, 952 测试集,VOC 2012包含11, 540 训练集和10, 991 测试集。
[18] Mark Everingham, S. M. Eslami, Luc Gool, Christopher K.Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision, 111(1):98–136, 2015.
3. Visual Genome [30]
Visual Genome是斯坦福大学李飞飞组于2016年发布的大规模图片语义理解数据集,包含108, 249张图像。
[30] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Li Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123(1):32–73, 2017.
4. MS-COCO [35]
MS-COCO是微软团队2014年发布的一个可以用来进行图像识别的数据集,包含122, 218张图片,其中117266训练集,4952验证集,40670测试集。
[35] Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages 740–755, 2014.
COCO2014数据集下载参考:
coco 2014 数据集 下载 免费 不要积分 永不失效_TinaO-O的博客-CSDN博客_coco2014
coco官网需要翻墙,可以在服务器用wget或者curl下载数据:
curl -O 下载网址
wget -c 下载网址
eg:
curl -O http://images.cocodataset.org/zips/train2014.zip解压zip文件夹;
unzip 需要解压的zip文件
eg:
unzip train2014.zip论文提出了一个基于Transformer的多标签分类模型,首次将Transformer的解码器结构用于分类。
摘要:
提出了一种简单有效的方法来解决多标签分类问题。pro提出的方法利用Transformer解码器来查询类标签的存在。Transformer的使用根植于为不同标签自适应地提取局部判别特征的需要,由于一幅图像中存在多个目标,这是一个强烈的属性。Transformer解码器中内置的交叉注意力模块提供了一种有效的方法,可以使用label embeddings作为查询,从视觉主干计算的特征图中探测和池化与类相关的fea图,以进行后续的二进制分类。与之前的工作相比,新的框架简单,使用标准的transformer和视觉骨干,并且有效,在五个多标签分类数据集上始终优于之前的所有工作,包括MS-COCO、PASCAL VOC、NUS-WIDE和Visual Genome。特别是在MS-COCO上建立了91.3%的mAP。我们希望它紧凑的结构、简单的实现和优越的性能成为多标签分类任务和未来研究的强大基线。
依据:
该论文主要参考的是DETR结构[3],将图像输入CNN得到图像特征,然后将得到的图像特征结合位置编码输入Transformer,最后得到的结果是目标检测到的物体以及其所在的位置。

[3] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In European Conference on Computer Vision, pages 213–229. Springer, 2020.
结构:
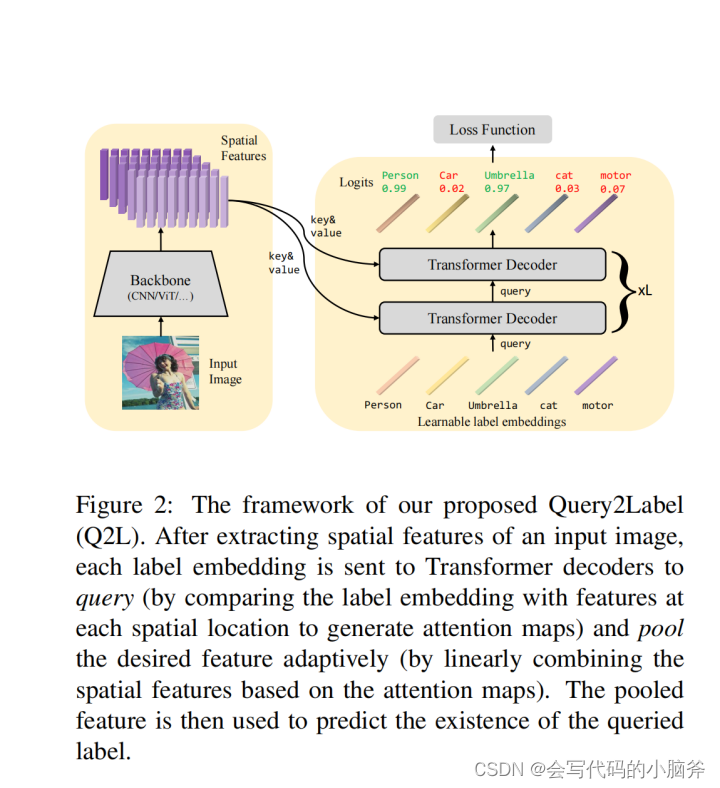
论文中最核心的是TRansformer的Decoder结构[45],可以将Decoder结构与任意的主干网络结合使用。首先将图片输入主干网络,得到图像特征,将图像特征和label embedding输入Decoder,Docoder主要包含一个自注意力模块、交叉注意力模块以及反馈神经网络,每一个Decoder将上一个的Q作为输入,输出下一个Q,自注意力模块将上一层的Q作为输入,将Q加上位置编码作为K和Q,将Q、K、V输入自注意力模块,然后将得到的结果加上位置编码作为Q输入,将主干网络得到的图像特征作为V,将图像特征加上位置编码作为K,输入交叉注意力模块,最后将交叉注意力得到的结果作为FFN的输入,FFN是Feed-Forward Network,FFN包含了两层线性变换,也可以描述成两个卷积核大小为1的卷积层,得到结果Qi。Transfomer的Decoder结构一共有6个,将最后的Decorder得到的结果通过FC层降维,得到最后的每一个标签的概率矩阵。
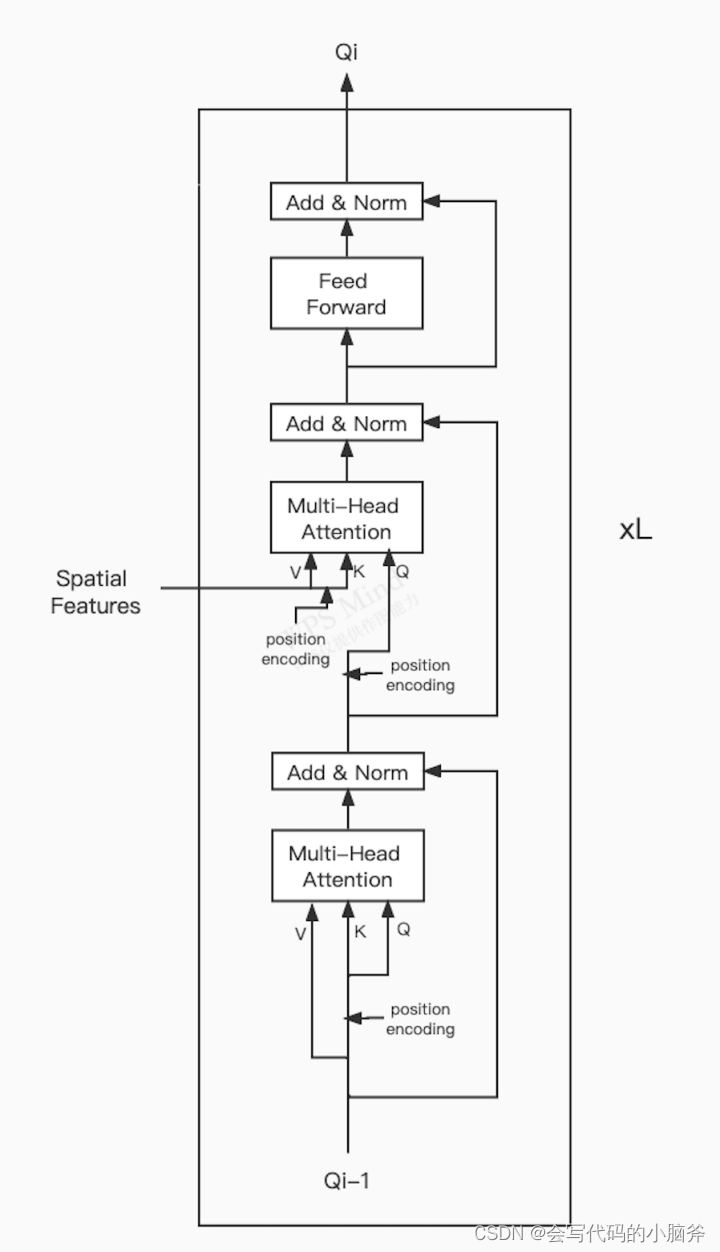
[45] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.

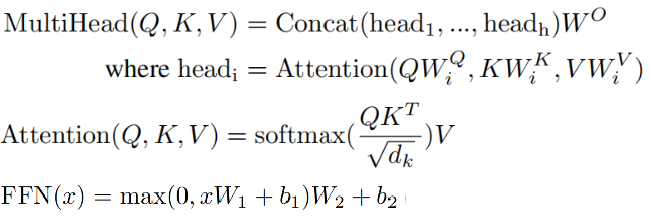
预训练模型下载:https://cloud.tsinghua.edu.cn/d/a1560cd327dc45d0ad8e/
测试预训练:
python q2l_infer.py -a modelname --config json文件路径 pkl文件路径
eg:
python q2l_infer.py -a 'Q2L-R101-448' --config "pretrained/Q2L-R101-448/config_new.json" -b 16 --resume 'pretrained/Q2L-R101-448/checkpoint.pkl'预训练Resnet101作为主干网络,测试的数据集为COCO数据集的结果:
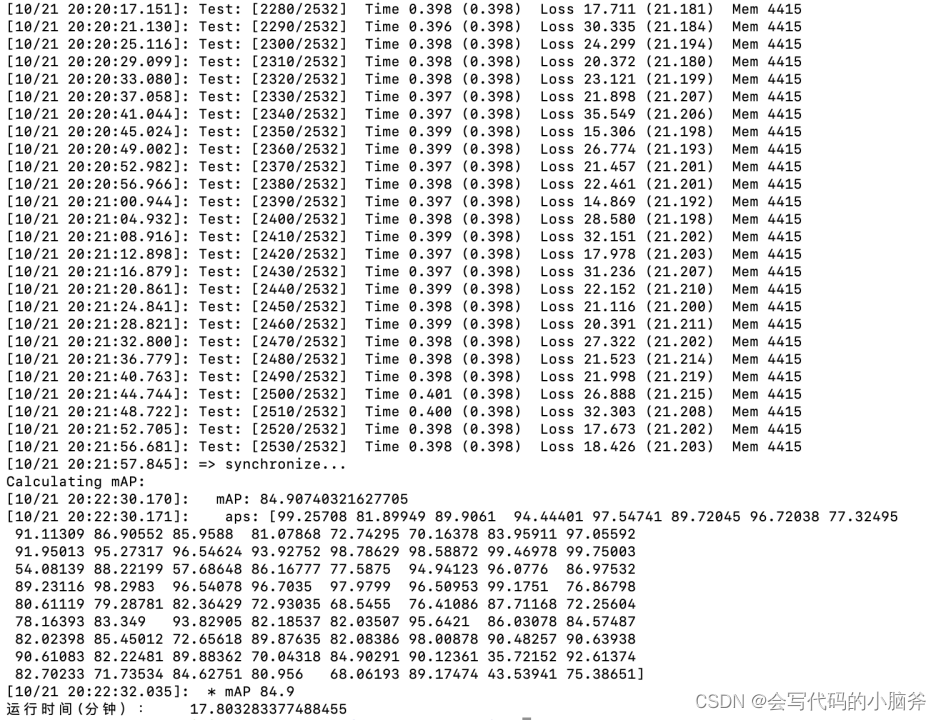
跟论文给的结果一致。
用预训练好的模型跑测试,测试的结果与论文一致,我只跑了把resnat101作为主干网络的模型,其他模型没跑。
但是在训练把resnet101作为主干网络的模型的时候,并没有预期的结果,反而测试出来的mAP只有3.705,效果很差,几个epoch之后出来的loss为nan,具体原因未找到。















 1726
1726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









