






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【RankSeg】获取论文!
后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
后台回复【数据集下载】获取计算机视觉近30种数据集!
1摘要
传统意义上,分割的定义是完整标签的像素分类任务,即对图像或视频中的每个像素,预测固定数量的语义类别。但是,由于类别数是固定的,标准结构将不可避免地在类别范围扩大的真实环境中遇到各种挑战。另一方面,类别不平衡,即少数类别会占据绝大部分的样本数量。基于此,本文将分割分解为两个子问题:1)图像级/视频级的多标签分类;2)像素级秩自适应标签选择分类。即给定输入图像/视频,RankSeg首先对所有标签进行多标签分类,之后进行排序并根据置信度选择一个小的子集。然后,秩自适应像素分类器对选定的标签进行像素分类,进而得到预测结果。本文的方法是通用的,可以简单地使用轻量级多标签分类头和秩自适应像素分类器来提升各种现有的分割框架。总结来说,使用RankSeg,Mask2Former在ADE20K/YouTubeVIS/VSPW数据集上分别提升了+0.8%/+0.7%/+0.7%。
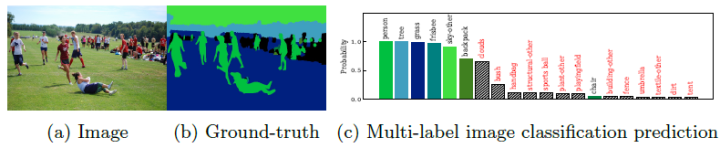
简介
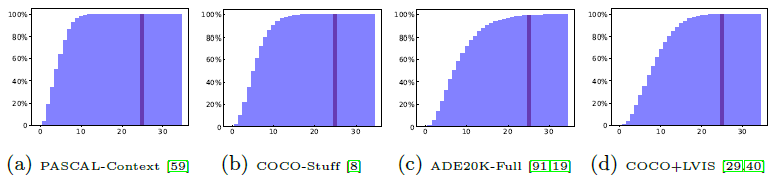
下图绘制了数据集中包含不超过给定类别数目的图像百分比与每个图像中出现的类别数的统计数据,可以看出PASCAL-Context [59]数据集100%的图像包含了60个预定义的类别、COCO-Stuff [8]数据集99.99%的图像包含了171个预定义的类别、ADE20K-Full [19,91]数据集99.14%的图像包含了847个预定义的类别和COCO+LVIS [29,40]数据集99.85的图像包含了1284个预定义的类别。上图显示了仅包含7各类别的示例图像,而数据集包含171类。
基于此,本文将分割任务重新表述为如下两个子问题:
-
多标签图像/视频分割;
-
基于标签子集的秩自适应像素分类。下图总结了基于Segmenter [67]和Mask2Former [18]的结果比较。可以看出,分割性能得到了比较明显的提升。
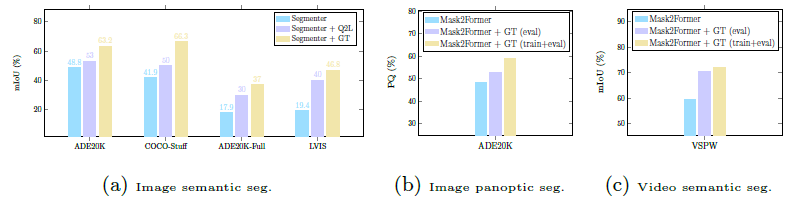
基于多标签可以获得明显的增益,本文提出了两种不同的方案来利用多标签图像预测的优势:
-
独立的单任务方法:训练一个模型用于多标签图像/视频分类,另一个模型进行分割结果预测;
-
联合多任务方案:训练一个主干共享的模型来实现多标签图像/视频的分类和分割。
2方法
整体框架
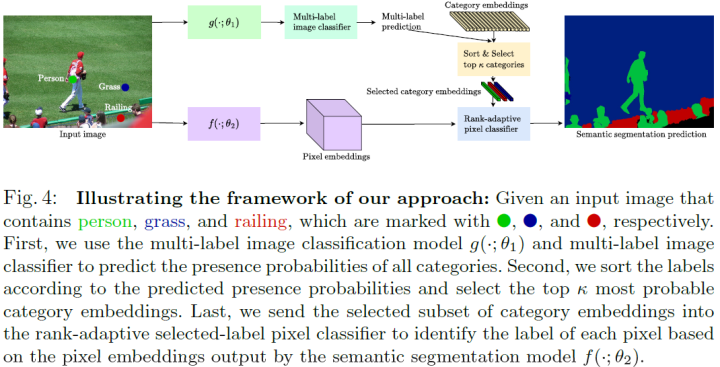 本文的整体框架如上图所示,包括两个分支:多标签图像分类分支和语义分割分支。多标签预测用于排序并选择置信度最高的个类别,然后将其送入秩自适应标签选择像素分类器以输出预测结果。
本文的整体框架如上图所示,包括两个分支:多标签图像分类分支和语义分割分支。多标签预测用于排序并选择置信度最高的个类别,然后将其送入秩自适应标签选择像素分类器以输出预测结果。
多标签图像分类:多标签图像分类的目标是预测给定图像中现有标签的集合。即从标注GT中生成图像级的多标签真值: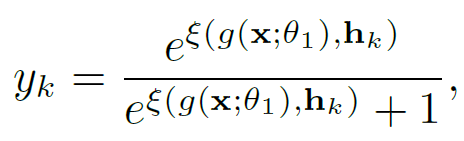 秩自适应标签选择像素分类:语义分割的目的是预测逐像素的语义标签。本文并非从所有K个预定义的类别中输出预测结果,而是基于上一步得到的多标签GT 进行结果预测,即秩自适应选择标签像素分类方案:
秩自适应标签选择像素分类:语义分割的目的是预测逐像素的语义标签。本文并非从所有K个预定义的类别中输出预测结果,而是基于上一步得到的多标签GT 进行结果预测,即秩自适应选择标签像素分类方案:
-
根据多标签预测结果的降序排序并选择置信度最高的前个元素:
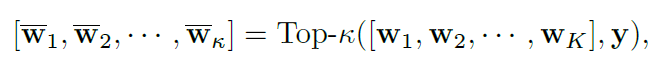
-
对前个选定类别的像素进行秩自适应分类:
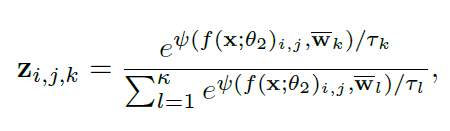 本文还使用了一组秩自适应可学习的温度参数来调整所选前个类别的置信度。
本文还使用了一组秩自适应可学习的温度参数来调整所选前个类别的置信度。
独立单任务方案
在独立单任务的设置下,多标签图像分类和语义分割模型,两个模型参数不共享。具体来说,本文首先训练多标签图像分类模型来获取图像中前个最有可能出现的类别。之后训练秩自适应标签选择像素分类模型,即语义分割模型来预测所选前类上每个像素的标签。
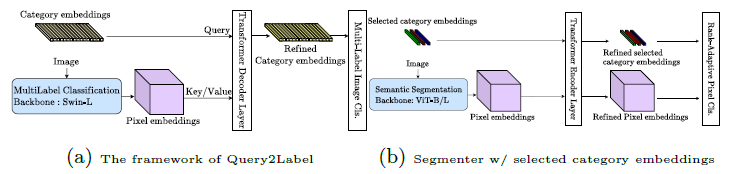
多标签图像分类模型:本文选择了最近SOTA的多标签分类算法Query2Label [53]。Query2Label 的关键思想是使用类别嵌入作为query,以收集所需的像素嵌入作为key/value,主干是Swin-L,自适应地使用一个或两个transformer decoder layers。然后 Query2Label在细化的类别嵌入上应用多标签图像分类器来预测每个类别的存在。下图a是Query2Label算法框架,其模型的参数在本文的训练和推理阶段都是固定的。
秩自适应标签选择像素分类模型:本文选择了一个简单高效的基线分割模型[67],分割模型首先将类别嵌入与ViT模型输出的像素嵌入连接在一起,之后输入到两个transformer encoder layers。最后基于细化的像素嵌入和类别嵌入,分割模型计算ℓ2 归一化标量积作为分割预测结果。本文根据Query2Label模型的预测为每个图像选择最有可能的前个类别,并且只使用选定的前个类别嵌入而不是所有类别嵌入。下图b说明了具有所选类别嵌入的分割模型的整体框架。
联合多任务方案
单任务方案由于引入了Query2Label且基于Swin-L这种大型主干,是有不小的额外计算开销的。因此本文进一步设计了一个联合多任务方法,该方案共享主干网络。
下图是联合多任务方法的整体框架。首先,使用共享的多任务主干网络处理输入图像并输出像素嵌入。其次,类别嵌入与下采样的像素嵌入连接起来输入到transformer encoder中,并使用多标签像素分类器处理细化的类别嵌入进而输出多标签预测结果。最后,对前类进行排序和选择,将选择的类别嵌入和像素嵌入进行连接输入到两层transformer encoder layers中,进一步得到最终的分割预测结果。本文也在消融实验中验证了联合多任务方法是比单任务方案更好的。

3实验结果
消融实验:
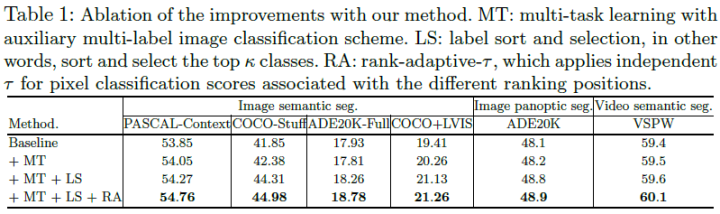
单任务与多任务方案对比:

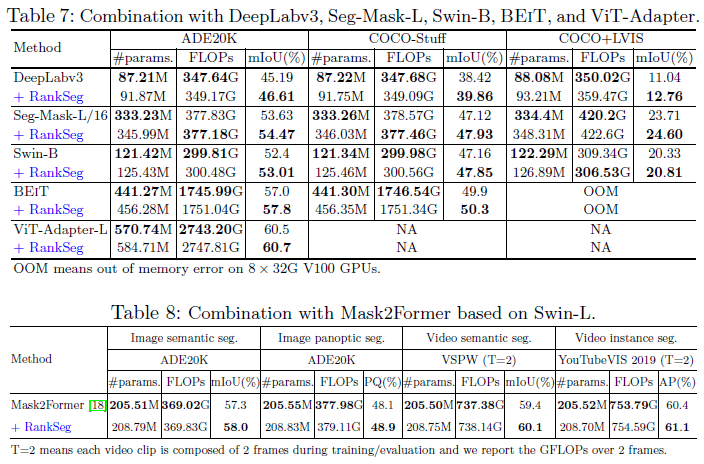
与现有SOTA模型结合:
4汽车人的碎碎念
这篇文章比较有意思,用一个多标签分类器指导分割模型。首先预测个最可能出现的类别,在此之上分割模型再预测结果,相当于减轻了分割模型的压力。直观上的感觉,模型会更聚焦大类,忽略小类。关于这一点,论文也没展开讨论,感觉未来可以研究一下。增加的多标签分类器,参数量和计算量也没加多少,产品上也可以尝试着看看,还是有一定价值的。














 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









