






论文分享:A DRL based cooperative approach for parking space allocation in an automated valet parking system
该论文研究了自主代客泊车(Automated valet parking, AVP)系统中的车位分配(Parking Space Allocation, PSA)问题,利用深度强化学习(Deep reinforcement learning, DRL)来优化车配策略。
论文链接:A DRL based cooperative approach for parking space allocation in an automated valet parking system
1 背景介绍
AVP的支持下,驾驶员停车能够实现完全自主化,包括停车过程中的行驶、泊车和取车任务,整个过程均无需驾驶员进入停车场进行干预,是一个典型的限定区域内低速无人驾驶应用场景。整个AVP系统的实现过程可以简单概括为两个环节:
(1)停车环节:司机首先在指定的下车点下车,并通过一些工具(如APP)提供预计停车时长后即可离开,无需等待停车的完成。然后,系统为车辆分配一个停车位,车辆通过自动驾驶行驶到指定的停车位进行泊车。
(2)取车环节:司机需先到取车点,然后通过手机APP申请取车,车辆将从停车位自动行驶到取车区的司机处,从而完成取车。
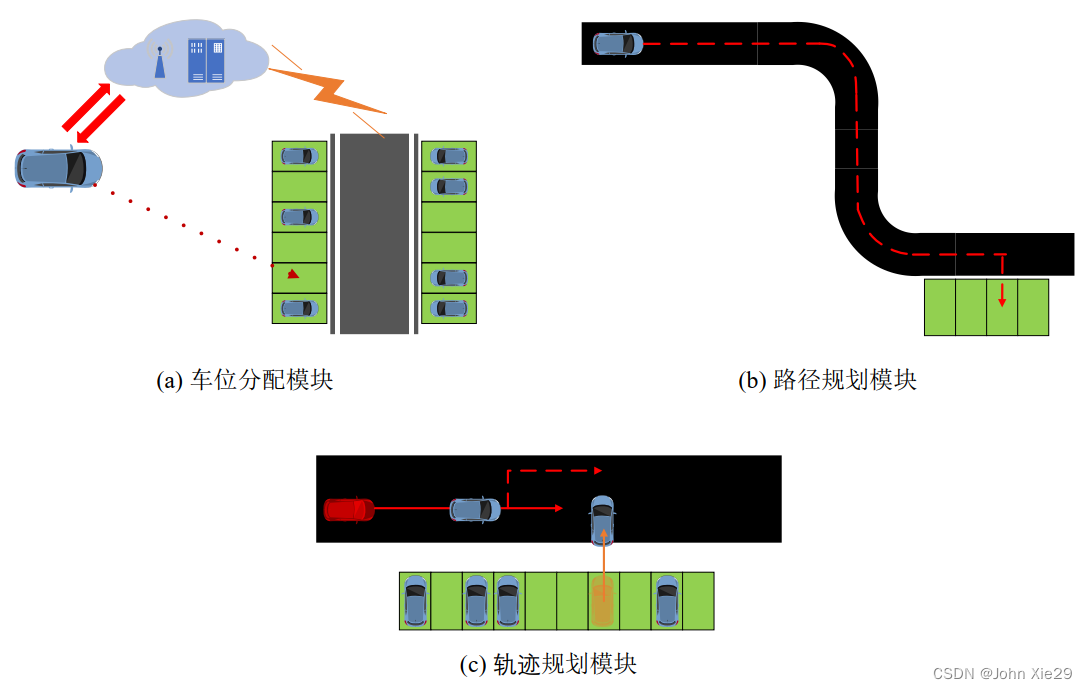
显而易见,AVP系统主要包括三个运行模块,如图1所示。各个模块的主要功能为:
-
车位分配模块:用户申请停车,系统根据分配策略为车辆分配一个合适的停车位;
-
路径规划模块:在车位分配流程完成后,路径规划模块在高精度地图的基础上,为车辆规划一条到达目标车位的路径。该路径是考虑静态因素 (墙壁等静态障碍) 后的最优路径;
-
轨迹规划模块:车辆在停车场内运动时,可能会遭遇各种冲突,如:车辆出入库时与道路上行驶的车辆发生冲突;多个车辆在交叉口发生冲突。轨迹规划模块通过合理的规划车辆运动轨迹状态,保证AVP系统的正常高效运行。
该文章重点研究了利用DRL方法来解决AVP系统中的PSA问题。即:探索一个分配策略,当车辆 T i T_i Ti(已知车辆预计的停车时长 T i T_{i} Ti,粒度为半小时,即 T i ∈ 1800 s , 3600 s , . . . T_i \in {1800s,3600s,...} Ti∈1800s,3600s,...)在 t i t_i ti时刻进入停车场时,为其分配一个车位 a t i a_{t_i} ati。
整体的方法框架如图2:
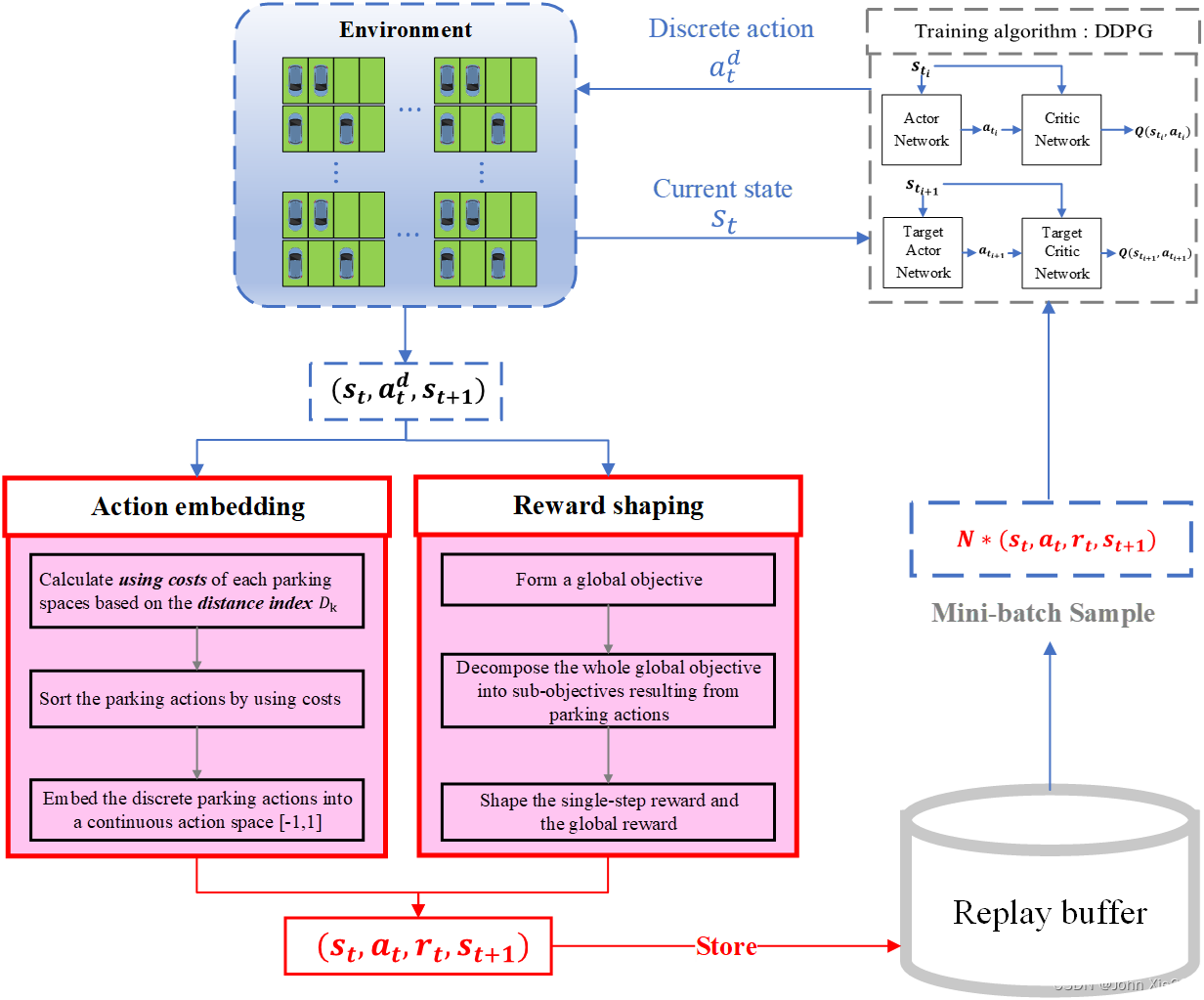
2 MDP框架设计
强化学习下,首先需要将问题转为马尔科夫决策过程(Markov decision process, MDP)形式,宏观上来说,主要就是状态、动作、奖励函数的定义。
2.1 状态与动作
首先,状态和动作的定义是比较清晰的。
- 状态用一个向量表示: S t i = [ O t i , T i , t i ] S_{t_i}=[O_{t_i},T_i,t_i] Sti=[Oti,Ti,ti],其中 O t i = [ o 1 , o 2 , . . . , o k , . . . , o n ] O_{t_i}=[o_1,o_2,...,o_k,...,o_n] Oti=[o1,o2,...,ok,...,on]代表停车位的占用状态, k k k为车位编号,共 n n n个车位,若车位 k k k被占用,则 o k = 1 o_k=1 ok=1,否则为0; T i T_i Ti为预计停车时长; t i t_i ti为申请停车的时刻。
- 动作 a t i a_{t_i} ati则表示为车辆 V i V_i Vi分配的车位,因此 a t i a_{t_i} ati的值对应车位编号。即: a t i ∈ A = [ 0 , 1 , . . . , k , . . . , n ] a_{t_i} \in A=[0,1,...,k,...,n] ati∈A=[0,1,...,k,...,n]。
2.2 奖励函数
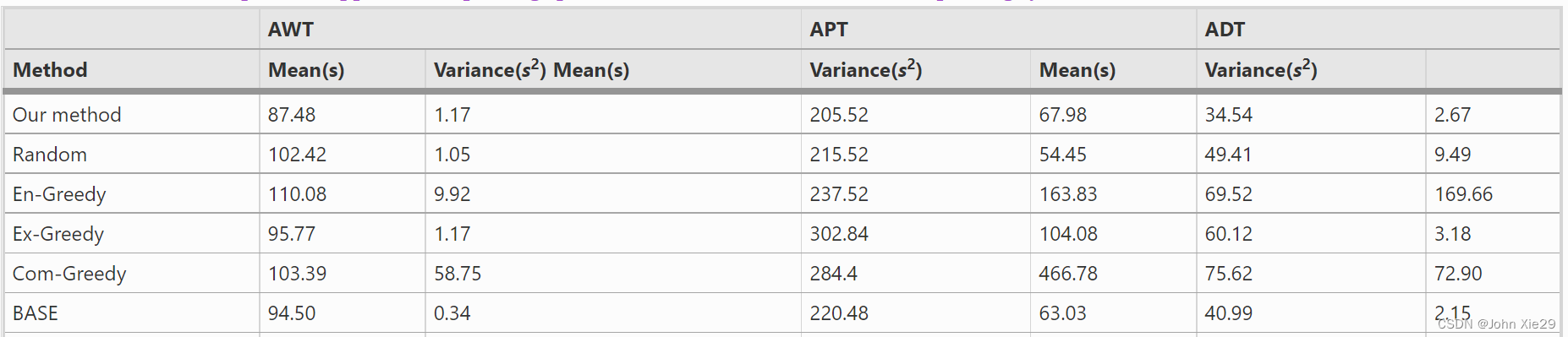
奖励函数的设计是该文章的重点。表1对AVP系统涉及的评价指标进行了比较。从商业落地的角度对这三个指标的重要性进行分析,首先,AVP作为服务于客户的技术产品,应更注重用户体验层次的两个指标。又如2.1.1节所述,停车环节中,司机下车后无需参与停车过程,可直接离开,因此该环节的时间消耗( A P T APT APT)对于用户体验的影响较小;而取车环节需要司机在取车区等待,用户的体验感将随着等待时间( A W T AWT AWT)的增加而下降。因此,本文选择 A W T AWT AWT作为主要指标,用于RL的奖励函数的设计,而 A P T APT APT、 A D T ADT ADT作为辅助分析指标,用于方法评价与分析。
| 指标层次 | 名称 | 符号 | 定义 |
|---|---|---|---|
| 用户体验 | 平均停车时间 | APT | 车辆从下车区行驶到目标车位的平均时间消耗 |
| 用户体验 | 平均等待时间 | AWT | 车辆从停车位行驶到取车区的平均时间消耗 |
| 停车场运行效率 | 平均延误时间 | ADT | 车辆在整个行驶过程中因冲突导致中途停车的时间消耗 |
所以,优化的目标比较明确,就是要尽可能降低用户的等待时间,即最小化 A W T AWT AWT。
基于优化目标,很容易可以设计出一个全局奖励,在agent训练完成后,根据这轮训练展示出的性能( W a W^a Wa,即 A W T AWT AWT的值)确定奖励值,若 W a W^a Wa值低于预设的目标,则基于一个正向的奖励;反之,不给予奖励:
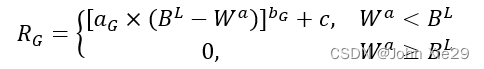
同时,为了避免奖励稀疏问题,最好是每一个动作执行后均能产生一个奖励(单步奖励),而不仅仅依靠上述的全局奖励。但要实现目标,单步奖励的设计一定要与全局目标相适应,否则会出现强化学习的总奖励值很高,系统性能表现却很差的情况。
一个典型的例子是OpenAI的博文Faulty Reward Functions in the Wild,这个赛艇游戏的预定目标是完成比赛。研究人员在这个游戏中设置了两种奖励,一是完成比赛,完成比赛后会给予一个正向奖励(+1),否则不给予奖励(0),二是收集环境中的得分目标。最后OpenAI的智能体找到了一片“农场”反复刷分,虽然没能完成比赛,但它的得分更高。
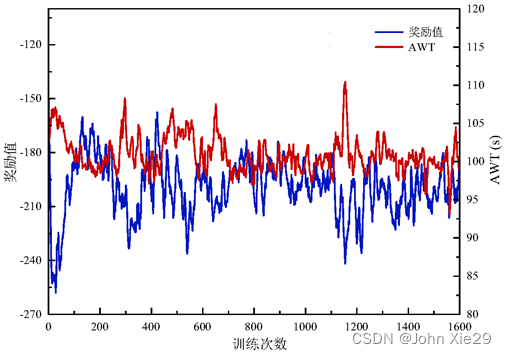
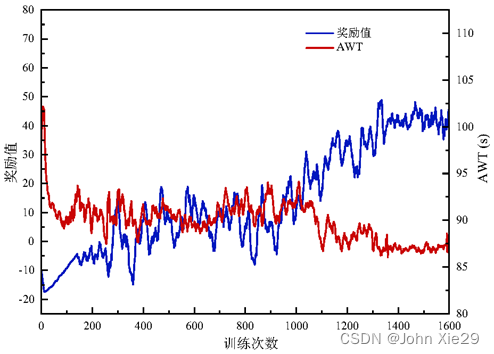
同样,在车位分配问题上,针对复杂的大型停车场,单步奖励的设计更需要精心设计。如,有研究曾在一个拓扑结构简单的小型停车场中进行了实验,在DQN框架下设置一个引导车辆尽可能短距离移动的单步奖励函数,使模型得到收敛。但在该文的场景中(419个车位,且结构更复杂),采用该方法后,模型的训练过程如图3:可以看到,模型根本无法收敛。
原因可以理解为:
单步奖励一直“告诉”系统:给车辆分配车位时,一定要给车辆分配一个行驶距离更短的车位。但这种策略,会导致系统的效率无法得到优化,因此一轮训练结束后,无法得到正向的全局奖励。相当于,全局奖励又跳出来否认了之前根据单步奖励学习到的策略。因此,系统陷入混乱,导致模型无法得到收敛。
因此,该文考虑了引入领域知识启发智能体的学习
思考一个问题:若要优化AVP性能,车位分配动作需要遵循什么规则?假设设计好了一个能够优化系统性能的分配机制,基于该机制(表示为一个显式的函数 T a r g e t S e t t i = F ( t i ) TargetSet_{t_i}=F(t_i) TargetSetti=F(ti)),车辆 V i V_i Vi申请停车后,系统会根据该函数计算出其理想停放区域 T a r g e t S e t t i TargetSet_{t_i} TargetSetti。因此,单步奖励即可根据该机制进行设计,如果动作 a t i a_{t_i} ati在该区域内,则不给予惩罚,否则给予惩罚。
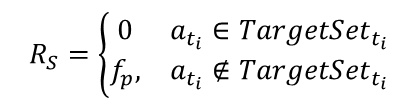
问题的关键在于如何构建函数 T a r g e t S e t t i = F ( t i ) TargetSet_{t_i}=F(t_i) TargetSetti=F(ti)。
先从一个简单的场景展开,如图4,红色区域的停车位距离出入口较近,在该区域停车的车辆能够更方便地完成停车、离开等行为,在行驶过程中与其他车辆产生冲突的风险更小。因此,将该部分区域的停车位定义为高质量停车位。相反地,距离出入口较远的车位定义为普通停车位,即:根据停车位与出入口的距离来定义停车位的质量。
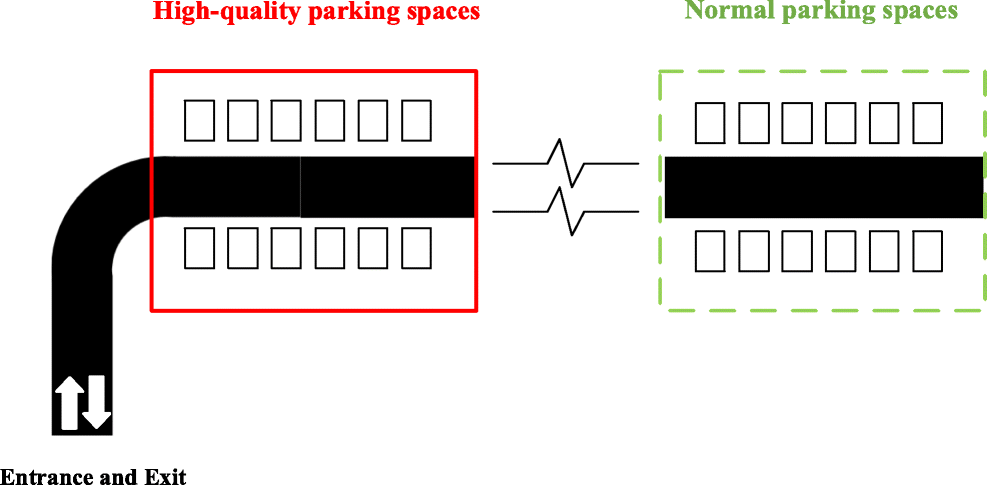
对于整个系统而言,高质量停车位被使用对于系统效率的影响是会更小的,即高质量停车位的使用成本是更低的,因此,可以通过车位与出入口的综合距离对车位使用成本进行定义:
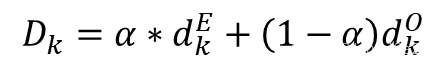
其中, d k E d^E_k dkE、 d k O d^O_k dkO分别为车位 与入口、出口之间的距离; 为权重系数。上式表示车位的综合距离越小,其使用成本越小。当系统完成了所有的停车任务后,总的使用成本为:

N k N_k Nk代表整个过程中车位 k k k被使用的次数。因此,全局目标可以转换为总的使用成本最小,即 m i n T C min TC minTC。假设总的停车任务数 不变,要实现 的目标,应该尽可能增加 较小的车位的使用次数,增加高质量停车位的服务量。如:可以让停车时长短的车辆尽量停在高质量停车区域,从而让其服务更多地车辆。在车辆到达时,如果有空闲车位是必须对车辆进行服务的,因此,车位分配机制需要基于车辆的停车时长来建立,满足以下两个基本原则:
-
停车时长较长的车辆优先停放在 D k D_k Dk较大的车位;
-
停车时长较短的车辆优先停放在 D k D_k Dk较小的车位。
根据该原则,假设车辆 V i V_i Vi在 t i t_i ti时刻申请停车,输入了其预计停车时长 T i i n T_i^{in} Tiin:
(1)首先对 T i i n T_i^{in} Tiin的长短水平进行评估:如 T i i n T_i^{in} Tiin在历史数据中排名为50%的水平;
(2)按车位的使用成本将动作空间内的动作进行排序。
这样,我们将动作空间内排名最接近50%的水平的那部分车位即作为 T a r g e t S e t t i TargetSet_{t_i} TargetSetti。由此,即可完成一个能够在大型复杂停车场中应用的奖励函数。
具体的公式推导不再列出,有兴趣可阅读原文。
2.3 动作嵌入
大型停车场往往会产生较大规模的离散动作空间,从而导致模型求解过慢(具体原因及解决思路可参考DeepMind团队提出的Wolpertinger Policy框架)。Wolpertinger Policy框架虽然提出了通过将离散的动作嵌入到连续空间中来应对大规模的离散动作,但该框架并没有提到如何进行行动嵌入,这需要研究者根据研究的具体场景进行设计。因此,本节提出了一种基于车位使用成本的动作嵌入方法。
在上文中,我们给出了车位成本的计算方式,且离散动作空间
A
=
1
,
2
,
.
.
.
,
k
,
.
.
.
,
n
A={1,2,...,k,...,n}
A=1,2,...,k,...,n是一个基于
D
k
D_k
Dk的有序集合。在A中,相邻整数所表示的车位分配动作,对于全局效率的影响是相似的。这为实现良好的动作嵌入效果打下了基础,理想的嵌入效果即是效果相似的动作在连续空间中的距离是相近的。因此,本节以车位成本
D
k
D_k
Dk作为先验信息,将
A
A
A映射到一个连续的数值区间[-1,1],从而实现动作嵌入。下式定义了如何将离散动作
a
t
a_t
at转化为连续动作
a
^
t
\hat a_t
a^t:
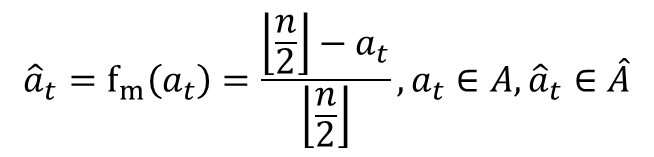
3 仿真环境
该文章的强化学习环境是基于SUMO搭建的,速度应该比不上数值仿真,但胜在车辆运动模型更加精细和完善,更加能接近真实情况,且可视化界面也有助于观察和强化学习方法的可解释。SUMO的停车场基本构建方法可参考该博客。该博客中的SUMO知识都是比较基础的,由于该文章的仿真环境代码写得比较混乱,暂时还未开源,后面有空整理得更加规范整洁后,会进行开源并出一篇博客进行介绍。
4 结果
最终,在如上的奖励函数和动作嵌入的协助下,模型训练能够较快的得到收敛,且相对其他方法有较好的提升。
除此之外,文章还从多个维度进行了实验的分析,比较全面的评价该方法的性能。
5 讨论
强化学习在交叉学科中的应用确实比较好水文章,但真要落地应用确实比较困难,最主要的缺点在于太不稳定。如该文章中的很多系数,都是经过多次的实验,反复测试后才有了一个较好的结果。如果换一个停车场,甚至车流需求特征变化之后,系数估计都是需要全部进行重新测试。所以,就拿AVP这个场景来说,探究如何根据停车场的结构,车流的需求特征快速确定一些超参数、系数,才是更加主要的一个研究。
另外,该文章采用了广东某大型商业停车场的真实数据进行仿真,时间段为晚高峰期,处于供不应求的状态,得出的分配策略也只适应这个场景。但当非高峰期的数据也加入后,能否学习到一个好的策略也是需要打一个问号。亦或者各种场景的分配策略进行分开训练,在车流需求特征达到某种条件后进行切换也可以。














 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









