









引子
论文来自spinning up Key Papers in Deep RL的safety专题,也就是深度强化学习的安全方面。论文主要是讨论AI Safety这个话题的。这里的Safety倒不是科幻电影里的那种大危机,读过下面的第一篇文章就会明白,这里的safety更像是让agent在具有极度“风险厌恶”情况下进行决策。
本文只做简单概述,并且文章顺序进行了一些调整,感兴趣请阅读原论文。
强化学习也被称作“试错学习”,但是现实中很多应用一旦出错就会产生很大的成本,比如清洁机器人将花瓶打碎,或者将湿拖把塞进墙上的插座。在深度强化学习(DRL)的背景下,神经网络这个黑盒子导致agent在试错过程中的行为更加“不可预测”,如何尽量保证在“试错”的时候尽可能不犯错或者少犯错就成了亟需解决的问题。
AI safety in RL
Concrete Problems in AI Safety, 2016
这篇文章率先建立了安全问题的分类,作为未来研究的重要起点。内容没有很多干货,主要是以清洁机器人为例,将DRL中可能的问题分为五类:
- 避免负面作用:清洁时不打翻花瓶
- 避免伪装奖励函数:比如人为干扰清洁机器人的视觉让它误以为收拾干净了
- 可拓展的监督:丢弃糖纸,但必须回收手机
- 避免糟糕的探索:避免探索时把湿拖把放进插座
- 对分布转移的鲁棒性:清洁不同的环境
对于每一类问题,都讨论了一些具体实验的方法。文章洋洋洒洒写了快30页,但都是“纸上谈兵”,给出的都是“指导性意见”,感兴趣的同学可以深入看看。
高维约束策略优化(CPO)
Constrained Policy Optimization, ICML2017, CPO
文章受TRPO启发,研究agent必须满足一些条件下的模型优化方法(线性规划很难拓展到高维)。关键在于,训练过程的探索也必须满足约束。
文章在理论上提出了保障,在“试错”的同时保证了不越界(感兴趣可以去看原文推导,这是我认为它能上顶会的原因)。文章结尾提出,希望通过这种方式,将强化学习迁移到现实中来。
当然,因为它理论上有严格保证,它也是唯一一篇“100%不会出现危险探索”的论文。
具体操作如动图所示:
一开始位置就是五角星的位置,选择一个梯度方向,求出交叉熵受限情况下的可选region,然后结合约束条件(黄色区域),根据交叉熵小幅修改梯度的方向,然后更新梯度,到了新的五角星的位置。

DDPG+SafeLayer
Safe Exploration in Continuous Action Spaces, 2018.
标题直译是《连续动作空间下的安全探索》,连续动作空间就是DDPG,安全探索就是SafeLayer。用SafeLayer修正DDPG决定的动作。
整体框架如图所示:
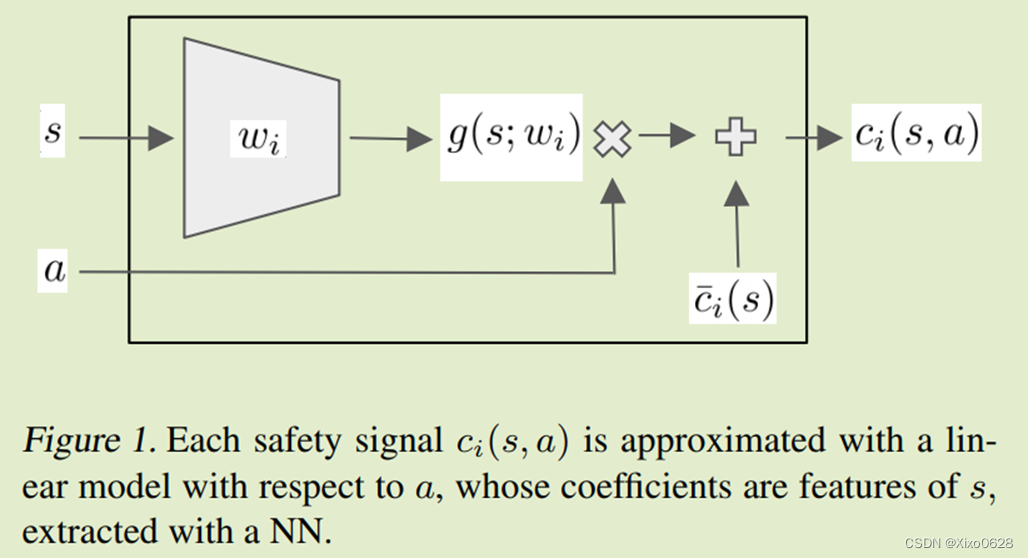
显然,这里的SafeLayer起到一个“限压阀”的作用,地位至关重要。然而它在训练的时候,近似认为预测成本是线性的。再加上它本身是用神经网络那一套训练出来的,偶尔出现一些意外也被认为是允许的。
人为干预
Trial without Error: Towards Safe Reinforcement Learning via Human Intervention,2017
接下两三篇都是这方面的。需要专家交互式地给出一些“建议”。
框架如图所示:
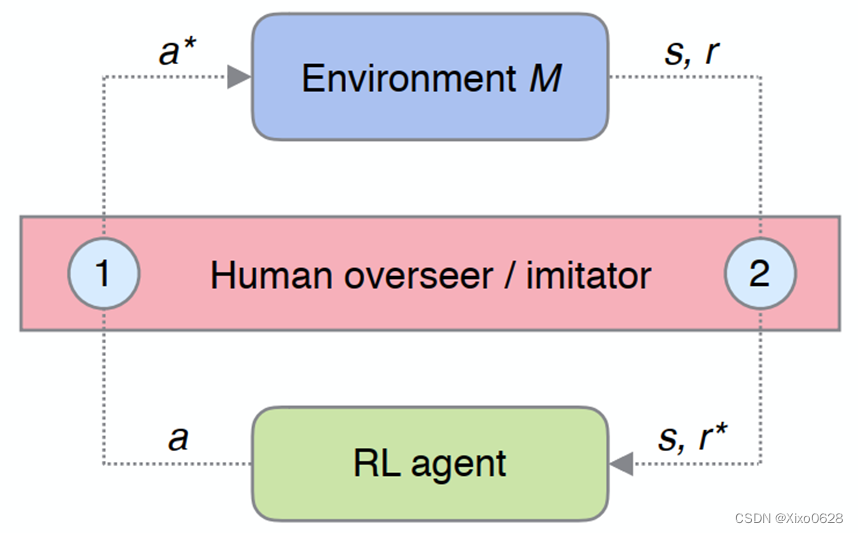
当模型选择非法动作的时候,需要人为进行干预。干预主要分为两部分,修改动作和修改奖励函数。
这种方法有两个问题:
- 需要大量标记,也就是需要大量的人力
- 环境必须运行得足够慢,留给专家一定的响应时间
降低专家信息的质量来节约成本
Deep Reinforcement Learning from Human Preferences, 2017
说实话,这篇文章更像是模仿学习/逆强化学习那一套。
不同质量的信息,要求的人力成本是不一样的:
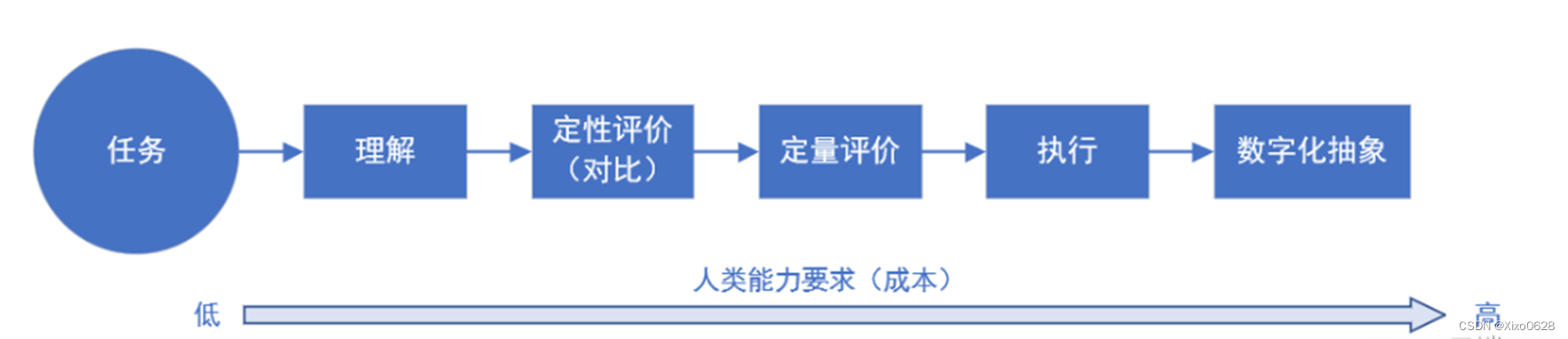 文章认为,如果可以让非专家(普通用户)参与到信息的提供中来,就可以更好地节约人力成本。因此希望通过降低数据质量——只需要对比两条轨迹的优劣——来获取人类的偏好。这个想法很自然,比如我自己写不出很好的论文,但我照样可以评估一篇论文的好坏。如果是从两篇论文中挑出更差的那一篇,就更容易了(人都是擅长比较的)。
文章认为,如果可以让非专家(普通用户)参与到信息的提供中来,就可以更好地节约人力成本。因此希望通过降低数据质量——只需要对比两条轨迹的优劣——来获取人类的偏好。这个想法很自然,比如我自己写不出很好的论文,但我照样可以评估一篇论文的好坏。如果是从两篇论文中挑出更差的那一篇,就更容易了(人都是擅长比较的)。
根据这些“比较”数据,通过最小化预测人类偏好的交叉熵损失来进行训练。
这种方式也有明显的问题,就是所有比较结果一视同仁、比较结果不一定准确之类的。
自动重置+及时早停
Leave no Trace: Learning to Reset for Safe and Autonomous Reinforcement Learning, 2017
文章需要人手工重置一些不好的状态,然后训练的时候尽量避免这些状态的出现。
自动重置减少专家负担,早停保证状态“可以回收”。
比如下图是狗在悬崖上行走,视频链接在论文中给出了。

左边是专家标记的“失败”,重置后为了避免失败,agent会尽量去学在悬崖边上停下或者后退。
这种方法的缺点也主要有这两点:
- 对于所有专家提供的“重置”信息一视同仁,这是不应该的
- 无法避免危险,直到遇到、被标记
总结
就是因为DRL无法在Safety上提供确实的保障,才导致游戏、仿真等领域是DRL的主要战场。DRL Safety还是一个非常重要、非常有意义的领域,但或许应用领域很难爆发式扩大(Safety领域从来都是这样)。或许有朝一日,神经网络这个黑盒子被打开,这部分的理论被完善,这个领域才会迎来一波真正的高潮。


















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











