







1. 参数化(parametric) vs. 非参数化方法
-
参数化方法
-
提前假定某种拟合的函数形式
-
优点:简单,易于解释和评估
-
缺点:high bias, 因为真实的数据分布可能根本就不符合我们之前假定的函数形式!
-
非参数化方法
-
分布的估计是数据驱动的 (Distribution or density estimate is data-driven)
-
Relatively few assumptions are made a priori about the functional form.
-
非参数化的训练过程非常简单(可以说没有训练过程),就是把所有的训练样例存储起来。之后我们需要一个相似度函数 f f f,在测试过程中,计算测试样例和训练样例的相似度即可。
2. 1-近邻 (1-NN)
【定义1】Voronoi tessellation (Dirichlet tessellation)
当看到空间中的一系列给定的点,例如x, y1, y2, y3,…,我们希望为每个点,例如点x,划定一个包围这个点的区域(Voronoi Cell)。对于任意一个位于区域内的点,我们总希望它距离点x的距离小于离其他所有的给定的点,例如 y1, y2, y3,… 的距离。
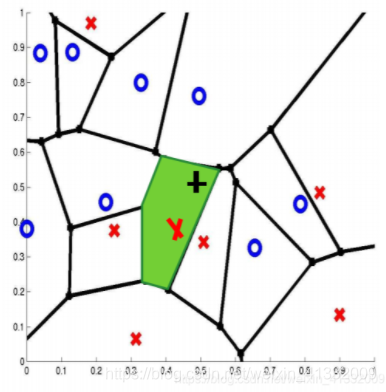
这里提到Voronoi tessellation的意义在于说明,对欧氏空间的任何一个点x,都能够找到到它距离最近的那个点(有可能有多个)。
3. KNN
1-NN的显著缺点就是,如果测试样本的最近邻(1-NN)是个噪声怎么办?于是想到了类似集成学习的思想,我们可以关注测试样本的多个邻居。如果是分类问题,让这些邻居投票来决定测试样本的类别;如果是回归问题,就对每个邻居投票的结果做加权平均。
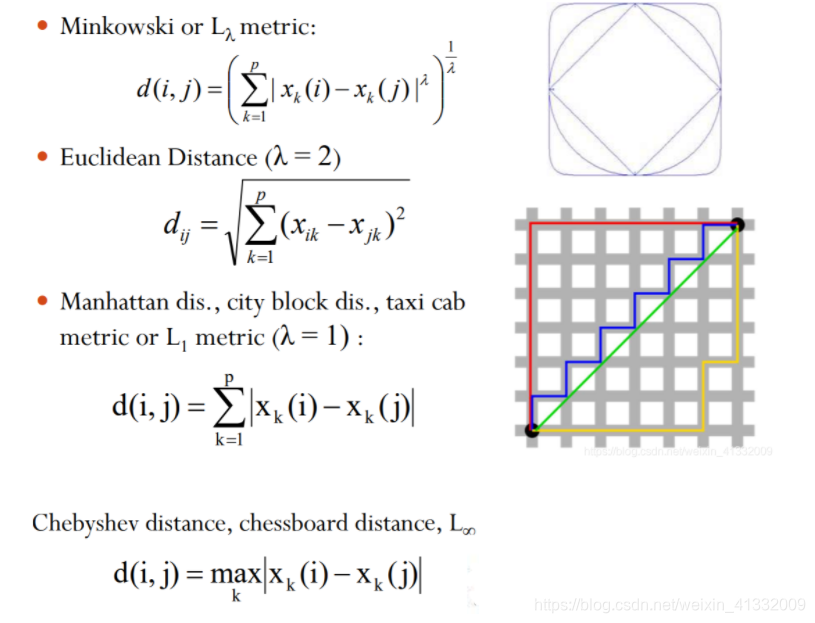
3.1 距离度量
介绍四种距离度量方法:
3.2 属性归一化
KNN中,将不同的属性归一化是非常重要的。因为KNN的距离函数是Minkowski距离,这个距离度量受量纲影响很大。如果某些属性的值过大可能会dominate距离函数。
比如,在判断借贷风险这个问题上,我们关注用户的年龄和年收入。年龄范围[20,70], 年收入范围[100000,600000]. 这样,显然距离函数都是由年收入决定的。
所以,要把不同属性都归一化到[0,1]区间。
3.3 属性加权
可以根据不同属性的重要性给不同属性不同的权重:
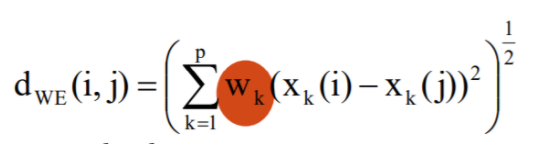
例如,通过计算不同属性的互信息来得到这个权重。
3.4 K值的选择
-
如果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9080
9080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









