







视觉问答(Visual Question Answering,VQA)模型是一种结合了计算机视觉和自然语言处理技术的人工智能任务,旨在通过理解图像内容并回答与之相关的自然语言问题。VQA模型需要同时处理图像和文本信息,生成准确的自然语言答案。
VQA模型通常包括三个主要阶段:图像和问题特征提取、特征融合以及答案生成。在图像特征提取阶段,卷积神经网络(CNN)及其变体如VGGNet和ResNet被广泛使用;在问题特征提取阶段,词嵌入技术如LSTM、GRU和BERT等被用于捕捉问题的语义信息;在答案生成阶段,模型可能采用分类或生成式方法来生成回答。
VQA模型的研究领域非常广泛,涉及多种方法和技术。例如,基于联合嵌入的方法通过CNN和RNN对图像和问题进行联合编码,注意力机制则允许模型动态调整对输入项各部分的关注度,以提升模型的“专注力”。此外,还有知识融合模型,这些模型能够处理开放域问题,需要考虑图像和问题之外的知识。
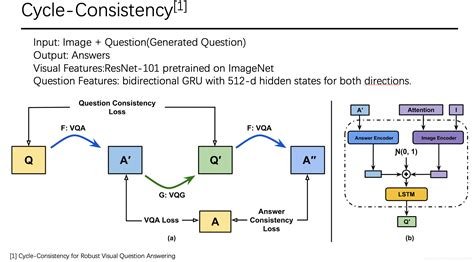
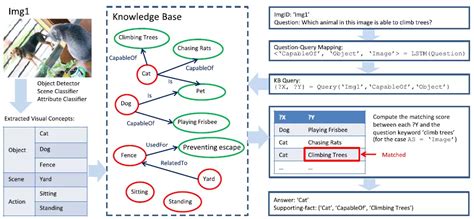
尽管VQA模型在某些方面取得了显著进展,但仍然面临许多挑战。例如,模型往往过于依赖语言先验,忽视了图像的重要性,导致在复杂问题上的表现不佳。此外,VQA模型在评估预测答案与正确答案之间的相似度时仍存在困难,特别是在需要深度推理或涉及外部知识的情况下。
未来的研究方向包括进一步优化模型性能、扩展数据集、增强模型的泛化能力以及引入更多的外部知识库来提高模型的理解和推理能力。总体而言,VQA模型作为连接视觉和语言的重要桥梁,具有广泛的应用前景,如智能助手、智能家居和自动驾驶等领域。
视觉问答(VQA)模型中最新的特征融合技术是什么?
在视觉问答(VQA)模型中,最新的特征融合技术包括多种方法,每种方法都有其独特的优点和应用场景。以下是几种较为先进的特征融合技术:
-
多模态紧凑双线性池化(MCB) :这种方法通过双线性池化实现文本和图像的交互,降低了参数量,从而提高了模型的效率和准确性。
-
多模态低秩双线性池化(MLB) :MLB模型利用 Hadamard 积降低计算复杂性,实现了跨模态数据的深度融合。这种方法在保持计算效率的同时,能够更好地捕捉不同模态之间的关联。
-
多模态Tucker融合(MUTAN) :MUTAN结合了双线性模型和多级注意力网络,有效地融合了问题意义和图像中视
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2282
2282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











