 MulT模型:多模态处理的创新方案
MulT模型:多模态处理的创新方案








MulT模型(Multimodal Transformer)是一种用于处理未对齐多模态语言序列的Transformer模型。该模型由卡内基梅隆大学的Yao-Hung Hubert Tsai和Shaojie Bai等人于2019年提出,并在ACL 2019会议上发表。
MulT模型的核心是跨模态注意力机制(Crossmodal Attention),它通过成对的跨模态Transformer模块实现不同模态之间的交互和融合。具体来说,MulT模型将输入的多模态数据分别作为查询、键和值进行处理,通过权重矩阵转换向量空间并转化特征维度,使查询和键的维度保持一致。这种机制允许模型在不同时间步中关注多模态序列之间的交互关系,并隐式地适应数据的对齐方式。
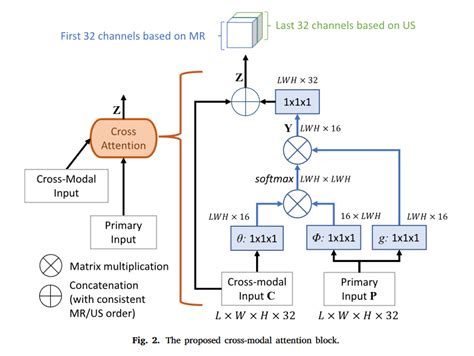
MulT模型的架构包括时间卷积层、位置嵌入层、跨模态注意块和自注意力层。跨模态注意块由多个跨模态注意块堆叠而成,每个块直接关注低级特征,同时去除自我注意,以适应不同模态间的差异。 MulT模型通过端到端的学习方式,无需显式对齐数据,直接从未对齐的多模态流中学习表示。
实验结果表明,MulT模型在处理未对齐的多模态数据时表现优异,特别是在多模态情感识别任务上,其性能显著优于最先进的方法。此外,MulT模型还验证了跨模态注意力机制的有效性,能够有效捕获跨不同模态的相关信号。
MulT模型通过创新的跨模态注意力机制和时域处理技术,提供了一种高效、灵活的多模态语言序列建模解决方案,有望推动多模态自然语言处理领域的进一步发展。
MulT模型与其他多模态Transformer模型(如MMS或MMT)的性能比较如何?
MulT模型与其他多模态Transformer模型(如MMS或MMT)的性能比较可以从多个方面进行分析。
在情感分析任务中,MulT模型在CMU-MOSI和CMU-MOSEI数据集上的表现较为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7856
7856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











