







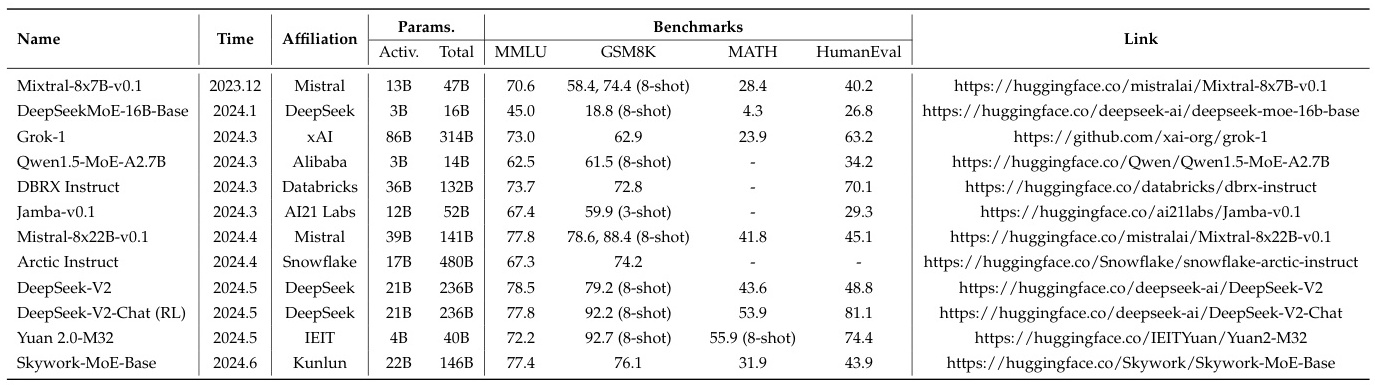
DeepSeek Coder 在 MMLU(Massive Multitask Language Understanding)基准测试中的表现与多个模型接近或相当。以下是具体分析:
-
DeepSeek Coder-V2:
- 在 MMLU 基准测试中,DeepSeek Coder-V2 的表现达到了 79.2% 的准确率。
- 根据对比数据,DeepSeek Coder-V2 的 MMLU 表现接近于 Llama-3 70B(78.9%)。
-
DeepSeek Coder-V3:
- DeepSeek Coder-V3 在 MMLU 基准测试中的表现进一步提升,达到了 88.5% 的准确率。
- 这一成绩使其在 MMLU 上的表现超越了包括 GPT-4o 和 Claude-Sonnet 3.5 在内的顶级闭源模型。
-
其他相关模型:
-
LLaMA 3-40B:在 MMLU 上的表现为84.5%,略低于 DeepSeek Coder-V3 的表现。
-
GPT-4o和Claude-Sonnet 3.5:这两个模型在 MMLU 上的表现分别为85.0%和87.1%,接近 DeepSeek Coder-V3 的水平。
-
-
总结:
- DeepSeek Coder 系列模型在 MMLU 基准测试中的表现非常出色,尤其是 DeepSeek Coder-V3,其表现接近甚至超越了 GPT-4o 和 Claude-Sonnet 3.5 等顶级闭源模型。
- 具体来说,DeepSeek Coder-V2 的表现与 Llama-3 70B 接近,而 DeepSeek Coder-V3 则超越了这些模型,达到了更高的准确率。
综上,DeepSeek Coder 在 MMLU 基准测试中的表现与 Llama-3 70B、GPT-4o 和 Claude-Sonnet 3.5 等模型最为接近,尤其是在最新版本 DeepSeek Coder-V3 中,其表现已经超越了这些顶级闭源模型。
DeepSeek Coder-V3 在多个基准测试中表现出色&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











