







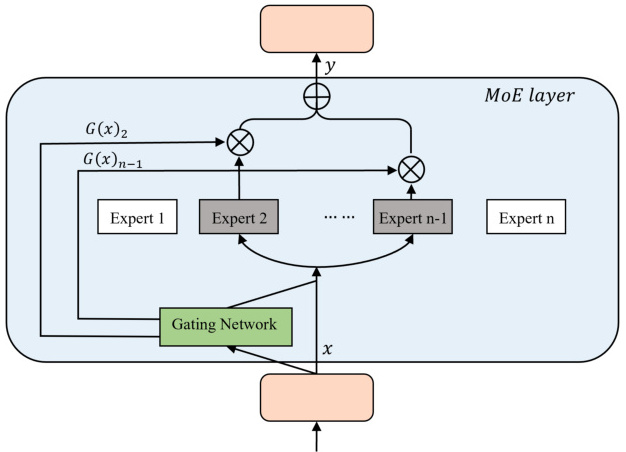
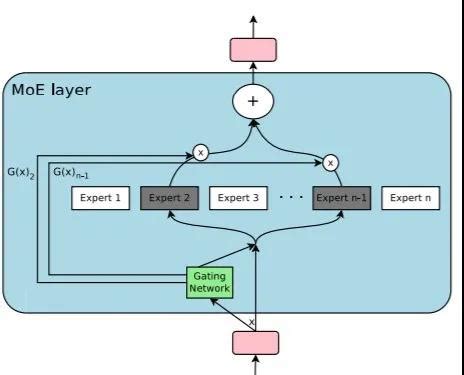
MoE(Mixture of Experts,混合专家)架构中的门控机制是动态选择专家的核心组件,其主要功能是根据输入数据的特征或任务需求,智能地决定哪些专家模块参与计算,从而提高模型的效率和性能。以下是MoE架构中门控机制实现动态选择专家的具体方式:
1. 门控机制的基本原理
门控机制通过分析输入数据的特征,动态地将输入分配给最适合的专家模块进行处理。这种机制可以分为稀疏式、密集式和Soft式三种类型:
- 稀疏式门控:只激活部分专家模块,未激活的专家不参与计算,从而减少计算量。
- 密集式门控:所有专家模块均被激活,但通过加权的方式决定每个专家的贡献。
- Soft式门控:结合输入token和专家输出,通过加权方式融合计算需求。
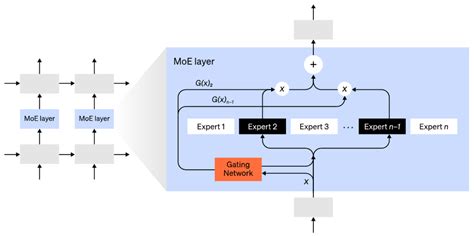
2. 门控机制的实现方式
门控机制通常由神经网络组成,其输出是一个概率分布或权重向量,指示输入数据应由哪些专家处理。具体实现方式如下:
-
输入特征分析:门控网络接收输入数据,并分析其特征,例如语义、结构或模式等。
-
计算专家权重:门控网络通过线性变换和激活函数(如softmax)计算每个专家的权重,表示该专家对当前输入的适用程度。

-
动态路由决策:根据计算出的权重,门控网络决定哪些专家模块被激活,哪些被忽略。例如,对于稀疏门控机制,只有权重高于阈值的专家才会被激活。
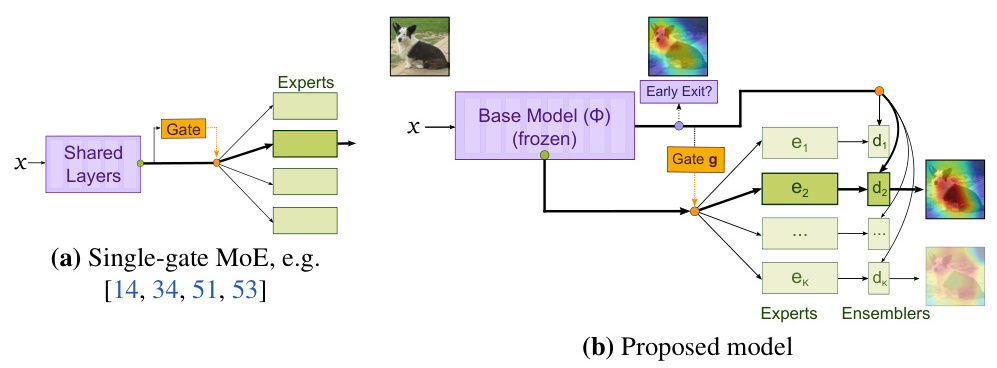
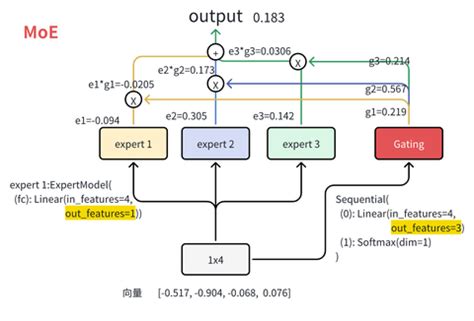
3. 动态选择专家的过程
在MoE架构中,动态选择专家的过程可以概括为以下步骤:
-
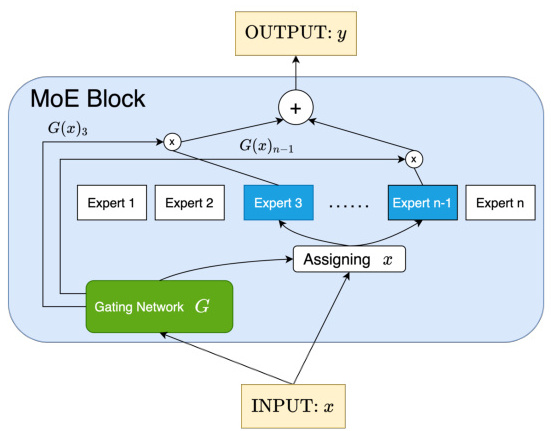
输入数据传递:输入数据首先传递到门控网络,门控网络分析输入特征并计算每个专家的权重。
-
专家激活:根据权重分布,门控网络选择最合适的专家模块进行处理。例如,在Switch Transformer中,门控网络会根据评分矩阵为每个输入分配一个专家。
-
输出聚合:各专家模块处理完输入数据后,其输出会被加权求和,最终生成模型的预测结果。
4. 优化与负载均衡
为了进一步提升效率和性能,MoE架构通常会结合负载均衡策略:
- 负载均衡:确保所有专家模块都能得到均衡训练和使用,避免某些专家过载或资源浪费。
- 动态调整:根据任务需求和输入数据的变化,动态调整专家的数量和类型。
5. 应用场景
MoE架构中的门控机制广泛应用于多个领域,包括自然语言处理、计算机视觉、推荐系统等。例如:
- 在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











