







Introduction
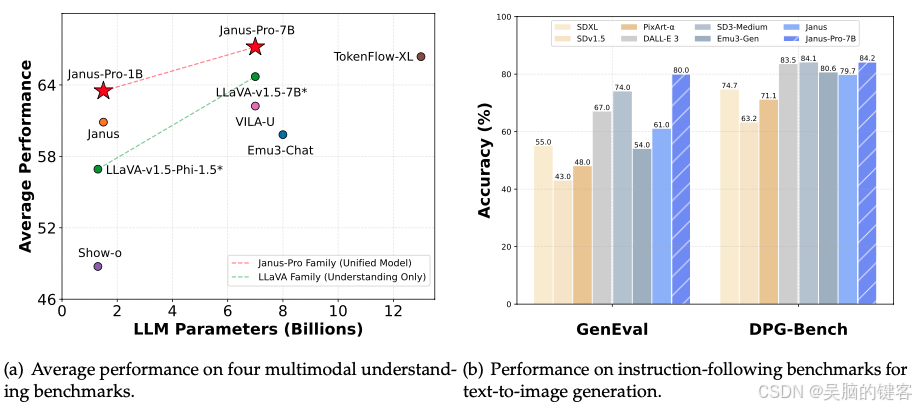
DeepSeek的Janus-Pro是一个突破性的自回归框架,它将多模态理解和生成统一起来,解决了以往方法的局限性。Janus-Pro 将视觉编码解耦为独立的路径,同时保持单一、统一的转换器架构,从而缓解了视觉编码器在理解和生成中的角色冲突,增强了框架的灵活性。这一创新设计超越了以往的统一模型,并达到或超过了特定任务模型的性能,使其成为下一代统一多模态模型的有力候选者。
我也发布过相关博客,可供的大家学习参考:

模型概要
Janus-Pro 是一种统一的理解和生成 MLLM,它将视觉编码与多模态理解和生成分离开来。Janus-Pro 基于 DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base 构建。
在多模态理解方面,它使用 SigLIP-L 作为视觉编码器,支持 384 x 384 图像输入。在生成图像时,Janus-Pro 使用这里的标记化器,降采样率为 16。
快速上手
GitHub仓库提供了安装说明和一个简单的推理示例,可用于多模态理解和文本到图像的生成。该模型可在 Hugging Face 上获取,用户可参考该资源库获取安装说明。
!git clone https://github.com/deepseek-ai/Janus.git
!cd Janus && pip install -e .
!pip install flash-attn --no-build-isolation
简单推理示例
多模态理解
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images
# specify the path to the model
model_path = "deepseek-ai/Janus-Pro-7B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
conversation = [
{
"role": "<|User|>",
"content": f"<image_placeholder>\n{question}",
"images": [image],
},
{"role": "<|Assistant|>", "content": ""},
]
# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)
# # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
# # run the model to get the response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
文本到图像的生成
import os
import PIL.Image
import torch
import numpy as np
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
# specify the path to the model
model_path = "deepseek-ai/Janus-Pro-7B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
conversation = [
{
"role": "<|User|>",
"content": "A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair",
},
{"role": "<|Assistant|>", "content": ""},
]
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_start_tag
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1,
parallel_size: int = 16,
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
probs = torch.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
os.makedirs('generated_samples', exist_ok=True)
for i in range(parallel_size):
save_path = os.path.join('generated_samples', "img_{}.jpg".format(i))
PIL.Image.fromarray(visual_img[i]).save(save_path)
generate(
vl_gpt,
vl_chat_processor,
prompt,
)
Gradio 演示
我们已经在 Huggingface 中部署了在线演示。 对于本地 gradio 演示,您可以使用以下命令运行:
pip install -e .[gradio]
python demo/app_januspro.py
License
代码库采用 MIT 许可,而 Janus-Pro 模型的使用则受 DeepSeek 模型许可的约束。
Citation
@article{chen2025janus,
title={Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling},
author={Chen, Xiaokang and Wu, Zhiyu and Liu, Xingchao and Pan, Zizheng and Liu, Wen and Xie, Zhenda and Yu, Xingkai and Ruan, Chong},
journal={arXiv preprint arXiv:2501.17811},
year={2025}
}
联系
如有任何问题或咨询,请提出问题或通过以下方式联系 DeepSeek:service@deepseek.com。
结论
DeepSeek 的 Janus-Pro 是多模态理解和生成领域的一大进步。通过解耦视觉编码和利用统一的变压器架构,它比以前的模型具有更高的灵活性和性能。凭借其开源性和全面的文档,Janus-Pro 将成为多模态任务的领先解决方案,使开发人员和研究人员能够创建创新应用,推动人工智能技术的发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









