







Dolphin (Document Image Parsing via Heterogeneous Anchor Prompting)是一种遵循“先分析后解析”范式的新型多模态文档图像解析模型。本仓库包含Dolphin的演示代码与预训练模型。
📑 概述
文档图像解析因其包含文本段落、图表、公式和表格等复杂交织的元素而具有挑战性。Dolphin通过两阶段方法应对这些挑战:
- 🔍 第一阶段:通过生成自然阅读顺序的元素序列,实现全面的页面级布局分析
- 🧩 第二阶段:利用异构锚点和任务特定提示,高效并行解析文档元素
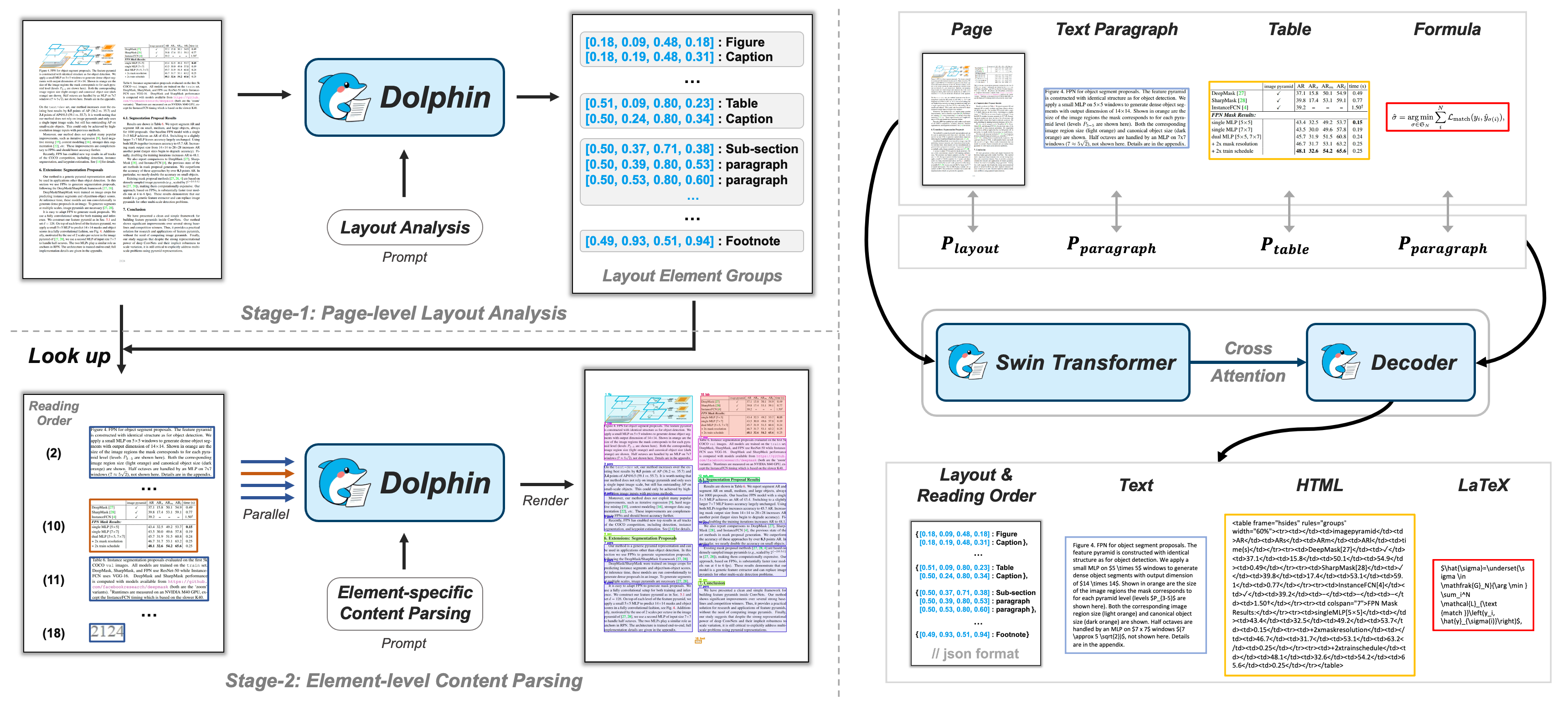
海豚系统在各类页面级和元素级解析任务中均展现出优异性能,同时通过轻量级架构和并行解析机制确保了卓越的运行效率。
模型架构
海豚系统采用基于Transformer的视觉-编码器-解码器架构:
- 视觉编码器:基于Swin Transformer,用于从文档图像中提取视觉特征
- 文本解码器:基于MBart,用于从视觉特征解码文本
- 基于提示的交互界面:通过自然语言提示控制解析任务
该模型以Hugging Face的VisionEncoderDecoderModel形式实现,便于与Transformers生态系统集成。
🛠️ 安装
- 克隆repo
git clone https://github.com/ByteDance/Dolphin.git
cd Dolphin
- 安装依赖项:
pip install -r requirements.txt
- 通过以下任一选项下载预训练模型:
选项A:原始模型格式(基于配置)
从百度云或Google Drive下载,并将它们放入./checkpoints文件夹。
选项B:Hugging Face模型格式
访问我们的Huggingface模型页面,或通过以下命令下载模型:
# 从Hugging Face Hub下载模型
git lfs install
git clone https://huggingface.co/ByteDance/Dolphin ./hf_model
# 或使用Hugging Face CLI
huggingface-cli download ByteDance/Dolphin --local-dir ./hf_model
⚡ 推理
Dolphin提供两种推理框架,支持两种解析粒度:
- 页面级解析:将整个文档图像解析为结构化的JSON和Markdown格式
- 元素级解析:解析单个文档元素(文本、表格、公式)
📄 页面级解析
使用原始框架(基于配置)
# Process a single document image
python demo_page.py --config ./config/Dolphin.yaml --input_path ./demo/page_imgs/page_1.jpeg --save_dir ./results
# Process all document images in a directory
python demo_page.py --config ./config/Dolphin.yaml --input_path ./demo/page_imgs --save_dir ./results
# Process with custom batch size for parallel element decoding
python demo_page.py --config ./config/Dolphin.yaml --input_path ./demo/page_imgs --save_dir ./results --max_batch_size 8
Hugging Face Framework
# Process a single document image
python demo_page_hf.py --model_path ./hf_model --input_path ./demo/page_imgs/page_1.jpeg --save_dir ./results
# Process all document images in a directory
python demo_page_hf.py --model_path ./hf_model --input_path ./demo/page_imgs --save_dir ./results
# Process with custom batch size for parallel element decoding
python demo_page_hf.py --model_path ./hf_model --input_path ./demo/page_imgs --save_dir ./results --max_batch_size 16
🧩 元素级解析
使用原始框架(基于配置)
# Process a single table image
python demo_element.py --config ./config/Dolphin.yaml --input_path ./demo/element_imgs/table_1.jpeg --element_type table
# Process a single formula image
python demo_element.py --config ./config/Dolphin.yaml --input_path ./demo/element_imgs/line_formula.jpeg --element_type formula
# Process a single text paragraph image
python demo_element.py --config ./config/Dolphin.yaml --input_path ./demo/element_imgs/para_1.jpg --element_type text
Hugging Face Framework
# Process a single table image
python demo_element_hf.py --model_path ./hf_model --input_path ./demo/element_imgs/table_1.jpeg --element_type table
# Process a single formula image
python demo_element_hf.py --model_path ./hf_model --input_path ./demo/element_imgs/line_formula.jpeg --element_type formula
# Process a single text paragraph image
python demo_element_hf.py --model_path ./hf_model --input_path ./demo/element_imgs/para_1.jpg --element_type text
🌟 主要特点
- 🔄 基于单一视觉语言模型的两阶段分析-解析方法
- 📊 在文档解析任务上表现优异
- 🔍 自然阅读顺序的元素序列生成
- 🧩 针对不同文档元素的异构锚点提示
- ⏱️ 高效的并行解析机制
- 🤗 支持Hugging Face Transformers以便更轻松集成
💖 致谢
我们要感谢以下开源项目为本工作提供的灵感和参考:


















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









