







在人工智能驱动的图像生成与理解领域,尽管取得了快速进展,但仍存在显著挑战,阻碍了一个无缝、统一的方法的发展。
目前,专注于图像理解的模型往往在生成高质量图像方面表现不佳,反之亦然。这种任务分开的架构不仅增加了复杂性,还限制了效率,使得处理同时需要理解与生成的任务变得繁琐。此外,许多现有模型在有效执行任何功能时,都过于依赖于架构修改或预训练组件,这导致了性能权衡与整合挑战。
为了解决这些问题,DeepSeek AI 推出了 JanusFlow,这是一个强大的 AI 框架,旨在统一图像理解与生成。JanusFlow 通过将图像理解和生成集成到一个统一的架构中,来解决前面提到的低效问题。这一新颖的框架采用简约设计,结合了自回归语言模型与纠正流(rectified flow)—— 一种最先进的生成建模方法。
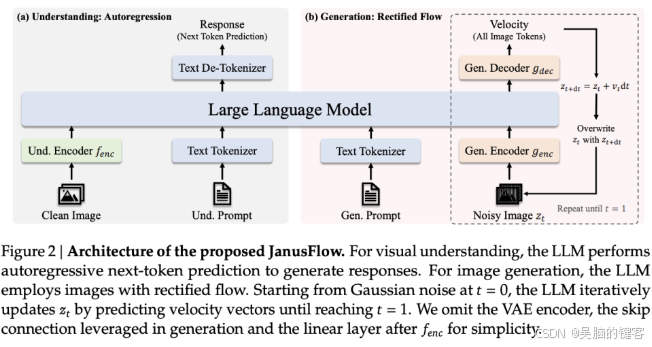
通过消除对独立的 LLM 和生成组件的需求,JanusFlow 实现了更为紧密的功能集成,同时降低了架构复杂性。它引入了双重编码器 - 解码器结构,解耦了理解和生成任务,并通过对齐表示来确保统一训练方案中的性能一致性。
技术细节方面,JanusFlow 轻量高效地整合了纠正流与大型语言模型。该架构包括用于理解和生成任务的独立视觉编码器。在训练过程中,这些编码器相互对齐,以提高语义一致性,使系统在图像生成和视觉理解任务中表现出色。
这种编码器的解耦防止了任务之间的干扰,从而增强了每个模块的能力。模型还采用了无分类器引导(CFG)来控制生成图像与文本条件之间的对齐,从而提高图像质量。与传统的使用扩散模型作为外部工具的统一系统相比,JanusFlow 提供了更简单、更直接的生成过程,局限性也更少。该架构的有效性体现在其能够在多个基准测试中匹敌甚至超过许多特定任务模型的表现。
JanusFlow 的重要性在于其效率和多功能性,填补了多模态模型开发中的一个关键空白。通过消除对独立生成和理解模块的需求,JanusFlow 使研究人员和开发者能够利用单一框架处理多种任务,显著降低了复杂性和资源使用。
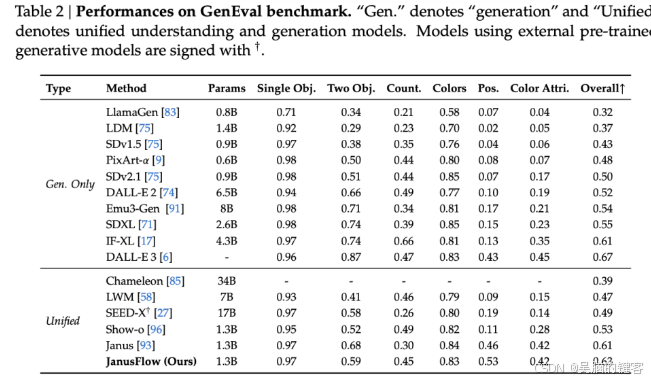
基准结果表明,JanusFlow 在 MMBench、SeedBench 和 GQA 上的得分分别为74.9、70.5和60.3,表现优于许多现有的统一模型。在图像生成方面,JanusFlow 超越了 SDv1.5和 SDXL,MJHQ FID-30k 得分为9.51,GenEval 得分为0.63。这些指标表明它在生成高质量图像和处理复杂多模态任务方面的卓越能力,且仅需1.3B 参数。
结论是,JanusFlow 在开发能够同时进行图像理解与生成的统一 AI 模型方面迈出了重要一步。它的简约方法 —— 专注于将自回归能力与纠正流整合 —— 不仅提升了性能,还简化了模型架构,使其更高效、可访问。
通过解耦视觉编码器并在训练过程中对齐表示,JanusFlow 成功架起了图像理解与生成之间的桥梁。随着 AI 研究不断突破模型能力的边界,JanusFlow 代表着朝着创造更具通用性和多功能性的多模态 AI 系统迈出的重要里程碑。
模型:https://huggingface.co/deepseek-ai/JanusFlow-1.3B
论文:https://arxiv.org/abs/2411.07975
演示
!git clone https://github.com/deepseek-ai/Janus.git
%%bash
cd Janus
pip install -e .
pip install diffusers[torch]
import torch
from janus.janusflow.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images
# specify the path to the model
model_path = "deepseek-ai/JanusFlow-1.3B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt = MultiModalityCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
conversation = [
{
"role": "User",
"content": "<image_placeholder>\nConvert the formula into latex code.",
"images": ["images/equation.png"],
},
{"role": "Assistant", "content": ""},
]
# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)
# # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
# # run the model to get the response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.
User: <image_placeholder>
Convert the formula into latex code.
Assistant: A_n = a_0 [ 1 + \frac{3}{4} \sum_{k=1}^{n} ( \frac{4}{9} ) ^ {k} ]
import os
import PIL.Image
import torch
import numpy as np
from janus.janusflow.models import MultiModalityCausalLM, VLChatProcessor
import torchvision
# specify the path to the model
model_path = "deepseek-ai/JanusFlow-1.3B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt = MultiModalityCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
from diffusers.models import AutoencoderKL
# remember to use bfloat16 dtype, this vae doesn't work with fp16
vae = AutoencoderKL.from_pretrained("stabilityai/sdxl-vae")
vae = vae.to(torch.bfloat16).cuda().eval()
conversation = [
{
"role": "User",
"content": "A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair",
},
{"role": "Assistant", "content": ""},
]
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_gen_tag
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
cfg_weight: float = 5.0,
num_inference_steps: int = 30,
batchsize: int = 5
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.stack([input_ids] * 2 * batchsize).cuda()
tokens[batchsize:, 1:] = vl_chat_processor.pad_id
inputs_embeds = vl_gpt.language_model.get_input_embeddings()(tokens)
# we remove the last <bog> token and replace it with t_emb later
inputs_embeds = inputs_embeds[:, :-1, :]
# generate with rectified flow ode
# step 1: encode with vision_gen_enc
z = torch.randn((batchsize, 4, 48, 48), dtype=torch.bfloat16).cuda()
dt = 1.0 / num_inference_steps
dt = torch.zeros_like(z).cuda().to(torch.bfloat16) + dt
# step 2: run ode
attention_mask = torch.ones((2*batchsize, inputs_embeds.shape[1]+577)).to(vl_gpt.device)
attention_mask[batchsize:, 1:inputs_embeds.shape[1]] = 0
attention_mask = attention_mask.int()
for step in range(num_inference_steps):
# prepare inputs for the llm
z_input = torch.cat([z, z], dim=0) # for cfg
t = step / num_inference_steps * 1000.
t = torch.tensor([t] * z_input.shape[0]).to(dt)
z_enc = vl_gpt.vision_gen_enc_model(z_input, t)
z_emb, t_emb, hs = z_enc[0], z_enc[1], z_enc[2]
z_emb = z_emb.view(z_emb.shape[0], z_emb.shape[1], -1).permute(0, 2, 1)
z_emb = vl_gpt.vision_gen_enc_aligner(z_emb)
llm_emb = torch.cat([inputs_embeds, t_emb.unsqueeze(1), z_emb], dim=1)
# input to the llm
# we apply attention mask for CFG: 1 for tokens that are not masked, 0 for tokens that are masked.
if step == 0:
outputs = vl_gpt.language_model.model(inputs_embeds=llm_emb,
use_cache=True,
attention_mask=attention_mask,
past_key_values=None)
past_key_values = []
for kv_cache in past_key_values:
k, v = kv_cache[0], kv_cache[1]
past_key_values.append((k[:, :, :inputs_embeds.shape[1], :], v[:, :, :inputs_embeds.shape[1], :]))
past_key_values = tuple(past_key_values)
else:
outputs = vl_gpt.language_model.model(inputs_embeds=llm_emb,
use_cache=True,
attention_mask=attention_mask,
past_key_values=past_key_values)
hidden_states = outputs.last_hidden_state
# transform hidden_states back to v
hidden_states = vl_gpt.vision_gen_dec_aligner(vl_gpt.vision_gen_dec_aligner_norm(hidden_states[:, -576:, :]))
hidden_states = hidden_states.reshape(z_emb.shape[0], 24, 24, 768).permute(0, 3, 1, 2)
v = vl_gpt.vision_gen_dec_model(hidden_states, hs, t_emb)
v_cond, v_uncond = torch.chunk(v, 2)
v = cfg_weight * v_cond - (cfg_weight-1.) * v_uncond
z = z + dt * v
# step 3: decode with vision_gen_dec and sdxl vae
decoded_image = vae.decode(z / vae.config.scaling_factor).sample
os.makedirs('generated_samples', exist_ok=True)
save_path = os.path.join('generated_samples', "img.jpg")
torchvision.utils.save_image(decoded_image.clip_(-1.0, 1.0)*0.5+0.5, save_path)
generate(
vl_gpt,
vl_chat_processor,
prompt,
cfg_weight=2.0,
num_inference_steps=30,
batchsize=5
)



















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









