







华为诺亚方舟实验室与香港大学自然语言处理组联合发布的Dream7B是一款具有创新意义的开源扩散大型语言模型。以下是关于它的详细介绍:
模型架构
Dream7B基于离散扩散模型(DMs),采用掩码扩散范式,从纯噪声状态逐步去噪生成文本。与传统自回归模型按从左到右顺序逐个生成文本不同,它能同时考虑文本序列中双向的信息,实现双向语境建模,提升文本连贯性,还支持灵活可控的生成能力以及潜在的采样加速能力。
性能表现
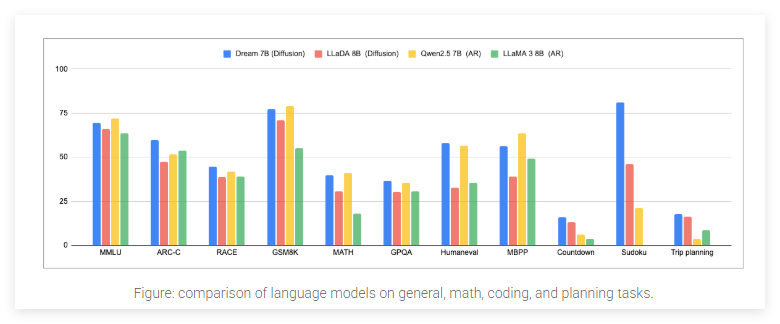
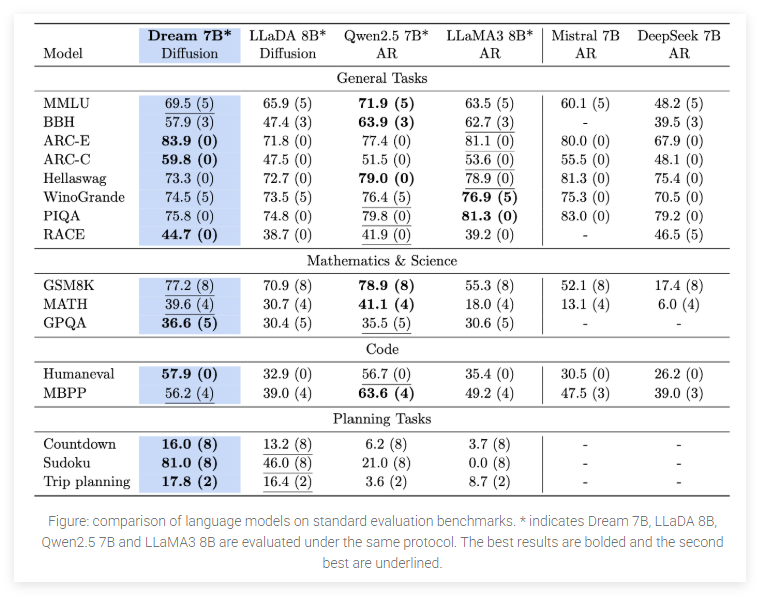
- 超越现有扩散语言模型:在多个关键能力上表现出色,大幅超越了之前的扩散语言模型。
- 媲美顶尖自回归模型:在通用能力、数学推理和编程任务上,与同等规模的顶尖自回归模型(如Qwen2.5 7B、LLaMA3 8B)性能相当,在某些方面甚至超越了更大的DeepSeek V3 671B模型。
- 规划能力突出:在Countdown和Sudoku等需要规划能力的任务中,显著优于同等规模的其他模型,有时能匹敌参数量远超自身的DeepSeek V3。
创新技术
- 任意顺序生成:不受生成顺序限制,可以按照任意顺序合成输出,更好地适应不同用户查询。
- 上下文自适应token级噪声重排机制:能根据每个token的上下文信息量动态调整噪声水平,实现精细化学习,为每个token的生成提供更精准指导。
- 自回归模型初始化:利用自回归模型(如Qwen2.5)的权重进行初始化,加速训练过程。
训练数据
Dream7B基于5800亿个标记进行预训练,耗时256小时。训练数据全面覆盖文本、数学和代码领域,主要来源于Dolma v1.7、OpenCoder和DCLM - Baseline,并经过一系列精细的预处理和数据优化流程。
开源情况
目前,Dream7B已经开源了其基础模型和指令微调模型的权重,代码也已在GitHub上公开,相关资源可在项目主页https://hkunlp.github.io/blog/2025/dream/、GitHub仓库https://github.com/HKUNLP/Dream以及HuggingFace仓库https://huggingface.co/Dream - org获取,还可在https://huggingface.co/spaces/multimodalart/Dream在线体验。
import torch
from transformers import AutoModel, AutoTokenizer
model_path = "Dream-org/Dream-v0-Instruct-7B"
model = AutoModel.from_pretrained(model_path, torch_dtype=torch.bfloat16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = model.to("cuda").eval()
messages = [
{"role": "user", "content": "Please write a Python class that implements a PyTorch trainer capable of training a model on a toy dataset."}
]
inputs = tokenizer.apply_chat_template(
messages, return_tensors="pt", return_dict=True, add_generation_prompt=True
)
input_ids = inputs.input_ids.to(device="cuda")
attention_mask = inputs.attention_mask.to(device="cuda")
output = model.diffusion_generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=512,
output_history=True,
return_dict_in_generate=True,
steps=512,
temperature=0.2,
top_p=0.95,
alg="entropy",
alg_temp=0.,
)
generations = [
tokenizer.decode(g[len(p) :].tolist())
for p, g in zip(input_ids, output.sequences)
]
print(generations[0].split(tokenizer.eos_token)[0])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









