








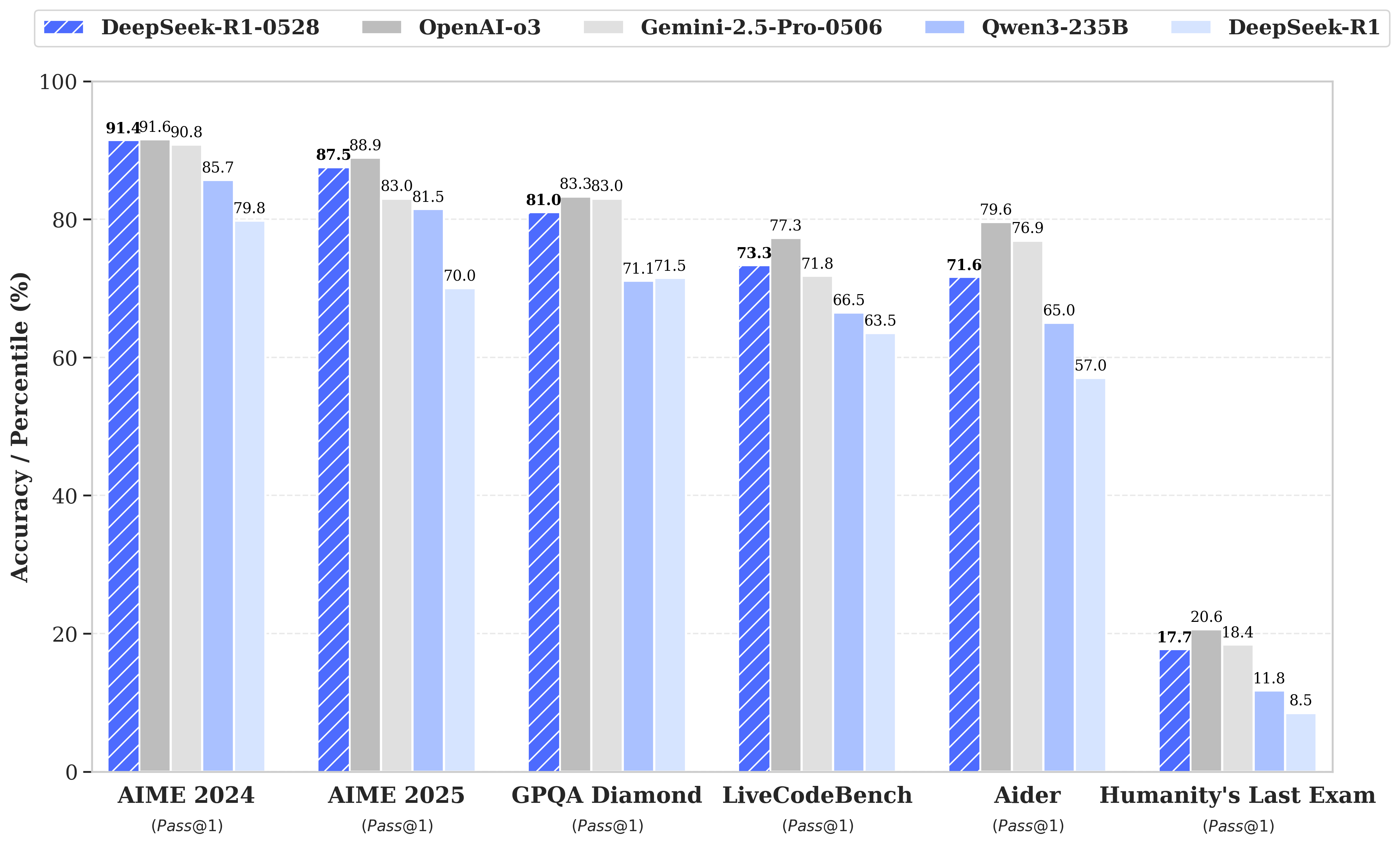
DeepSeek R1模型已完成小幅版本升级,当前版本为DeepSeek-R1-0528。在最新更新中,通过增加计算资源投入并在后训练阶段引入算法优化机制,DeepSeek R1的深度推理能力得到显著提升。该模型在数学、编程及通用逻辑等多类基准测试中均展现出卓越性能,整体表现已接近O3和Gemini 2.5 Pro等领先模型水平。
相比上一版本,升级后的模型在处理复杂推理任务方面展现出显著提升。例如在AIME 2025测试中,模型准确率从旧版的70%提升至当前版本的87.5%。这项进步源于推理过程中思维深度的增强:在AIME测试集上,旧版模型平均每个问题消耗12K tokens,而新版平均每个问题消耗23K tokens。
除推理能力提升外,该版本还具有更低的幻觉率、更强的函数调用支持能力,并为氛围编码提供了更优质的体验。
DeepSeek-R1-0528
对于我们所有的模型,最大生成长度设置为64K个token。在需要采样的基准测试中,我们使用的温度参数为0.6,top-p值为0.95,并且每个查询生成16个响应以估算pass@1指标。
| Category | Benchmark (Metric) | DeepSeek R1 | DeepSeek R1 0528 |
|---|---|---|---|
| General | |||
| MMLU-Redux (EM) | 92.9 | 93.4 | |
| MMLU-Pro (EM) | 84.0 | 85.0 | |
| GPQA-Diamond (Pass@1) | 71.5 | 81.0 | |
| SimpleQA (Correct) | 30.1 | 27.8 | |
| FRAMES (Acc.) | 82.5 | 83.0 | |
| Humanity’s Last Exam (Pass@1) | 8.5 | 17.7 | |
| Code | |||
| LiveCodeBench (2408-2505) (Pass@1) | 63.5 | 73.3 | |
| Codeforces-Div1 (Rating) | 1530 | 1930 | |
| SWE Verified (Resolved) | 49.2 | 57.6 | |
| Aider-Polyglot (Acc.) | 53.3 | 71.6 | |
| Math | |||
| AIME 2024 (Pass@1) | 79.8 | 91.4 | |
| AIME 2025 (Pass@1) | 70.0 | 87.5 | |
| HMMT 2025 (Pass@1) | 41.7 | 79.4 | |
| CNMO 2024 (Pass@1) | 78.8 | 86.9 | |
| Tools | |||
| BFCL_v3_MultiTurn (Acc) | - | 37.0 | |
| Tau-Bench (Pass@1) | - | 53.5(Airline)/63.9(Retail) |
DeepSeek-R1-0528-Qwen3-8B
与此同时,我们从DeepSeek-R1-0528中提炼思维链对Qwen3 8B基础模型进行后训练,获得了DeepSeek-R1-0528-Qwen3-8B。该模型在AIME 2024评测中实现了开源模型的顶尖性能(SOTA),较原版Qwen3 8B提升+10.0%,并达到Qwen3-235B思维版的表现水平。我们相信,DeepSeek-R1-0528的思维链对于推理模型的学术研究以及聚焦小规模模型的工业发展都具有重要意义。
| AIME 24 | AIME 25 | HMMT Feb 25 | GPQA Diamond | LiveCodeBench (2408-2505) | |
|---|---|---|---|---|---|
| Qwen3-235B-A22B | 85.7 | 81.5 | 62.5 | 71.1 | 66.5 |
| Qwen3-32B | 81.4 | 72.9 | - | 68.4 | - |
| Qwen3-8B | 76.0 | 67.3 | - | 62.0 | - |
| Phi-4-Reasoning-Plus-14B | 81.3 | 78.0 | 53.6 | 69.3 | - |
| Gemini-2.5-Flash-Thinking-0520 | 82.3 | 72.0 | 64.2 | 82.8 | 62.3 |
| o3-mini (medium) | 79.6 | 76.7 | 53.3 | 76.8 | 65.9 |
| DeepSeek-R1-0528-Qwen3-8B | 86.0 | 76.3 | 61.5 | 61.1 | 60.5 |
3. 聊天网站与API平台
您可以在DeepSeek官网与DeepSeek-R1对话:chat.deepseek.com,并开启"DeepThink"功能按钮。
我们还提供了OpenAI兼容的API平台:platform.deepseek.com
4. 如何本地运行
请访问DeepSeek-R1代码库获取DeepSeek-R1-0528的本地运行指南。
相比于之前的DeepSeek-R1版本,DeepSeek-R1-0528的使用建议有以下变化:
- 现已支持系统提示词功能
- 无需在输出开头添加"<think>\n"强制模型进入思考模式
DeepSeek-R1-0528-Qwen3-8B的模型架构与Qwen3-8B完全相同,但采用与DeepSeek-R1-0528相同的分词器配置。该模型可按照Qwen3-8B的相同方式运行。
系统提示词
在官方DeepSeek网页/应用中,我们使用带具体日期的统一系统提示:
This assistant is DeepSeek-R1, created by DeepSeek Inc.
Today is {current date}.
例如:
This assistant is DeepSeek-R1, created by DeepSeek Inc.
Today is May 28, 2025, Monday.
Temperature
在我们的网页和应用环境中,Temperature T m o d e l T_{model} Tmodel设置为0.6。
文件上传和网络搜索的提示词
对于文件上传,请按照模板创建提示词,其中{file_name}、{file_content}和{question}为参数。
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
对于网络搜索,{search_results} {cur_date}和{question}是参数。对于中文查询,我们使用提示语:
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
对于英文查询,我们使用提示:
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
Kaggle
!pip install transformers hf_xet bitsandbytes -U
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "deepseek-ai/DeepSeek-R1-0528-Qwen3-8B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
thinking content: <think>
Okay, user asked for a short introduction to large language models. They probably want a concise but informative overview without too much jargon. Maybe they're just starting to learn about this topic or need a quick refresher for a presentation.
Hmm, I should keep it simple but cover the essentials. First, explain what LLMs are in basic terms - they're AI systems that process and generate human-like text. Then mention how they're trained, since that's fundamental to understanding them. The transformer architecture is worth noting because it's what makes them special.
I wonder if the user knows about things like GPT or BERT? Maybe I should include those as examples since they're the most well-known models. But keep it brief - just say they're examples rather than diving into details.
The applications part is important too. User might be curious about practical uses. I'll list a few key areas like text generation, translation, coding help etc. but not make it too long.
Should I mention limitations? Maybe briefly, since the user asked for a short intro but it's good to be balanced. Just a quick note about resource needs and potential biases without going into depth.
The tone should be friendly and accessible. No need for academic language since they didn't specify a technical audience. I'll structure it with clear points but keep the sentences short for readability.
Let me check if I'm covering all the bases: definition, training method, architecture, examples, applications, and brief pros/cons. That should give a complete picture in just a few sentences. The user said "short" so I'll need to be economical with words while still being informative.
</think>
content: Okay, here's a short introduction to Large Language Models (LLMs):
Large Language Models (LLMs) are sophisticated AI systems, typically based on the transformer architecture, trained extensively on massive datasets of text from the internet. Their primary goal is to learn the patterns, grammar, and semantics of human language. Once trained, LLMs can perform a wide range of natural language tasks, such as generating human-like text, translating languages, summarizing information, answering questions, and even writing code, simply by being prompted with a few words or sentences. They represent a significant leap in AI's ability to understand and produce language.


















 1244
1244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









