







文章目录
神经网络的算法优化
TensorFlow
TensorFlow程序可以通过tf.device函数来制定运行每一个操作的设备
这个设备可以是本地的CPU或GPU,也可以是某一台远程的服务器
TensorFlow会给每一个可用的设备一个名称,tf.device函数可以通过设备的名称,来指定运算的设备,比如CPU在TensorFlow中的名称为/cpu:0
在默认情况下,即使机器有多个CPU,TensorFlow也不会区分它们,所有的CPU都是用/cpu:0作为名称
-而一台机器上不同GPU的名称是不同的,第n个GPU在TensorFlow中的名称为/gpu:n
-比如第一个GPU的名称为/gpu:0,第二个GPU名称为/gpu:1,以此类推
-TensorFlow提供了一个快捷的方式,来查看运行每一个运算的设备
-在生成会话时,可以通过设置log_device_placement参数来打印运行每一个运算的设备
-除了可以看到最后的计算结果之外,还可以看到类似“add:/job:localhost/replica:0/task:0/cpu:0“这样的输出
-这些输出显示了执行每一个运算的设备。比如加法操作add是通过CPU来运行的,因为它的设备名称中包含了/cpu:0
-在配置好GPU环境的TensorFlow中,如果操作没有明确的指定运行设备,那么TensorFlow会优先选择GPU
TensorFlow里的变量和常量
placeholder节点和Variable节点属于变量
使用placeholder()给输出的tensor指定数据类型,也可以选择指定形状
如果你指定None对于某一个维度,它的意思代表任意大小
这些节点特点是它们不真正的计算,他们只是在执行的过程中你要它们输出数据的时候去输出数据
constant:常量
正则化

Inverted DropOut反向随机失活
d3 = np.randm.rand(a3.shape[0], a3.shape[1]) < keep_prob
a3 = np.multiply(a3, d3)
a3 /= keep-prob
假设有50个神经元, keep-prob = 0.8, 也就意味着10个左右的神经元要设为0
在这种情况下, z = wa + b 就要减少20%, 这样呢,z会越来越小
为了弥补这种情况,我们需要对a进行弥补,弥补的方式就是用a/keep_prob
梯度下降的优化算法
指数加权平均

指数加权平均的作用


动量梯度算法

计算梯度的指数加权平均数,并利用该梯度更新你的权重值
RMSprop
为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对权重 W 和偏置 bb的梯度使用了微分平方加权平均数。 其中,假设在第 t 轮迭代过程中,各个公式如下所示:
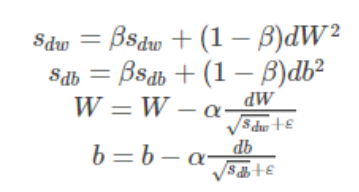
Adam
有了上面两种优化算法,一种可以使用类似于物理中的动量来累积梯度,另一种可以使得收敛速度更快同时使得波动的幅度更小。那么讲两种算法结合起来所取得的表现一定会更好。Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用的一种算法

Softmax


代码实现
tensorflow实现DNN
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
from tensorflow.contrib.layers import fully_connected
import matplotlib.pyplot as plt
# 构建图阶段
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









