







纸上得来终觉浅,绝知此事要躬行
1动态规划
1.1字符串最长公共子序列LCS
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。
输入:text1 = “abcde”, text2 = “ace”
输出:3
解释:最长公共子序列是 “ace”,它的长度为 3。
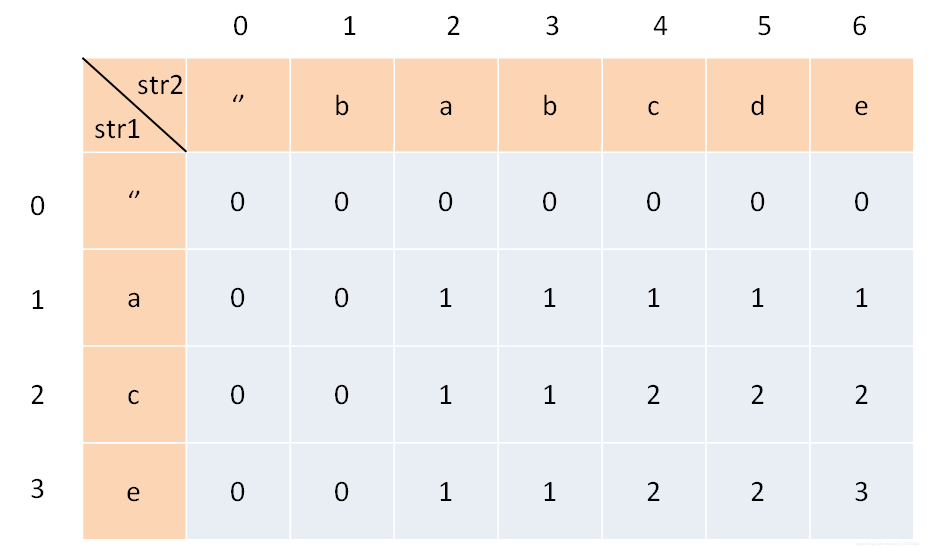
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
vector<vector<int> > dp(text1.size()+1,vector<int>(text2.size()+1,0));
//dp[i][j]表示text1[0..i-1]和text2[0..j-1]的最长公共子串未dp[i][j]
for(int i=1;i<text1.size()+1;i++)
{
for(int j=1;j<text2.size()+1;j++)
{
//状态转移方程
if(text1[i-1] == text2[j-1])
dp[i][j] = dp[i-1][j-1] + 1;
else
dp[i][j] = max(dp[i-1][j],dp[i][j-1]);
}
}
return dp[text1.size()][text2.size()];
}
};
1.2字符串最长公共子串
子串必须连续,子序列可以不连续。
只需将LCS中状态转移方程改为
#include<iostream>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
int main()
{
string text1,text2;
getline(cin, text1);
getline(cin, text2);
vector<vector<int> > dp(text1.size() + 1, vector<int>(text2.size() + 1, 0));
int maxl = 0,k1 = 0,k2 = 0;
for (int i = 1;i < text1.size() + 1;i++)
{
for (int j = 1;j < text2.size() + 1;j++)
{
//状态转移方程
if (text1[i - 1] == text2[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
if (dp[i][j] > maxl) {
maxl = dp[i][j];
k1 = i-1;
k2 = j-1;
}
}
}
cout << "最长子串长度:" << maxl << endl;
cout << "最长子串在text1中为:" << text1.substr(k1 - maxl + 1, maxl) << endl;
cout << "最长子串在text2中为:" << text2.substr(k2 - maxl + 1, maxl) << endl;
system("pause");
return 0;
}
1.3 编辑距离
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。力扣
你可以对一个单词进行如下三种操作:插入一个字符、删除一个字符替换一个字符
int minDistance(string word1, string word2) {
int r = word1.size()+1;
int c = word2.size()+1;
vector<vector<int>> dp(r,vector<int>(c,0));
//dp[i][j]表示将word1[0..i-1]变换成word2[0...j-1]所作的最少操作次数
for(int j=0;j<c;j++)
dp[0][j] = j; //word1 为空字符串 只做插入操作
for(int i=0;i<r;i++)
dp[i][0] = i; //word2为空字符串 只做删除操作
for(int i=1;i<r;i++){
for(int j=1;j<c;j++){
if(word1[i-1]==word2[j-1]) //注意下标
dp[i][j] = dp[i-1][j-1];
else
dp[i][j] = min(min(dp[i][j-1],dp[i-1][j]),dp[i-1][j-1])+1; //分别对应插入、删除、替换
}
}
return dp[r-1][c-1];
}
1.4字符串匹配KMP
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。力扣
输入: haystack = “hello”, needle = “ll”
输出: 2
(1)调用库函数,哈哈哈
class Solution {
public:
int strStr(string haystack, string needle) {
if(needle.size()==0)
return 0;
string::size_type p = haystack.find(needle);
if(p!=haystack.npos)
return p;
else
return -1;
}
};
(2)暴力解法,正常人都这样想好吗
class Solution {
public:
int strStr(string haystack, string needle) {
if(needle.size()==0)
return 0;
int i=0, j=0; //双指针
int n = haystack.size(), m = needle.size();
while(i<n && j<m){
if(haystack[i] == needle[j]){
i++;
j++;
}
else{ //回退方式简单,这也是暴力解法时间复杂度较高的原因
i=i-j+1;
j=0;
}
}
if(j==m)
return i-m;
else
return -1;
}
};
(3)KMP
暴力解法的时间复杂度为O(m*n),空间复杂度为O(1),遇到不匹配的地方,i、j回退的方式简单粗暴,导致时间复杂度过高,但是空间复杂度很低。
KMP是空间换时间的思想,i指针永不回退,j指针根据状态转移矩阵dp回退到合适的位置。时间复杂度为O(n),重点在于状态转移矩阵dp的设计。下面这个图不要太生动的展示了根据dp匹配字符串的过程。
KMP讲解,很清晰,推荐
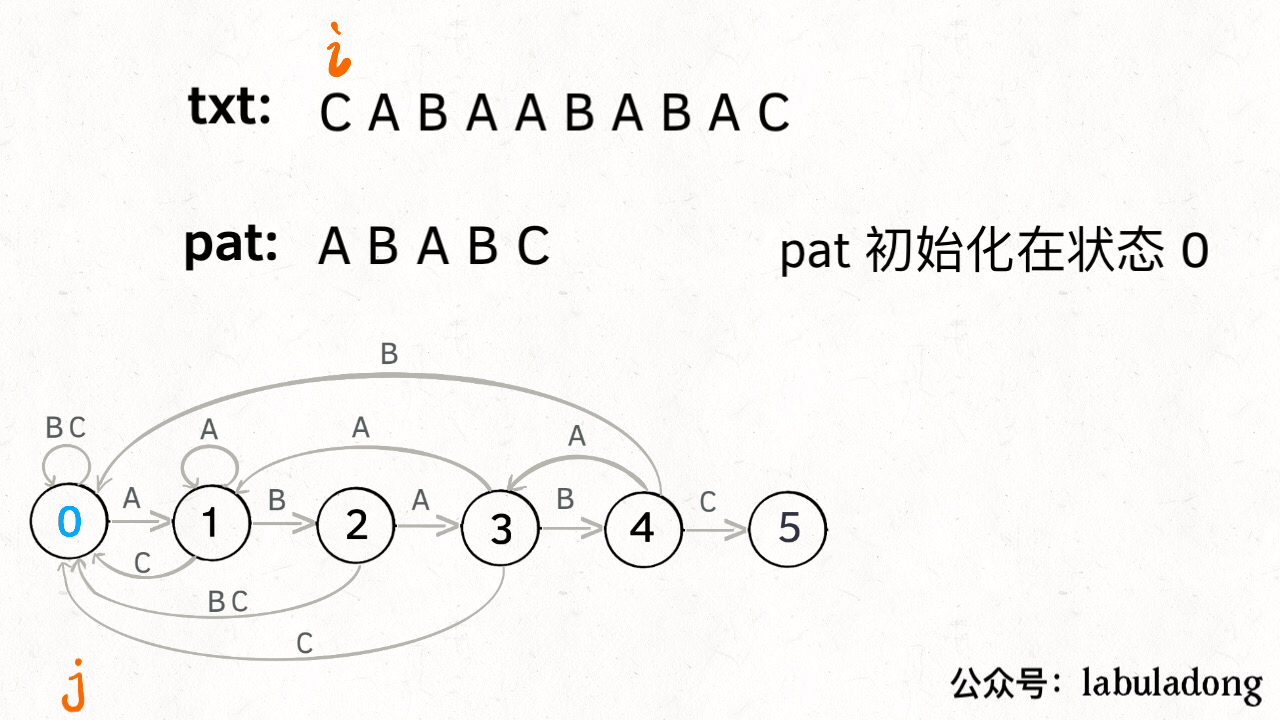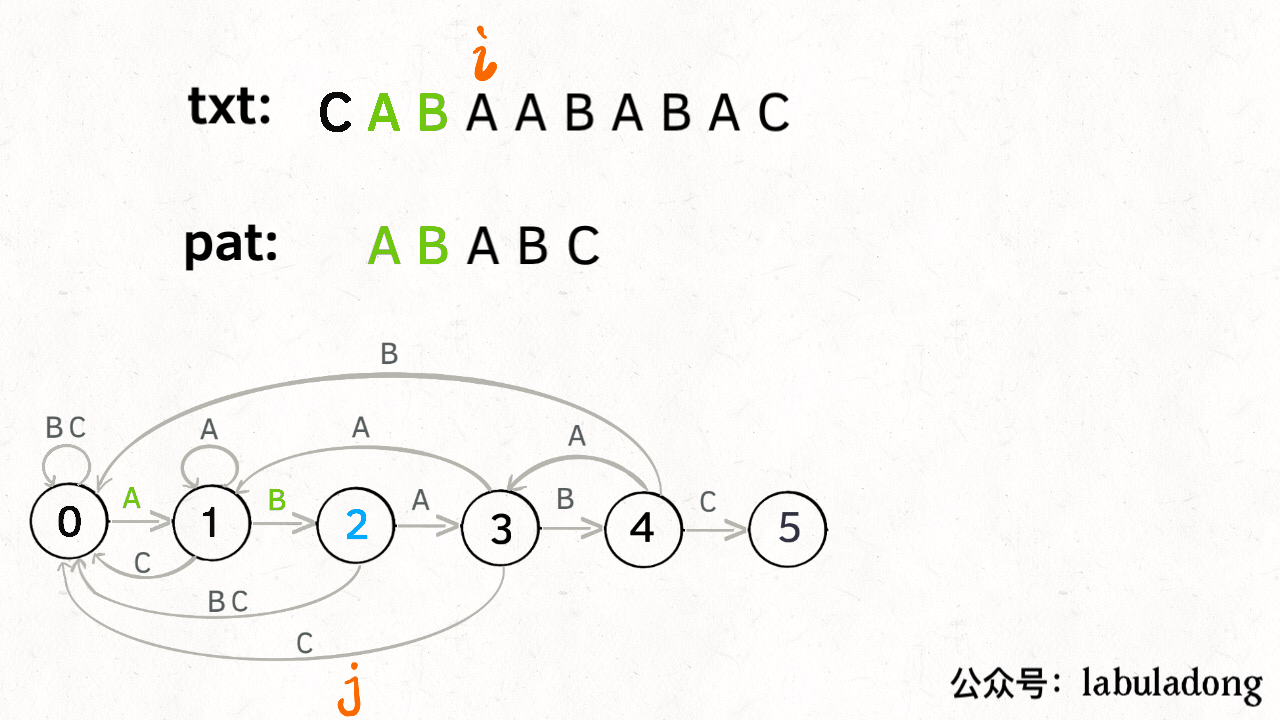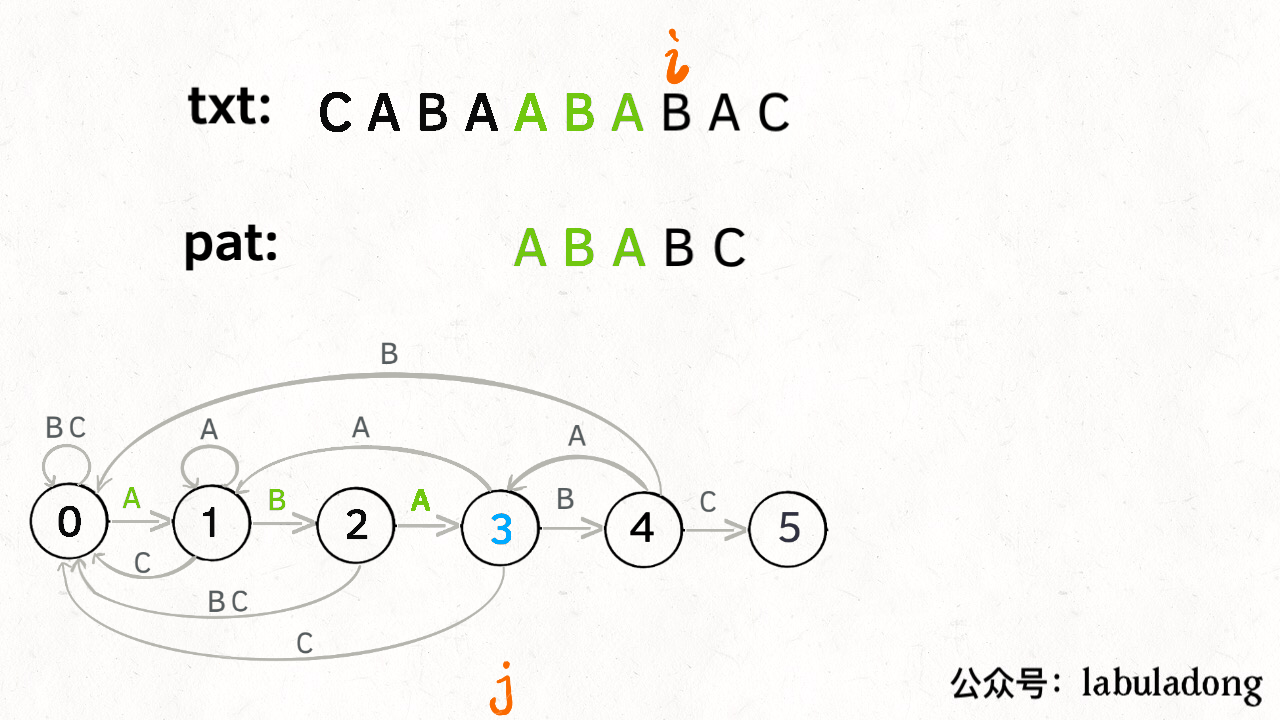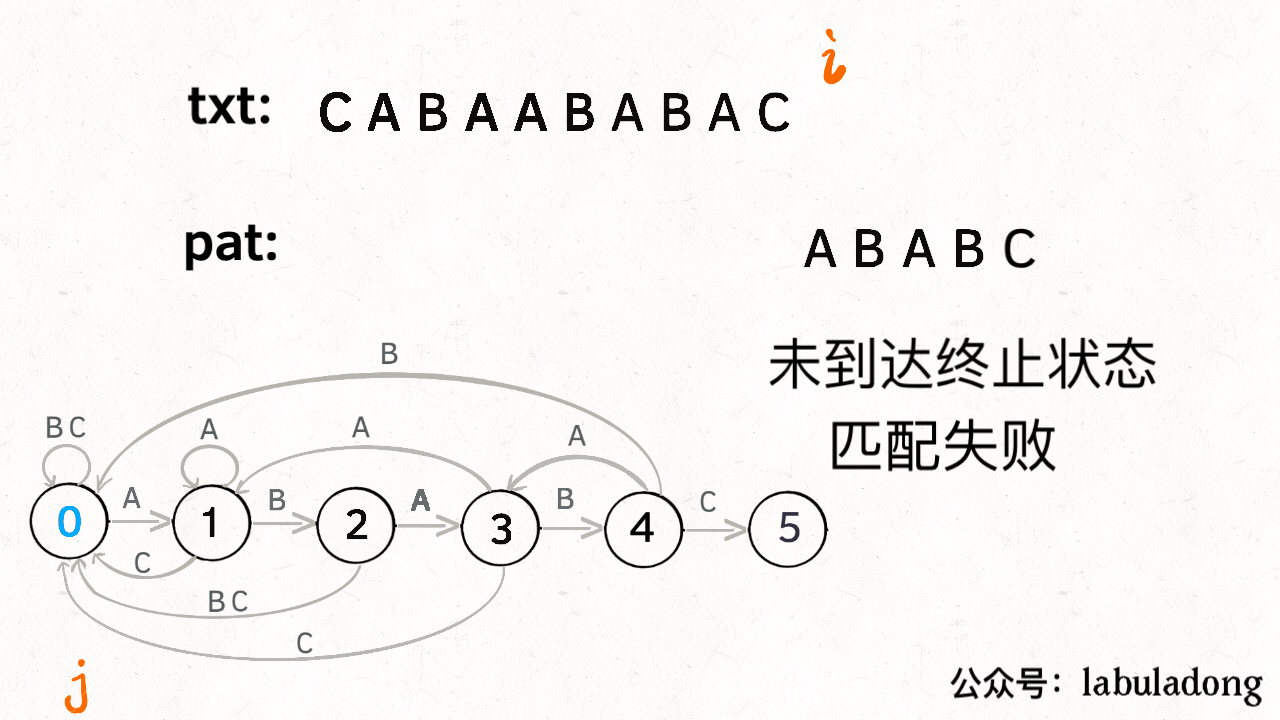
class Solution {
public:
int strStr(string haystack, string needle) {
if(needle.size()==0)
return 0;
int n = haystack.size();
int m = needle.size();
//构建状态转移矩阵
vector<vector<int> >dp(m,vector<int>(256,0)); //dp[j][k] 在状态j是,输入字符k后应转移到状态dp[j][k]
dp[0][needle[0]] = 1; //在0状态下只有输入needle的第一个字符才转移到状态1
int x=0;
for(int j=1;j<m;j++){
for(int k=0;k<256;k++){
dp[j][k] = dp[x][k];
dp[j][needle[j]] = j+1;
}
x = dp[x][needle[j]];
}
//匹配
int j = 0;
for(int i=0;i<n;i++){
j = dp[j][haystack[i]];
if(j==m)
return i-m+1;
}
return -1;
}
};
2 LRU淘汰缓存
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
(1)获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),并置为最近使用的数据,否则返回 -1。
(2)写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。力扣
高效的查询和插入删除操作,散列表+双向链表
class LRUCache {
private:
unordered_map<int,list<pair<int,int>>::iterator> table;
list<pair<int,int>> lru;
int cap;
public:
LRUCache(int capacity) :cap(capacity){
}
int get(int key) {
if(!table.count(key)) //没找到
return -1;
list<pair<int,int>>::iterator node = table[key];
lru.splice(lru.begin(),lru,node);
return node->second;
}
void put(int key, int value) {
if(!table.count(key)) //没找到,插入
{
lru.emplace_front(key,value);
table[key] = lru.begin();
if(table.size()>cap) //缓存满了,去除尾节点
{
table.erase(lru.back().first);
lru.pop_back();
}
}
else
{
lru.splice(lru.begin(),lru,table[key]);
table[key]->second = value;
}
return;
}
};
3 判断两个链表相交
三种方法
4 反转字符串
void reverseString(vector<char>& s) {
if(s.size()<2) return;
for(int i=0,j=s.size()-1;i<j;i++,j--)
swap(s[i],s[j]);
}
5 翻转单词顺序列
string reverseWords(string s) {
reverse(s.begin(),s.end()); //reverse函数可换成上一题函数
int i =0,j=0;
while(i<s.size()){
if(s[j]!=' ')
j++;
if(s[j]==' ' || j==s.size()){
reverse(&s[i],&s[j]);
i = j+1;
j++;
}
}
return s;
}
6 两个升序链表组合成一个降序链表
合并为升序:力扣
合并为降序:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if(!l1&&!l2) return nullptr;
ListNode* ans = nullptr;
while(l1 || l2){
if(!l1){
ListNode* tem = l2->next;
l2->next = ans;
ans = l2;
l2 = tem;
continue;
}
if(!l2){
ListNode* tem = l1->next;
l1->next = ans;
ans = l1;
l1 = tem;
continue;
}
if(l1->val < l2->val){
ListNode* tem = l1->next;
l1->next = ans;
ans = l1;
l1 = tem;
}
else{
ListNode* tem = l2->next;
l2->next = ans;
ans = l2;
l2 = tem;
}
}
return ans;
}
7 回文链表
利用快慢指针,找到中间节点
将后半链表反转
判断两个半段的链表是不是一样。
8 计数质数
力扣
统计所有小于非负整数 n 的质数的数量。
输入: 10输出: 4
解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
class Solution {
public:
/*
bool isPrimes(int n){
for(int i=2;i*i<=n;i++){
if(n%i==0)
return false;
}
return true;
}
int countPrimes(int n) {
int count = 0;
for(int i=2;i<n;i++){
if(isPrimes(i))
count++;
}
return count;
}
*/
int countPrimes(int n) {
int count = 0;
vector<bool> flag(n,true);
for(int i=2;i*i<=n;i++){
if(flag[i]){
for(int j=2*i;j<n;j=j+i)
flag[j]=false;
}
}
for(int i=2;i<n;i++)
if(flag[i])
count++;
return count;
}
};
9 超次方程(含快速幂法)
计算 ab 对 1337 取模,a 是一个正整数,b 是一个非常大的正整数且会以数组形式给出。
力扣
10 编辑距离
计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:插入一个字符、删除一个字符、替换一个字符
力扣
11 二分查找
vector<int> searchRange(vector<int>& nums, int target) {
if(nums.size()==0)
return {-1,-1};
if(target<nums[0] || target>nums.back())
return {-1,-1};
vector<int> ans(2,-1);
//-----寻找左边界--------------
int begin = 0;
int end = nums.size()-1;
while(begin<=end){
int mid = begin + (end-begin>>1);
if(nums[mid]>=target)
end = mid-1;
else
begin = mid+1;
}
ans[0] = (nums[begin]==target)?begin:-1; //!!!
begin = 0;
end = nums.size()-1;
//-----寻找右边界--------------
while(begin<=end){
int mid = begin + (end-begin>>1);
if(nums[mid]<=target)
begin = mid+1;
else
end = mid-1;
}
ans[1] = (nums[end]==target)?end:-1;
return ans;
}
12 接雨水
13 删除有序数组重复元素
14 最长回文子串
15 排序一揽子
本节内容均来自 极客时间-数据结构与算法之美-王争
评价分析一个排序算法
-
执行效率(最好最坏平均、系数常数低阶、比较和交换的次数)
-
内存消耗(空间复杂度)
-
稳定性(相同元素排序后原有顺序是否改变)
对电商交易平台的订单排序,每个订单包括下单时间,订单金额两个属性。我们希望按照金额从小到大排序,对于金额相同的订单,按照下单的先后排序。
解决方法:先按照时间排序,再用稳定的排序算法,按照金额排序。
1冒泡排序
每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就交换。一轮冒泡会让至少一个元素移动到它应该在的位置,重复n次,就完成了n个数据的排序工作。
void bubblesort(int* a,int n) {
bool flag = false;
for (int i = 0;i < n;i++) {
for (int j = 0;j < n - i - 1;j++) {
if (a[j] > a[j+1]) {
swap(a[j+1], a[j]); //元素交换
flag = true;
}
}
if (!flag) return;
}
}
分析:
- 最好情况:一开始就有序,一轮冒泡, O ( n ) O(n) O(n);
- 最坏情况:一开始倒序,n轮冒泡, O ( n 2 ) O(n^2) O(n2);
- 平均情况:n个数据,满有序度n(n-1)/2,假设初始有序度为 m,则要达到满有序需要交换的次数=逆序度。即 k = n(n-1)/2 – m;平均有序度为n(n-1)/4,所以平均需要交换n(n-1)/4次。比较的次数只会比交换的次数多,但比较的上限复杂度是 O ( n 2 ) O(n^2) O(n2),所以平均时间复杂度 O ( n 2 ) O(n^2) O(n2)。以上是“不严格”的推导。
2插入排序
将数组分为已排序区和未排序区,每次取未排序区的元素,在已排序区找到合适的位置将其插入。重复这个过程,直到未排序区为空。
void insertsort(int* a, int n) {
for (int i = 0;i < n;i++) {
int tem_i = a[i];//依次从未排序区首位取数据tem_i
int j = i - 1; //插入到已排序区
for (;j >= 0;j--) {
if (a[j] > tem_i)
a[j + 1] = a[j]; //数据移动
else
break;
}
a[++j] = tem_i;
}
}
分析:
- 最好情况:数据有序,不需要数据搬移,一次遍历, O ( n ) O(n) O(n);
- 最坏情况:数组倒序,每次插入都相当于在数组第一个位置插入新数据,需要大量的数据移动。 O ( n 2 ) O(n^2) O(n2);
- 平均情况:往数组中插入一个数据,平均时间复杂度O(n),插入排序每次插入操作都相当于在数组中插入一个数据。循环执行n次插入操作,所以平均时间复杂度 O ( n 2 ) O(n^2) O(n2).
3选择排序
将数组分为已排序区和未排序区,每次从未排序区选择最小的元素,将其放在未排序区首位。
void selectsort(int* a, int n) {
for (int i = 0;i < n;i++) {
int k = i;
int m = a[i];
for (int j = i;j < n;j++) { //从未排序区找到最小值
if (a[j] < m) {
m = a[j];
k = j;
}
}
swap(a[i], a[k]); //交换到未排序区首位i位置处
}
}
分析:
- 很明显,最好最坏平均时间复杂度都是 O ( n 2 ) O(n^2) O(n2)。
- 稳定性:不稳定,比如5,8,5,2,9.这样一组数据,第一次找到最小元素2,和第一个5交换位置,此时两个5相对顺序变了,所以不稳定。因此相对于冒泡和插入,选择排序稍微逊色。
插排比冒泡受欢迎
两者的时间复杂度,空间复杂度,稳定性相同
对于冒泡排序,需要进行元素交换的次数为原始数据的逆序度。
对于插入排序,需要进行元素移动的次数为原始数据的逆序度。
但是,从代码实现的角度看,数据交换比数据移动要复杂,冒泡排序需要3个赋值操作,而插入排序只需要一个。

所以,虽然时间复杂度上两者相同,但是如果希望把性能优化做到极致,首选插排。
冒泡、插入、选择三种排序算法,时间复杂度较高,适合小规模数据的排序。
4归并排序

void mergersort_c(int* a, int begin, int end) {
if (begin >= end) //递归终止条件
return;
int mid = begin + (end - begin >> 1);
//分治递归
mergersort_c(a, begin, mid);
mergersort_c(a, mid + 1, end);
//合并
vector<int> tem(end - begin + 1,0); //非原地排序
int k = 0;
int i = begin; int j = mid + 1;
while (i <= mid || j <= end) {
if (i > mid){
tem[k++] = a[j++];
continue;
}
if (j > end) {
tem[k++] = a[i++];
continue;
}
if (a[i] <= a[j]) //稳定的原因
tem[k++] = a[i++];
else
tem[k++] = a[j++];
}
for (int i = begin;i <= end;i++)
a[i] = tem[i - begin];
}
void mergersort(int* a, int n) {
mergersort_c(a, 0, n - 1);
}
分析:
- 如图推导过程。时间复杂度与原始数据有序度无关,所以时间复杂度非常稳定,最好最坏平均时间复杂度都是O(nlogn)。
- 但是它有一个致命的弱点,那就是它不是原地排序。所以并有快排应用广泛。
5快速排序
int partition(int* a, int begin, int end) {
int i = begin;
for (int j = begin;j < end;j++) {
if (a[j] < a[end]) {
swap(a[i], a[j]);
i++;
}
}
swap(a[i], a[end]);
return i;
}
void quicksort_c(int* a, int begin, int end) {
if (begin >= end) //递归终止条件
return;
int p = partition(a, begin, end); //获取分区点
quicksort_c(a, begin, p - 1);
quicksort_c(a, p + 1, end);
}
void quicksort(int* a, int n) {
quicksort_c(a, 0, n - 1);
}
分析:
- 如果分区点能将数组分成大致相等的两个区间,它的时间复杂度的推导如归并排序一样,时间复杂度为O(nlogn)。
- 如果两个分区不均等,极端情况下,数据有序,需要进行n次分区操作,时间复杂度退化为O(n2)。但是概率较小,并且可以通过合理的选择分区点来避免这种情况。
用快排思想在O(n)内查找第K大元素
利用快排分区函数的设计
取数组最后一个作为分区点,对数组原地分区,数组分成三部分 A [ 0 … p − 1 ] 、 A [ p ] 、 A [ p + 1 … n − 1 ] A[0…p-1]、A[p]、A[p+1…n-1] A[0…p−1]、A[p]、A[p+1…n−1]。如果 p + 1 = k p+1 = k p+1=k说明 A [ p ] A[p] A[p]就是第 k k k大的元素;如果 p + 1 < k p+1<k p+1<k,说明第 k k k大元素出现在 A [ p + 1 … n − 1 ] A[p+1…n-1] A[p+1…n−1]区间,递归在 A [ p + 1 … n − 1 ] A[p+1…n-1] A[p+1…n−1]区间查找,同理如果 p + 1 > k p+1>k p+1>k,递归在 A [ 0 … p − 1 ] A[0…p-1] A[0…p−1]区间查找。
时间复杂度分析:
T
=
n
+
n
/
2
+
n
/
4
+
…
+
1
=
2
n
−
1
T = n + n/2 + n/4 + … + 1 = 2n-1
T=n+n/2+n/4+…+1=2n−1 所以时间复杂度为
O
(
n
)
O(n)
O(n)。
合并有序的日志文件
-
假设有10个接口访问日志文件,每个日志文件大小约300MB,每个日志文件里的日志都是按照时间戳从小到大排序的。现在希望将这10个日志文件合并为一个日志文件,合并后的日志仍然按照时间戳从小到大排序。如果处理上述任务的内存只有1GB,如何解决。
-
先构建十条io流,分别指向十个文件,每条io流读取对应文件的第一条数据,然后比较时间戳,选择出时间戳最小的那条数据,将其写入一个新的文件,然后指向该时间戳的io流读取下一行数据,然后继续刚才的操作,比较选出最小的时间戳数据,写入新文件,io流读取下一行数据,以此类推,完成文件的合并, 这种处理方式,日志文件有n个数据就要比较n次,每次比较选出一条数据来写入,时间复杂度是O(n),空间复杂度是O(1),几乎不占用内存。
-
答案来自评论区李建辉同学,虽然这位同学不一定能看到这条申明,哈哈哈。
6桶排序
要排序n个数据,均匀划分到m个桶内,每个桶 k = n / m k=n/m k=n/m个元素。桶内使用快排时间复杂度为 O ( k l o g k ) O(klogk) O(klogk),m个同的时间复杂度为 O ( m ∗ k ∗ l o g k ) = O ( n l o g ( n / m ) ) O(m*k*logk) = O(nlog(n/m)) O(m∗k∗logk)=O(nlog(n/m)),当m接近n时,时间复杂度接近 O ( n ) O(n) O(n)。比较适合用在外部排序中。
-
问题:
假设有10GB的订单数据,我们希望按订单金额进行排序,但是内存有限,只有几百MB,没办法一次性把10G数据加载到内存中。
-
解决办法:
- 先扫描一遍文件,看订单数据所处的范围。假设订单金额最小1元,最大10万元。将订单金额划分到100个桶里,第一个桶存储订单金额在1元到1000元之内的订单,第二个桶存储订单金额在1001到2000元之间的订单,依此类推,每个桶对应一个文件,并按金额范围的大小顺序编号命名。
- 理想情况下,如果订单金额均匀分布,每个文件存储大约100MB的订单数据,就可以将每个文件依次加载到内存中,用快排排序,等所有文件都排好序后,只需要按照文件编号从小到大读取每个文件中的数据,并将其写入到一个文件中,那这个文件中存储的就是按照金额从小到大排序的订单数据了。
- 如果订单金额分布不均匀,导致某个桶对应的文件很大,仍然不能一次性加载到内存中,可以继续对这个文件划分更小的桶,直到所有文件都能一次性加载到内存中为止。
7计数排序
桶排序的一种特殊情况。当要排序的n个数据所处的范围并不太大的时候,比如最大值是k,我们就可以把数据划分为k个桶。每个桶内的数据值相同,省掉了桶内排序的时间
例如对50万考生成绩排序,满分900分,最小分0分,数据范围很小,分成901个桶,对应0分到900分。根据成绩,将50万考生划分到对应的桶里,依次扫描每个桶,将桶内的考生输出到一个数组中,就实现了50万考生的排序。因为只涉及扫描遍历操作,所以时间复杂度是O(n)。
对数组A={2,5,3,0,2,3,0,3}用桶排序排序。
#include<iostream>
#include<algorithm>
using namespace std;
int main() {
//输入
int A[] = { 2,5,3,0,2,3,0,3};
int n = 8;
//桶排序
int max_num = *max_element(A, A + n);
vector<int> C(max_num + 1, 0);
vector<int> sortedA(n, 0);
for (int i = 0;i < n;i++) // C[i] 2 0 2 3 0 1 值对应数据出现的次数
C[A[i]]++; // i 0 1 2 3 4 5 下标对应数据范围
for (int i = 1;i < C.size();i++) // C[i] 2 2 4 7 7 8 小于等于i的数据的个数
C[i] = C[i] + C[i - 1]; // i 0 1 2 3 4 5 下标对应数据范围
for (int i = n - 1;i >= 0;i--) {
int index = C[A[i]] - 1;
sortedA[index] = A[i]; //把数据放在正确的位置
C[A[i]]--;
}
//输出排序后数据
for(int i=0;i<n;i++)
cout << sortedA[i] << endl;
system("pause");
return 0;
}
使用场景
- 数据范围不大,如果数据范围k比要排序的数据n大很多,不适合计数排序,比如要排序两个数, 13,1000
- 数据为非负整数,如果要排序的数据是其他类型,要将其在不改变相对大小的情况下,转为非负整数。
比如:
- 如果考生成绩精确到小数点后一位,需要将所有分数先乘以10转为整数,再放到9001个桶内。
- 如果要排序的数据中有负数,比如数据范围是[-1000,1000],需要对每个数据加1000,转成非负整数。
8基数排序
堆排序















 5522
5522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









