






前言:
在pytorch卷积层中对卷积核的可视化有些疑问,不知道其中具体的运行过程。考虑到无论是模型还是卷积层,池化层都是继承nn.Module类,本文通过源码了解部分类方法。
1、先随便构建一个Net网络
class Net(nn.Module):
def __init__(self, num_class=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3),
nn.BatchNorm2d(6),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=9, kernel_size=3),
nn.BatchNorm2d(9),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Linear(9 * 8 * 8, 128),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(128, num_class)
)
def forward(self, x):
output = self.features(x)
output = output.view(output.size()[0], -1)
output = self.classifier(output)
return output
查看Net网络具体的方法
# 查看model类的方法
model = Net()
dir(model)
out:
['T_destination',
'__annotations__',
'__call__',
'__class__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattr__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__setstate__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__weakref__',
'_apply',
'_backward_hooks',
'_buffers',
'_call_impl',
'_forward_hooks',
'_forward_pre_hooks',
'_get_backward_hooks',
'_get_name',
'_is_full_backward_hook',
'_load_from_state_dict',
'_load_state_dict_post_hooks',
'_load_state_dict_pre_hooks',
'_maybe_warn_non_full_backward_hook',
'_modules',
'_named_members',
'_non_persistent_buffers_set',
'_parameters',
'_register_load_state_dict_pre_hook',
'_register_state_dict_hook',
'_replicate_for_data_parallel',
'_save_to_state_dict',
'_slow_forward',
'_state_dict_hooks',
'_version',
'add_module',
'apply',
'bfloat16',
'buffers',
'children',
'classifier',
'cpu',
'cuda',
'double',
'dump_patches',
'eval',
'extra_repr',
'features',
'float',
'forward',
'get_buffer',
'get_extra_state',
'get_parameter',
'get_submodule',
'half',
'ipu',
'load_state_dict',
'modules',
'named_buffers',
'named_children',
'named_modules',
'named_parameters',
'parameters',
'register_backward_hook',
'register_buffer',
'register_forward_hook',
'register_forward_pre_hook',
'register_full_backward_hook',
'register_load_state_dict_post_hook',
'register_module',
'register_parameter',
'requires_grad_',
'set_extra_state',
'share_memory',
'state_dict',
'to',
'to_empty',
'train',
'training',
'type',
'xpu',
'zero_grad']
1.0 children()方法:
查看源码:该方法是返回直接子模块上的迭代器。注意,只返回模型直接子模块的迭代器
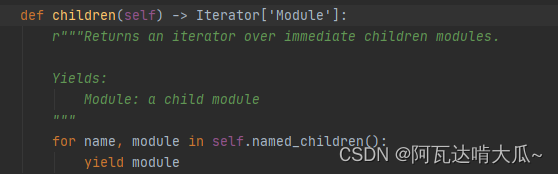
例如:
for mod in model.children():
print(mod)
out:
Sequential(
(0): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
(5): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=128, out_features=10, bias=True)
)
可以看到只返回2个自定义的层。
1.1 named_children()方法
查看named_children()的源码如下:大致的意思是会返回子模块上的迭代器,生成模块名称和模块本身。
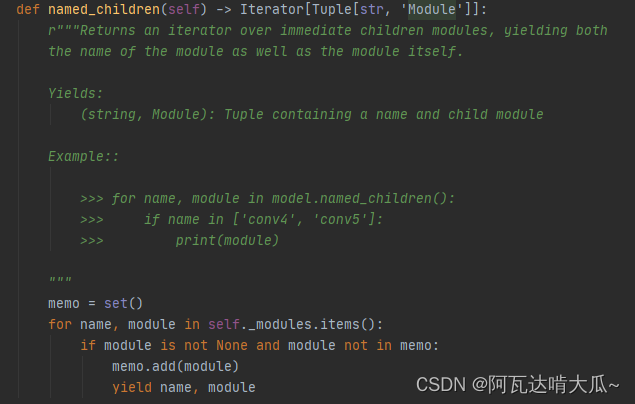
使用源码中提供的Example对自定义的Net进行查看:
for name,mod in model.named_children():
print("输出模块名称:",name)
print("*"*10)
print("输出模块:",mod)
out:
输出模块名称: features
**********
输出模块: Sequential(
(0): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
(5): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
输出模块名称: classifier
**********
输出模块: Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=128, out_features=10, bias=True)
可以看到输出的name是Net中定义的self的name,mod对应的是Sequential对象。
1.2 modules()方法
查看modules()源码如下:大致意思是返回网络中所有模块的迭代器,重复的模块只返回一次。
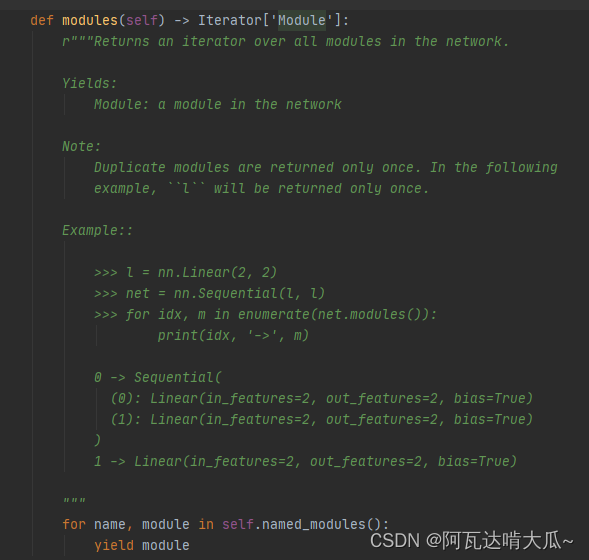
打印出来看一下该方法的具体返回值:
for idx, m in enumerate(model.modules()):
print(idx, '->', m)
out:
0 -> Net(
(features): Sequential(
(0): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
(5): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=128, out_features=10, bias=True)
)
)
1 -> Sequential(
(0): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
(5): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
2 -> Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
3 -> BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
4 -> ReLU(inplace=True)
5 -> MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
6 -> Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
7 -> BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
8 -> ReLU(inplace=True)
9 -> MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
10 -> Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=128, out_features=10, bias=True)
)
11 -> Linear(in_features=576, out_features=128, bias=True)
12 -> ReLU(inplace=True)
13 -> Dropout(p=0.5, inplace=False)
14 -> Linear(in_features=128, out_features=10, bias=True)
可以看到该方打印了Net中的所有模块以及其下的子模块,即遍历模型的所有子层,所有子层即指nn.Module子类,在本文的例子中,Net(), features(), classifier(),以及nn.xxx构成的卷积,池化,ReLU, Linear, BN, Dropout等都是nn.Module子类,也就是model.modules()会迭代的遍历它们所有对象。
1.3 named_modules()方法
该方法与modules()的功能一样,返回所有模块以及旗下子模块,不过会多返回一个名称 ,具体如下
for name ,mod in model.named_modules():
print("打印名称:",name)
print("*"*20)
print("打印迭代器:",mod)
out:
打印名称:
********************
打印迭代器: Net(
(features): Sequential(
(0): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
(5): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=128, out_features=10, bias=True)
)
)
打印名称: features
********************
打印迭代器: Sequential(
(0): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
(5): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
打印名称: features.0
********************
打印迭代器: Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
打印名称: features.1
********************
打印迭代器: BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
打印名称: features.2
********************
打印迭代器: ReLU(inplace=True)
打印名称: features.3
********************
打印迭代器: MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
打印名称: features.4
********************
打印迭代器: Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
打印名称: features.5
********************
打印迭代器: BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
打印名称: features.6
********************
打印迭代器: ReLU(inplace=True)
打印名称: features.7
********************
打印迭代器: MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
打印名称: classifier
********************
打印迭代器: Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=128, out_features=10, bias=True)
)
打印名称: classifier.0
********************
打印迭代器: Linear(in_features=576, out_features=128, bias=True)
打印名称: classifier.1
********************
打印迭代器: ReLU(inplace=True)
打印名称: classifier.2
********************
打印迭代器: Dropout(p=0.5, inplace=False)
打印名称: classifier.3
********************
打印迭代器: Linear(in_features=128, out_features=10, bias=True)
1.4 parameters()参数
查看源码解释:返回模块参数上的迭代器。注意:recurse(bool):如果为True,则生成此模块和所有子模块的参数。
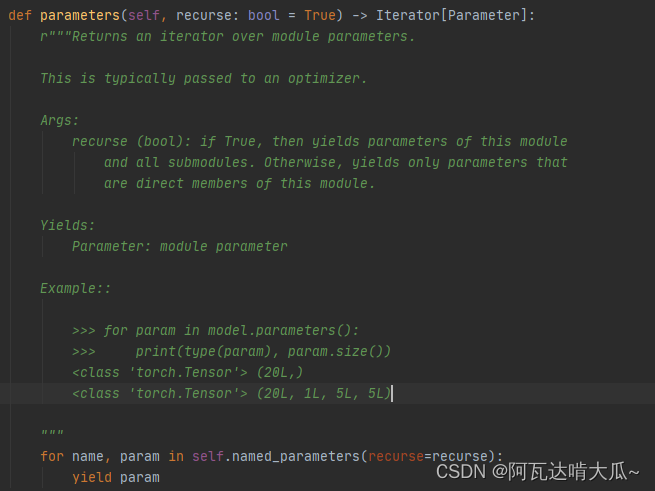
使用Example例子打印Net中的情况:
for para in model.parameters():
print(para.shape)
该方法并未打印出是哪个方法的参数。
out:
torch.Size([6, 3, 3, 3])
torch.Size([6])
torch.Size([6])
torch.Size([6])
torch.Size([9, 6, 3, 3])
torch.Size([9])
torch.Size([9])
torch.Size([9])
torch.Size([128, 576])
torch.Size([128])
torch.Size([10, 128])
torch.Size([10])
1.5 named_parameters()
该方法与parameters()方法一致,但是可以打印出具体参数层的名称,看起来更直观一些
for name,para in model.named_parameters():
print("name:",name)
print("para.shape:",para.shape)
out>>
name: features.0.weight
para.shape: torch.Size([6, 3, 3, 3])
name: features.0.bias
para.shape: torch.Size([6])
name: features.1.weight
para.shape: torch.Size([6])
name: features.1.bias
para.shape: torch.Size([6])
name: features.4.weight
para.shape: torch.Size([9, 6, 3, 3])
name: features.4.bias
para.shape: torch.Size([9])
name: features.5.weight
para.shape: torch.Size([9])
name: features.5.bias
para.shape: torch.Size([9])
name: classifier.0.weight
para.shape: torch.Size([128, 576])
name: classifier.0.bias
para.shape: torch.Size([128])
name: classifier.3.weight
para.shape: torch.Size([10, 128])
name: classifier.3.bias
para.shape: torch.Size([10])
1.6 state_dict()
该方法返回包含模块整体状态的字典,包括参数信息,参数名称。
以构建的Net作为实例展示如下:
# 查看其参数名称:
model.state_dict().keys()
out:
odict_keys(['features.0.weight', 'features.0.bias', 'features.1.weight', 'features.1.bias', 'features.1.running_mean', 'features.1.running_var', 'features.1.num_batches_tracked', 'features.4.weight', 'features.4.bias', 'features.5.weight', 'features.5.bias', 'features.5.running_mean', 'features.5.running_var', 'features.5.num_batches_tracked', 'classifier.0.weight', 'classifier.0.bias', 'classifier.3.weight', 'classifier.3.bias'])















 3460
3460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









