







仲裁者:弥合二进制程序漏洞发现中的静态和动态鸿沟
项目地址
https://github.com/jkrshnmenon/arbiter
1.论文思维导图

2.论文详解
2.1 摘要
尽管当前最先进二进制程序分析方法在漏洞发现的方面是有效的,但是它们受到准确性和可扩展性之间固有的权衡的限制。在本文中,我们确定了一组可以辅助静态和动态漏洞检测技术的漏洞属性,提高了前者的精确度和后者的可扩展性。通过仔细整合静态和动态技术,我们可以检测出现实世界程序中大规模表现出这些属性的漏洞。
我们实现了我们的技术,在二进制代码分析方面取得了一些进展,并创建了一个名为
ARBITER的原型。我们通过对四个常见漏洞类别的大规模评估来证明我们方法的有效性:CWE-131(缓冲区大小的错误计算)、CWE-252(未检查的返回值)、CWE-134(未控制的格式字符串)和CWE-337(伪随机数生成器中的可预测种子)。我们在Ubuntu存储库中超过76,516个x86-64二进制文件上评估了我们的方法,并发现了新的漏洞,包括一个在编译期间插入到程序中的缺陷
2.2 贡献
- 我们确定了一组特定的漏洞属性,允许有效结合静态分析和动态分析,尤其是
DSE(动态符号执行),以在保持可扩展性的同时实现精确性- 我们开发了ARBITER,一个结合静态分析和
DSE来识别bug的框架。ARBITER的运行不需要任何源代码或构建系统,并且包括对静态和动态技术的新颖改进。在ARBITER中创建新漏洞类别的规范成本很低- 我们对
ARBITER进行了大规模评估,分析了76,516个二进制文件中的四个错误类别
2.3 实现过程
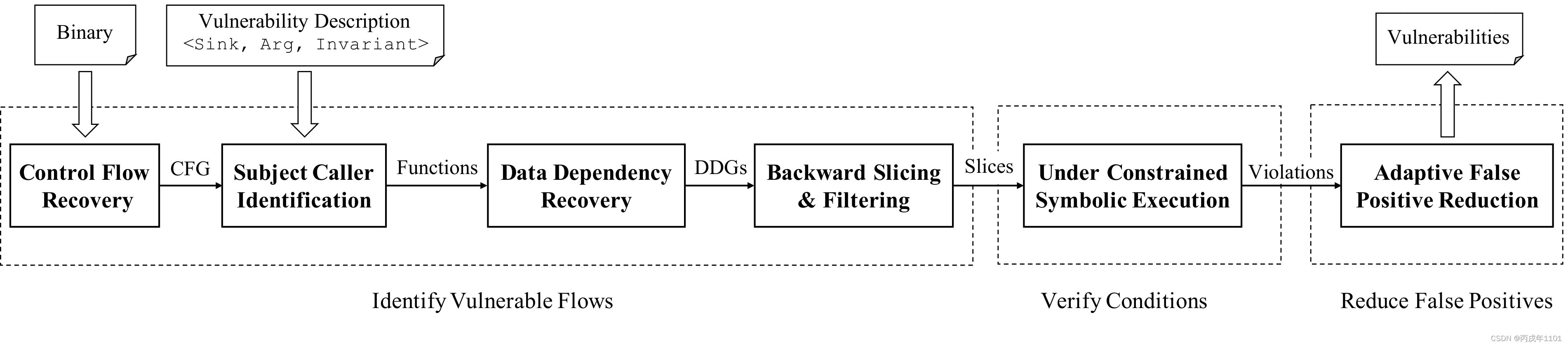
仲裁者架构主要如图所示,其中
- 输入数据:
- 二进制文件(
Binary):为了分析二进制代码,仲裁器需要输入有问题的二进制代码,哪怕该二进制文件不可运行 - 漏洞描述(
Vulnerability Description):PC 漏洞有某些属性,这些属性作为漏洞描述(VD)提供给仲裁者- 数据流敏感漏洞:对数据流敏感的漏洞可以通过推理输入源和漏洞接收器之间的数据流来发现
- 容易识别的源或汇:漏洞源决定数据流跟踪的开始,漏洞接收器决定数据流跟踪的终止。识别许多漏洞类别的源和接收需要关于整个二进制文件的精确别名信息
- 控制流决定的别名:跟踪数据流几乎总是涉及恢复别名信息,这需要对目标进行昂贵的全二进制分析
- 二进制文件(
- 识别易受攻击的流(
Identfiy Vulnerable Flows):仲裁器使用多种技术的组合来识别可能满足二进制文件中VD的流;首先在恢复的控制流图上搜索VD主题,然后查询计算的数据依赖图,以识别与提供的VD匹配的这些主题之间的数据流 - 验证脆弱性条件(
Verify Conditions):仲裁器使用欠约束符号(UCSE)来执行提供的路径并恢复源和接收器之间的符号数据关系,如果这种关系满足所提供的 VD 中描述的约束,则该路劲被提升到下一步 - 减少基于上下文的误报(
Reduce False Positives):仲裁器从检测到的具有较高上下文敏感度的接收器中计算一个切片,并使用符号执行它以识别缺失的约束。通过在这一步提高上下文敏感度,ARBITER用可伸缩性换取了精确性。如果仲裁者不能识别任何约束来使现存的漏洞候选项无效,则该候选项将作为警报报告给分析师
2.3.1 识别易受攻击的流
ARBITER将CFG和VD作为输入,构建并查询与VD中指定的漏洞源/汇相关的数据依赖图(DDG)
-
静态数据流跟踪技术——
SymDFT:ARBITER通过使用一种新的静态数据流跟踪技术(SymDFT)来实现精确地数据流跟踪。给定任何起始点(通常是函数的开始),SymDFT以上下文敏感和路径敏感的方式静态模拟基本块,并对寄存器、内存(作为一个平面内存模型,覆盖全局区域、堆栈和堆)、系统调用以及对文件描述符的访问(这捕获对文件和网络套接字的访问)进行建模。SymDFT通过使用符号域,即在分析过程中跟踪未知变量和符号表达式,实现了建模数据的高精度该技术关键的设计决策:
- 遍历策略:以拓扑顺序遍历函数内部的基本快,一旦遇到被调用者的调用,
SymDFT将分析被调用者函数,并使用返回的抽象状态的返回站点进行分析 - 分支策略:结合了支持强制执行和全面执行的思想:在每个分支点,它分叉抽象状态并跟随所有分支而不考虑分支可行性
- 状态合并策略:同一二进制地址的抽象状态被立即合并 ,其中每个状态被分配一个合并标签,并且具体和符号表达式被合并成
if-then-else表达式的形式,其中合并标签是条件 - 终止:(1)当调用深度超过两个函数时,
SymDFT伪造一个抽象返回值,而不是分析被调用方 (2)每个循环最多被访问3次
- 遍历策略:以拓扑顺序遍历函数内部的基本快,一旦遇到被调用者的调用,
-
构建
DDG和提取流量:首先识别CFG上的源或接收器,并识别相关功能(Subject Caller Identification);然后,仲裁器为包含每个源或接收器的函数构建一个DDG;当VD中只描述了汇点时,ARBITER为发现汇点的每个函数(和被调用者)构建一个DDG,而不是构建一个覆盖所有潜在输入源的完整程序DDG(Data Dependency Recovery)
2.3.2 验证脆弱性条件
- 欠约束符号执行(
under-constrained symbolic execution):UCSE允许任意函数的符号化执行,而无需初始化数据结构或建模环境。在不完整状态下不可用的所有值(例如,缺少参数和来自被调用者的未知返回值)都被认为是欠约束变量。当一个欠约束的变量被用作指针时,UCSE会将该变量初始化为一个指针,指向一个新分配的内存区域,其大小与指针类型指定的大小相同。如果变量不用作指针,欠约束变量将会受到符号约束的约束 UCSE在ARBITER中的两个挑战和解决方案- 影子内存分配:由于缺少类型信息,
UCSE不知道要分配的内存区域的大小,在仲裁器中,UCSE并不决定为欠约束指针分配的内存区域的大小。相反,我们假设每个欠约束指针都指向一个完全与堆栈、堆和其他影子内存区域隔离的影子内存区域。从欠约束指针派生的所有指针只能用于访问同一个阴影区域 - 添加必要的约束:源代码上的
UCSE依赖于关于变量大小的信息,用来约束指针和发现违规,但是这在二进制代码中是不可用的,并且由于欠约束指针或变量引起某些存储器的访问可能破坏堆栈上或全局区域中的关键数据结构,我们的UCSE积极地向变量和指针添加约束,使得栈上或全局区域中的关键数据不能被覆盖
- 影子内存分配:由于缺少类型信息,
- 收集数据约束流:对于每个候选漏洞数据流,仲裁器在程序片上运行
UCSE,该程序片是通过从每个接收器遍历CFG而生成的(Backward Slicing & Filtering)。在接收端,仲裁器提取代表源和接收端之间的数据相关性的符号表达式,并收集路径谓词(约束)。如果对应于VD的约束是可满足的,则仲裁器报告潜在的VD违规
2.3.3 自适应误报减少
尽管在UCSE步骤中对候选易受攻击的数据流进行了可满足性过滤,但是上下文的缺乏仍然留下了大量的误报。因为仲裁器在函数内部工作,所以它没有可能影响函数的控制流和数据流的上下文敏感信息。一旦在较小的上下文中检测到漏洞,我们就通过增加分析上下文来过滤误报**(Adaptive False Positive Reduction)**。仲裁器递归地识别当前函数的所有调用点,并在调用帧的上下文中进行分析。仲裁器递归地继续逐调用方扩展上下文调用方,直到达到预定义的递归限制
分析师可以根据报告的数量和时间限制来选择递归限制,因为每增加一个上下文都会导致分析时间呈指数增长。我们的结果表明,每一个上下文扩展步骤都会将警报减少大约一半,并且三个减少步骤充分减少了假阳性,从而可以手动验证结果
















 2325
2325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











