






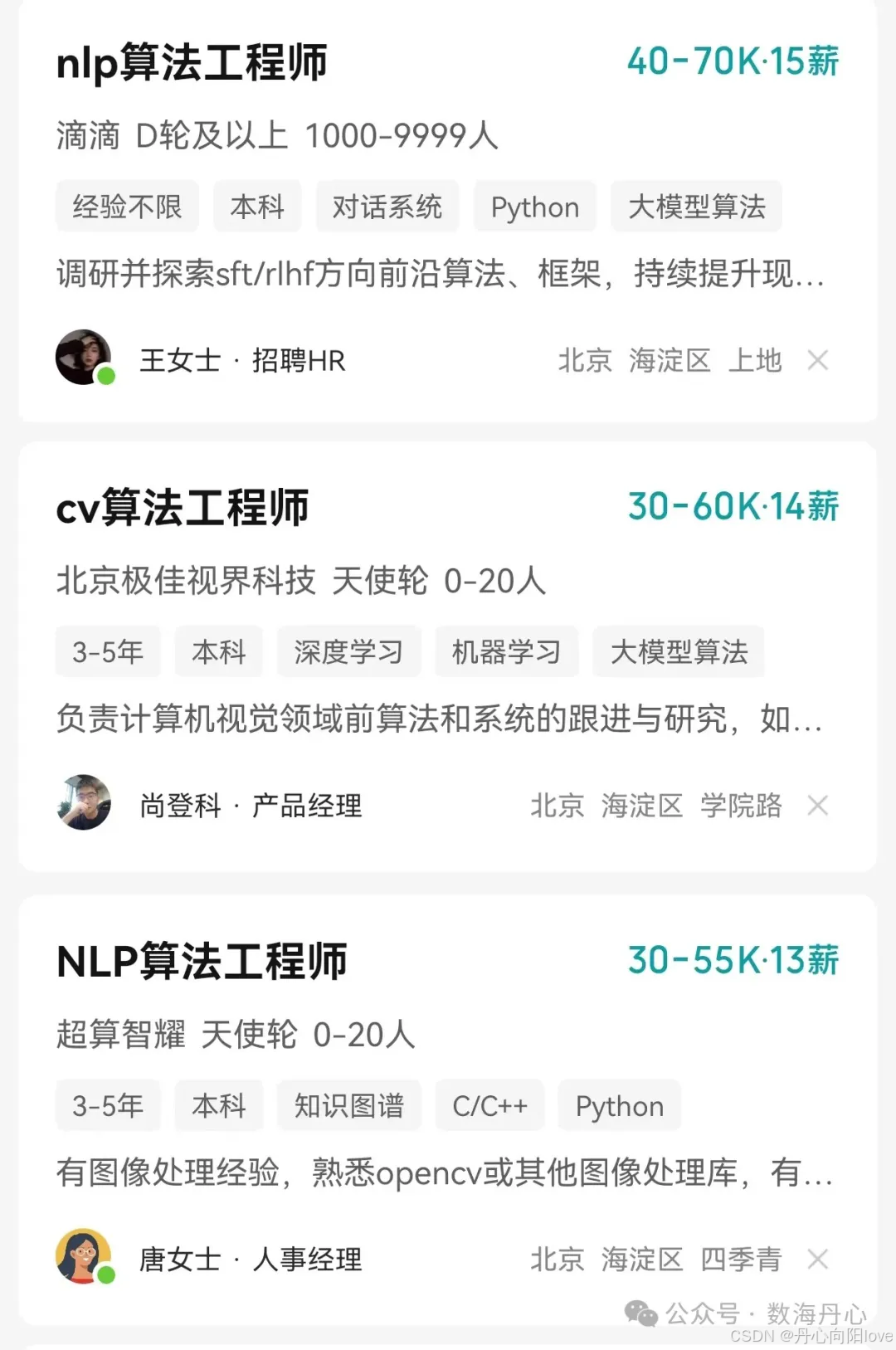
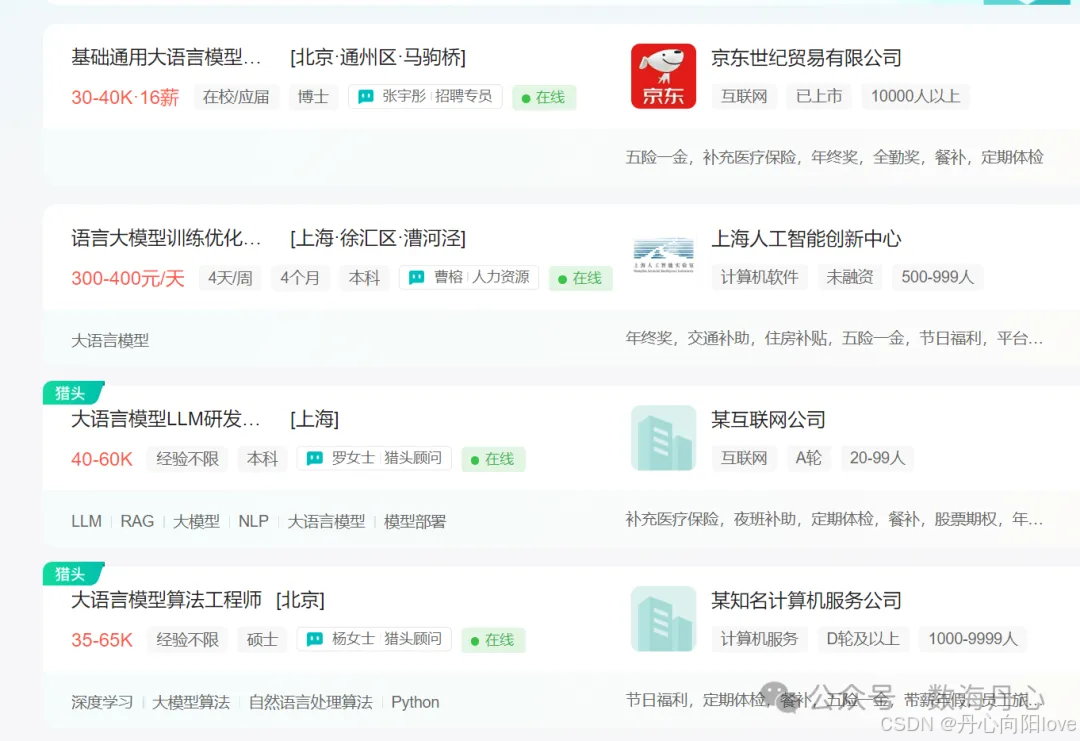
2025年,随着DeepSeek的持续火爆,AI行业人才市场持续升温,尤其是大语言模型微调算法工程师的薪资水平一路飙升。根据科锐国际发布的《2025人才市场洞察及薪酬指南》报告,大模型算法工程师的年薪已经高达50万至200万人民币。这一薪资水平不仅反映了市场对高端AI人才的迫切需求,也预示着大语言模型微调技术在行业中的重要性。
大模型微调实战:从“通才”到“专家”的转变
在AI技术飞速发展的今天,大模型已经成为了我们生活和工作中不可或缺的工具。然而,尽管这些模型在预训练阶段已经学习了海量的知识,但在实际应用中,我们往往需要它们在特定领域表现得更加专业。这就是大模型微调的意义所在——让模型从“通才”变成某个领域的“专家”。
一、AI微调:打工人逆袭的原子弹
什么是大模型微调?
微调就像给一个“学霸”补课,让它从“通才”变成某个领域的“专家”。以医学数据为例,假设你有一个很聪明的朋友,他读过全世界的书(相当于大模型的预训练阶段),能和你聊历史、科学、文学等各种话题。但如果你需要他帮你看医学报告,虽然他懂一些基础知识,但可能不够专业。这时候,你给他一堆医学书籍和病例,让他专门学习这方面的知识(这就是微调),他就会变得更擅长医疗领域的问题。
“就像给学霸报补习班:通才秒变专科状元!”
通才阶段:大模型读过千万本书(预训练),能聊历史、写诗、编代码
专科强化:投喂500份医学报告(微调),秒变三甲级"数字医生"
**预训练:**在海量通用数据(如书籍、网页)上学习语言通用特征。
**微调:**在特定任务数据(如医学报告)上调整模型参数,使其成为领域专家。
关键方法论
参数高效微调(PEFT):仅调整部分参数(如LoRA、Adapter),显存占用减少60-70%,适合消费级GPU。
复杂思维链(CoT):通过分步推理数据增强模型深度推理能力,显著提升复杂任务表现。
二、 DeepSeek微调实战:3小时造"病历分析专家"
**微调前:**模型的回答可能只是基于通用知识,缺乏深度和专业性。

**微调后:**模型的回答更加精准,能够针对特定领域的问题给出专业的解答。例如,在医学领域,微调后的模型可以更准确地解读医学报告,提供专业的建议。

三、当前尝试过的硬件配置
**显卡:**NVIDIA GeForce RTX 4060
**CPU:**Intel Core i7-13700H
**内存:**16G(因为是家庭电脑,日常状态是8.8/15.7 GB)
四、微调工作
(1)数据集准备
本文数据集来源是魔搭社区的medical-o1-reasoning-SFT。数据集格式是:在DeepSeek的蒸馏模型微调过程中,数据集中引入Complex_CoT(复杂思维链)是关键设计差异。若仅使用基础问答对进行训练,模型将难以充分习得深度推理能力,导致最终性能显著低于预期水平。这一特性与常规大模型微调的数据要求存在本质区别。
数据集选择
使用魔搭社区medical-o1-reasoning-SFT等高质量领域数据集
格式转换
将原始数据拼接为"诊断问题:{Question}\n详细分析:{Complex_CoT}\n答案:\n{Response}"格式,确保输入符合模型要求
数据预处理函数
def process_data(tokenizer):
dataset = load_dataset("json", data_files=data_path, split="train[:1500]")
def format_example(example):
instruction = f"诊断问题:{example['Question']}\n详细分析:{example['Complex_CoT']}"
inputs = tokenizer(
f"{instruction}\n### 答案:\n{example['Response']}<|endoftext|>",
padding="max_length",
truncation=True,
max_length=512,
return_tensors="pt"
)
return {"input_ids": inputs["input_ids"].squeeze(0), "attention_mask": inputs["attention_mask"].squeeze(0)}
return dataset.map(format_example, remove_columns=dataset.column_names)
2. 模型配置
LoRA微调:
peft_config = LoraConfig(
r=16, # 低秩矩阵维度
lora_alpha=32, # 影响强度系数
target_modules=["q_proj", "v_proj"], # 调整注意力模块
lora_dropout=0.05 # 防止过拟合
)
作用:仅训练原模型0.1%的参数,显存占用降低至4GB以下
3. 训练参数
training_args = TrainingArguments(
per_device_train_batch_size=2, # 单卡显存优化
gradient_accumulation_steps=4, # 等效batch_size=8
learning_rate=3e-4, # 初始学习率
fp16=True, # 混合精度加速
num_train_epochs=3 # 总轮次
)
优化策略:通过梯度累积模拟大batch_size,同时保持显存占用可控
4. 训练流程
数据加载与预处理
dataset = load_dataset("json", data_files=data_path)
dataset = dataset.map(format_example, remove_columns=dataset.column_names)
模型初始化
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map={"": device}
)
model = get_peft_model(model, peft_config)
训练器配置
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
callbacks=[LossCallback()]
)
关键点:使用TrainerCallback实时记录损失曲线,便于监控训练状态
完整代码
导入必要的库
pip install torch transformers peft datasets matplotlib accelerate safetensors
import torch
import matplotlib.pyplot as plt
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
TrainerCallback
)
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
import os
配置路径(根据实际路径修改)
model_path = r"你的模型路径" # 模型路径
data_path = r"你的数据集路径" # 数据集路径
output_path = r"你的保存微调后的模型路径" # 微调后模型保存路径
强制使用GPU
assert torch.cuda.is_available(), "必须使用GPU进行训练!"
device = torch.device("cuda")
自定义回调记录Loss
class LossCallback(TrainerCallback):
def __init__(self):
self.losses = []
def on_log(self, args, state, control, logs=None, **kwargs):
if "loss" in logs:
self.losses.append(logs["loss"])
数据预处理函数
def process_data(tokenizer):
dataset = load_dataset("json", data_files=data_path, split="train[:1500]")
def format_example(example):
instruction = f"诊断问题:{example['Question']}\n详细分析:{example['Complex_CoT']}"
inputs = tokenizer(
f"{instruction}\n### 答案:\n{example['Response']}<|endoftext|>",
padding="max_length",
truncation=True,
max_length=512,
return_tensors="pt"
)
return {"input_ids": inputs["input_ids"].squeeze(0), "attention_mask": inputs["attention_mask"].squeeze(0)}
return dataset.map(format_example, remove_columns=dataset.column_names)
LoRA配置
peft_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
训练参数配置
training_args = TrainingArguments(
output_dir=output_path,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs=3,
learning_rate=3e-4,
fp16=True,
logging_steps=20,
save_strategy="no",
report_to="none",
optim="adamw_torch",
no_cuda=False,
dataloader_pin_memory=False,
remove_unused_columns=False
)
def main():
os.makedirs(output_path, exist_ok=True)
tokenizer = AutoTokenizer.from_pretrained(model_path)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map={"": device}
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
dataset = process_data(tokenizer)
loss_callback = LossCallback()
def data_collator(data):
batch = {
"input_ids": torch.stack([torch.tensor(d["input_ids"]) for d in data]).to(device),
"attention_mask": torch.stack([torch.tensor(d["attention_mask"]) for d in data]).to(device),
"labels": torch.stack([torch.tensor(d["input_ids"]) for d in data]).to(device)
}
return batch
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
callbacks=[loss_callback]
)
print("开始训练...")
trainer.train()
trainer.model.save_pretrained(output_path)
print(f"模型已保存至:{output_path}")
plt.figure(figsize=(10, 6))
plt.plot(loss_callback.losses)
plt.title("Training Loss Curve")
plt.xlabel("Steps")
plt.ylabel("Loss")
plt.savefig(os.path.join(output_path, "loss_curve.png"))
print("Loss曲线已保存")
if __name__ == "__main__":
main()
五、代码优化建议
数据增强:通过回译、同义词替换等方式扩充数据集,提升模型泛化能力
正则化策略:添加权重衰减(weight_decay=0.01)和早停机制(patience=3)防止过拟合
混合精度优化:使用torch.cuda.amp动态调整精度,显存占用可再降20%
六、当前技术趋势
多任务微调:通过共享底层参数+任务专属头,实现医疗问答与诊断建议的联合优化
分布式训练:利用多卡并行加速微调,如4×RTX 4060可在8小时内完成百亿参数模型微调
轻量化架构:探索LoRA-T5、TinyLoRA等轻量级微调方案,适配边缘设备部署
关注公众号后台发送048免费获取deepseek实用干货

















 77
77

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









