







1、KNN算法例子

①首先找到未分类的点
②计算该点与其他所有点的距离
③找出离该分类点最近的k个点,根据这k个点中类别最多的类别判定这个类别。
注:一般来说k取奇数,这样分类时更好划分类别。
例1:irias花的分类
# 读取相应的库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 读取数据 X, y
iris = datasets.load_iris()
X = iris.data
y = iris.target
print (X)
print(y)
数据集:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
[5.4 3.7 1.5 0.2]
[4.8 3.4 1.6 0.2]
[4.8 3. 1.4 0.1]
[4.3 3. 1.1 0.1]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
[5.4 3.9 1.3 0.4]
[5.1 3.5 1.4 0.3]
[5.7 3.8 1.7 0.3]
[5.1 3.8 1.5 0.3]
[5.4 3.4 1.7 0.2]
[5.1 3.7 1.5 0.4]
[4.6 3.6 1. 0.2]
[5.1 3.3 1.7 0.5]
[4.8 3.4 1.9 0.2]
[5. 3. 1.6 0.2]
[5. 3.4 1.6 0.4]
[5.2 3.5 1.5 0.2]
[5.2 3.4 1.4 0.2]
[4.7 3.2 1.6 0.2]
[4.8 3.1 1.6 0.2]
[5.4 3.4 1.5 0.4]
[5.2 4.1 1.5 0.1]
[5.5 4.2 1.4 0.2]
[4.9 3.1 1.5 0.2]
标签:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
②划分与训练数据
# 把数据分成训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2003)
#注:x_train,y_trian为训练集的数据集和标签集,X_test和y_test为测试集的数据集和标签集
# 构建KNN模型, K值为3、 并做训练
clf = KNeighborsClassifier(n_neighbors=3)
#用x_train,y_trian训练模型
clf.fit(X_train, y_train)
# 计算准确率
from sklearn.metrics import accuracy_score
#如果预测的x_test==y_test返回True,否则返回False,计算预测正确的个数
correct = np.count_nonzero((clf.predict(X_test)==y_test)==True)
print ("Accuracy is: %.3f" %(correct/len(X_test)))
结果:
Accuracy is: 0.921
2、手动实现KNN算法
让我们回顾一下KNN算法的步骤:
①将一个物体表示成向量的形式
②给每个物体打上标签
③计算物体之间的距离或者相似度
④选择合适的k
①将物体表示成向量也叫特征工程

正如上面图中所示,数据分为结构化数据和非结构化数据,诸如常见数据集中的分类信息就是结构化数据,而像图片、音频等数据就是非结构化数据。
例1:利用欧式距离实现KNN
首先欧式距离的公式
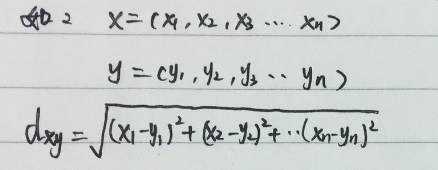
这里先介绍几个函数
①np.argsort(llist1)
计算list1中各个元素的大小并返回各个元素按大小排序的下标的array。
如:
a=[4,2,1,5,6,7,5,9,10]
np.argsort(a)
结果:
array([2, 1, 0, 3, 6, 4, 5, 7, 8], dtype=int64)
②Counter()。 collections包中的计算函数,计算列表各个数出现的概率
③Counter().most_common(num)。统计出现次数最多的前num个数字及次数
如:
count=Counter([1,2,1,2,2,2,3])
print(count)
count_reverse=count.most_common()
print(count_reverse)
结果:
Counter({2: 4, 1: 2, 3: 1})
[(2, 4), (1, 2), (3, 1)]
这里也可以采用sorted的方法解决这个问题,代码可以修改为:
count=Counter([1,2,1,2,2,2,3])
count.items()
count=dict(sorted(count.items(),key=lambda a:a[1],reverse=True))
print(count)
{2: 4, 1: 2, 3: 1}
代码:
from sklearn import datasets
from collections import Counter # 为了做投票
from sklearn.model_selection import train_test_split
import numpy as np
# 导入iris数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2003)
#计算欧式距离
def euc_dis(instance1, instance2):
"""
计算两个样本instance1和instance2之间的欧式距离
instance1: 第一个样本, array型
instance2: 第二个样本, array型
"""
# TODO
dist = np.sqrt(sum((instance1 - instance2)**2))
return dist
def knn_classify(X, y, testInstance, k):
"""
给定一个测试数据testInstance, 通过KNN算法来预测它的标签。testInstance是测试数据集,代表要检测的单个样本
X: 训练数据的特征
y: 训练数据的标签
testInstance: 测试数据,这里假定一个测试数据 array型
k: 选择多少个neighbors?
注:我们这个函数中testInstance是一个测试数据,如果测试数据是一个数据集的话要在其中加入循环
"""
# TODO 返回testInstance的预测标签 = {0,1,2}
distances = [euc_dis(x, testInstance) for x in X]
kneighbors = np.argsort(distances)[:k]
#注:np.argsort()将返回排名前k个样本的下标
#print(kneighbors)
count = Counter(y[kneighbors])
return count.most_common()[0][0]
# 预测结果。
predictions = [knn_classify(X_train, y_train, data, 3) for data in X_test]
correct = np.count_nonzero((predictions==y_test)==True)
#accuracy_score(y_test, clf.predict(X_test))
print ("Accuracy is: %.3f" %(correct/len(X_test)))
结果:
Accuracy is: 0.921















 2453
2453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









