






语音识别中的Transformer和Conformer(一)
简介
随着端到端语音识别技术的发展,以Transformer、Conformer及其变种为首的模型架构在训练效率和字准率上已经超越传统的又贵又慢又不稳定的 RNN-T架构。
而Transformer算子是整个端到端模型架构的基石,故本文抛砖引玉,从已机器翻译的小demo为例介,绍下Transformer模型的架构流程,进而介绍在WeNent中的Conformer模型架构,为今后的项目开展打好基础
先验知识
Embedding
Embedding顾名思义词嵌入向量,相比于one-hot编码,Embedding将稀疏高维特征向量转换成稠密低维特征向量,更利于深度学习技术的处理
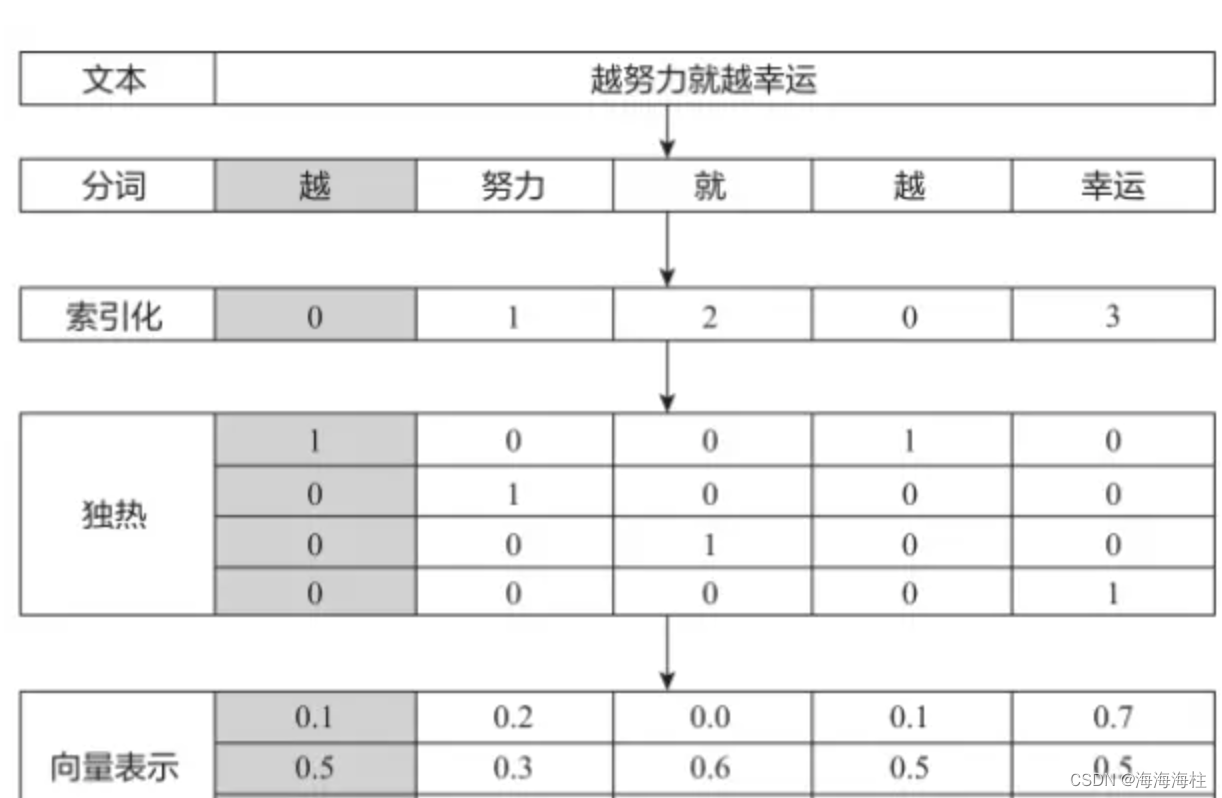
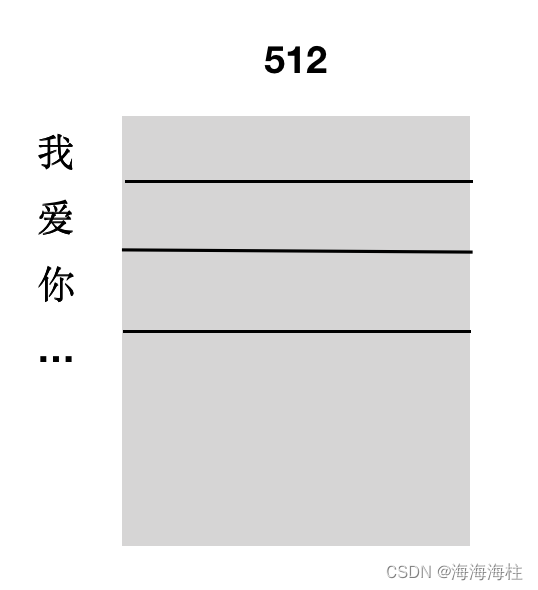
什么是Padding、max_len
max_len
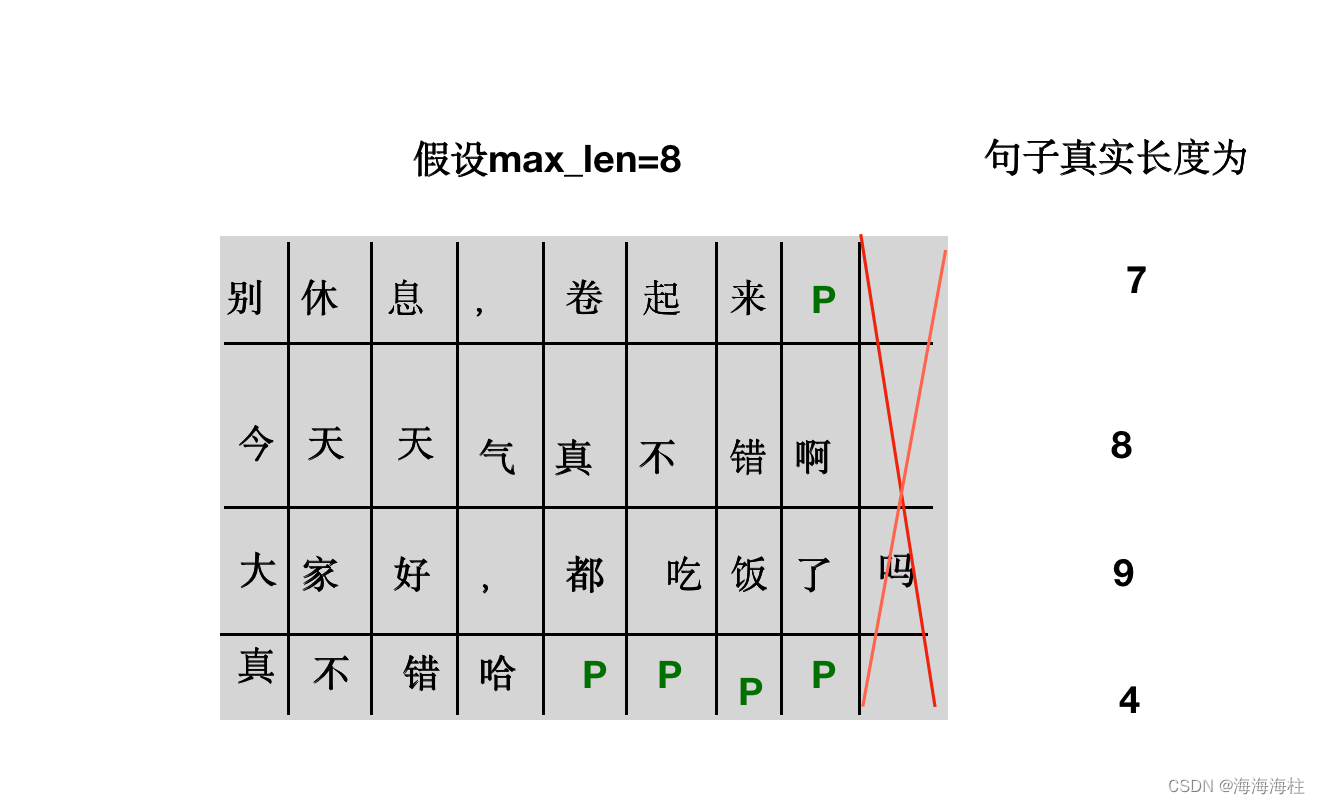
max_len为模型能够输入的最大长度,由于GPU显存有一定限制,所以在训练时候会指定模型能接受最大输入长度max_len,如下图,四句话的长度分别为 7、8、9、4,指定max_len为8,大于8的字符会被干掉
Padding
Padding这个概念非常重要,因为深度学习在训练时候会利用GPU进行并行计算,所以大多参数和数据样本都会采用batch或者矩阵的形式,这就要求样本的列维度需要统一,以nlp为例,大多数送入训练的样本的是不统一的,所以为了统一特征的维度会将不足长度为8的样本,用P符号进行补齐,P符合在代码里用0表示。之后会引入一个MASK概念 非常重要 !!!!,是conformer 和Transformer 的核心,之后的文章都会提到。
注意力机制
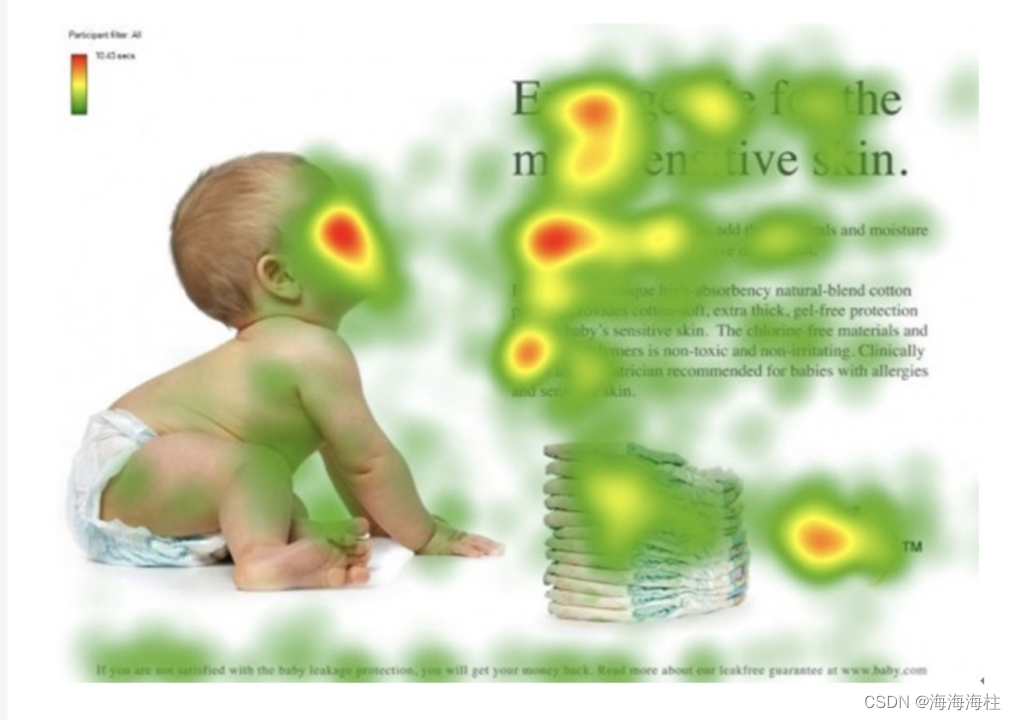
注意力机制的概念为老生常谈了,经典就是下图,注意力机制在深度学习中的概念,就是模仿人在看一个图片的关注点在哪,“横看成岭侧成峰,远近高低各不同 !”
放在nlp里的公式图像:
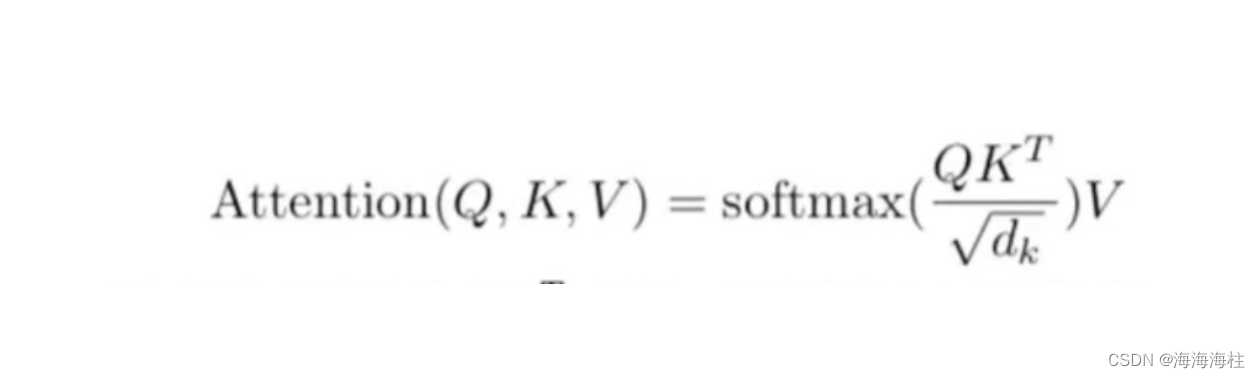
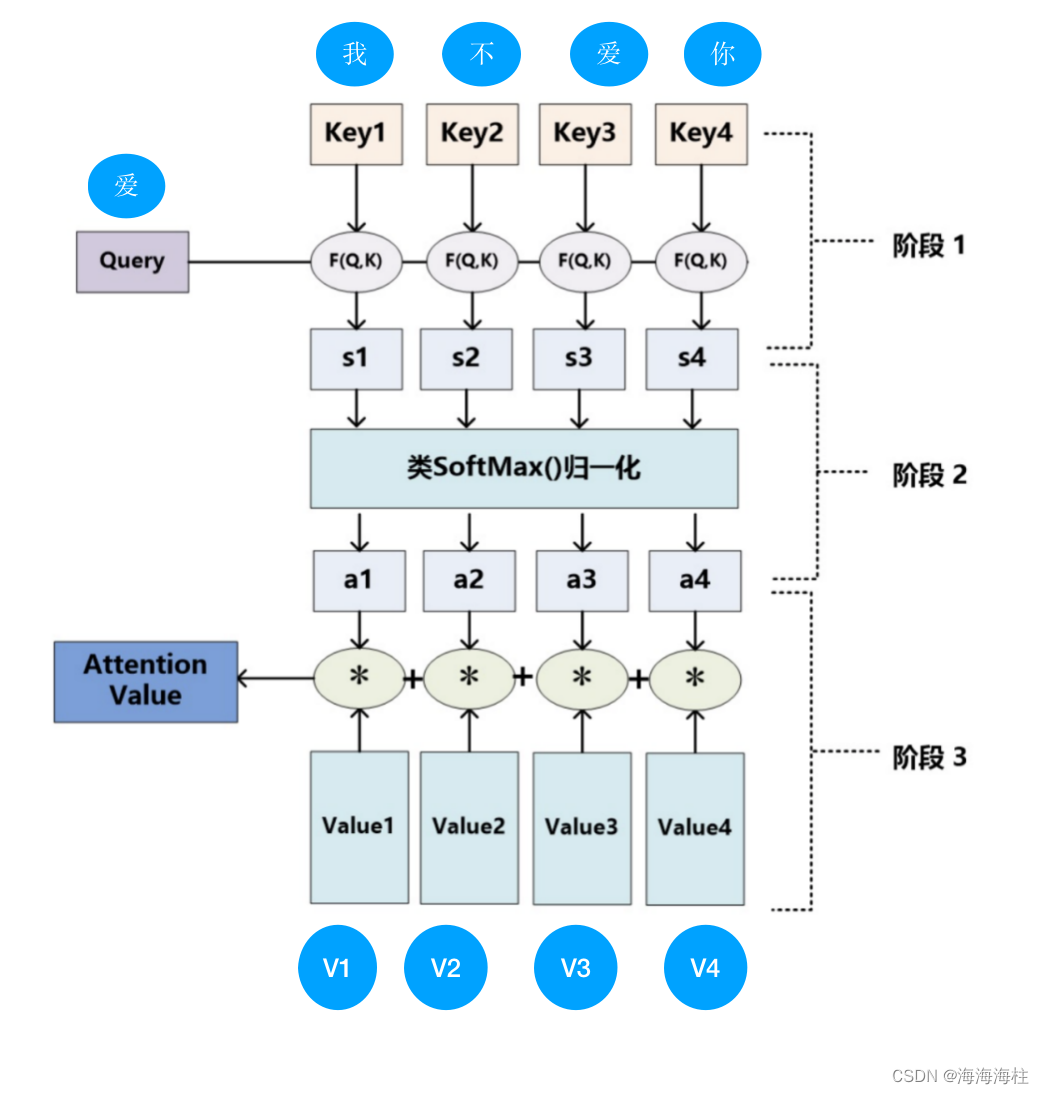
TRM中的注意力
在只有单词向量的情况下,如何获取QKV
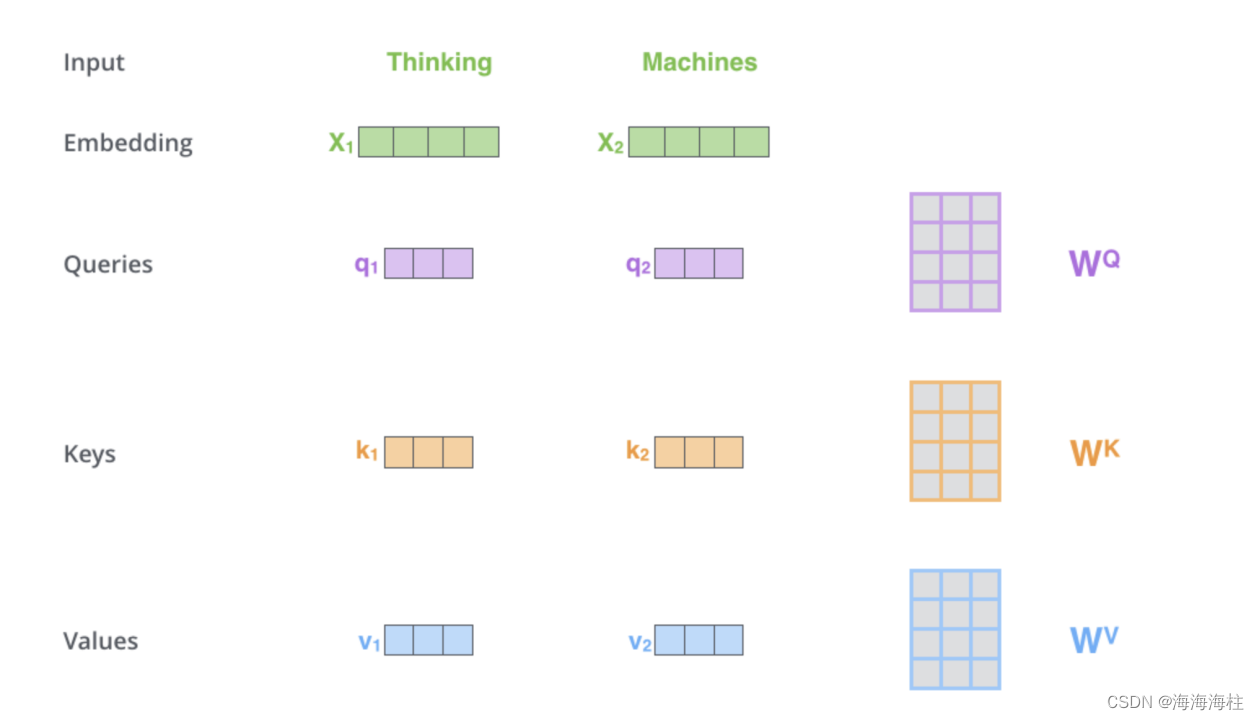
计算QK相似度,得到attention值
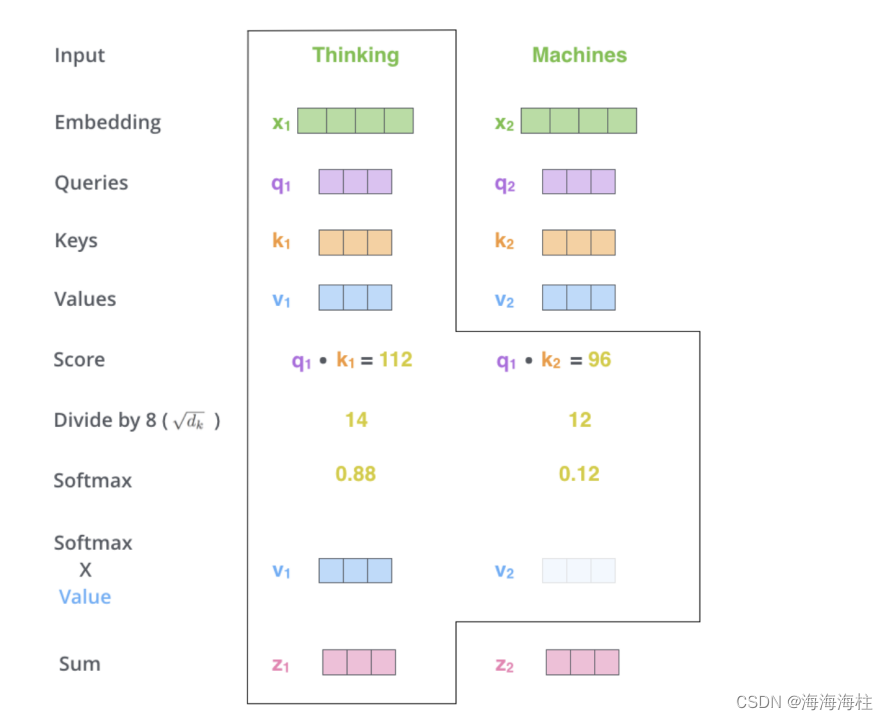
实际代码使用矩阵,方便并行
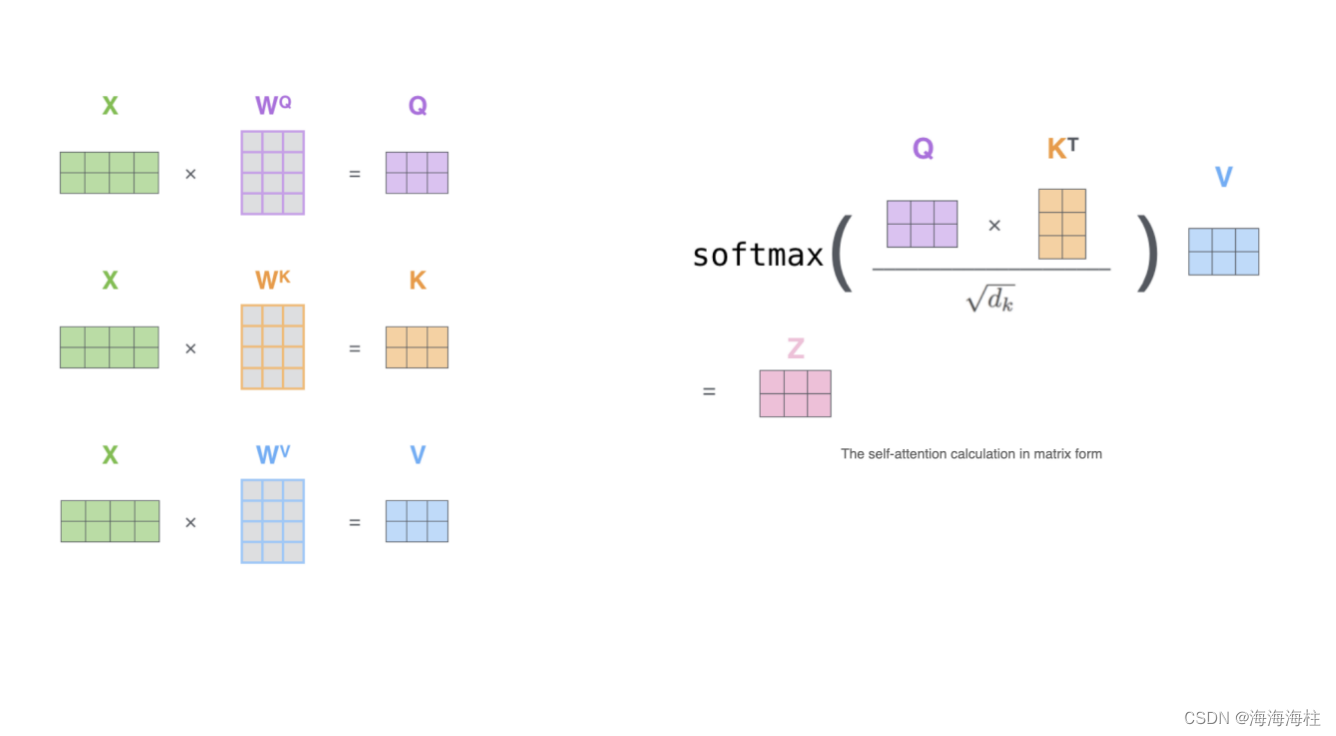
多头注意力机制,如果有8个头,那么就会有八组不同的参数矩阵
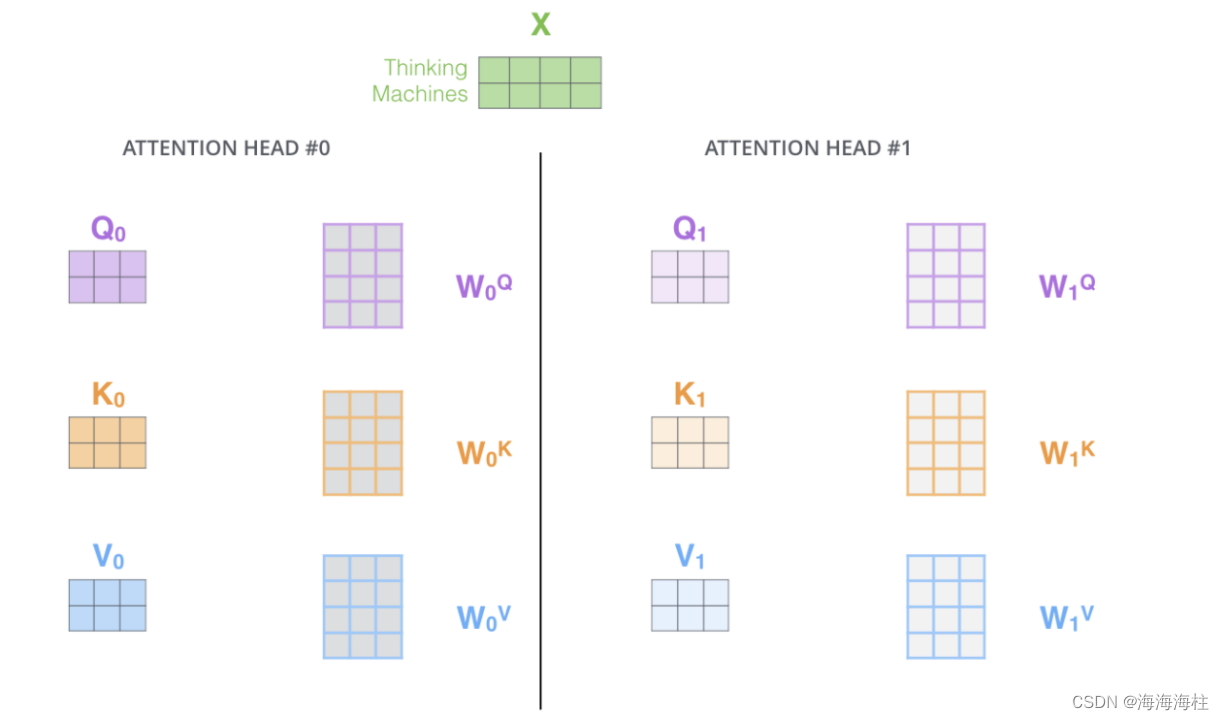
多个头就会有多个输出,需要合在一起输出
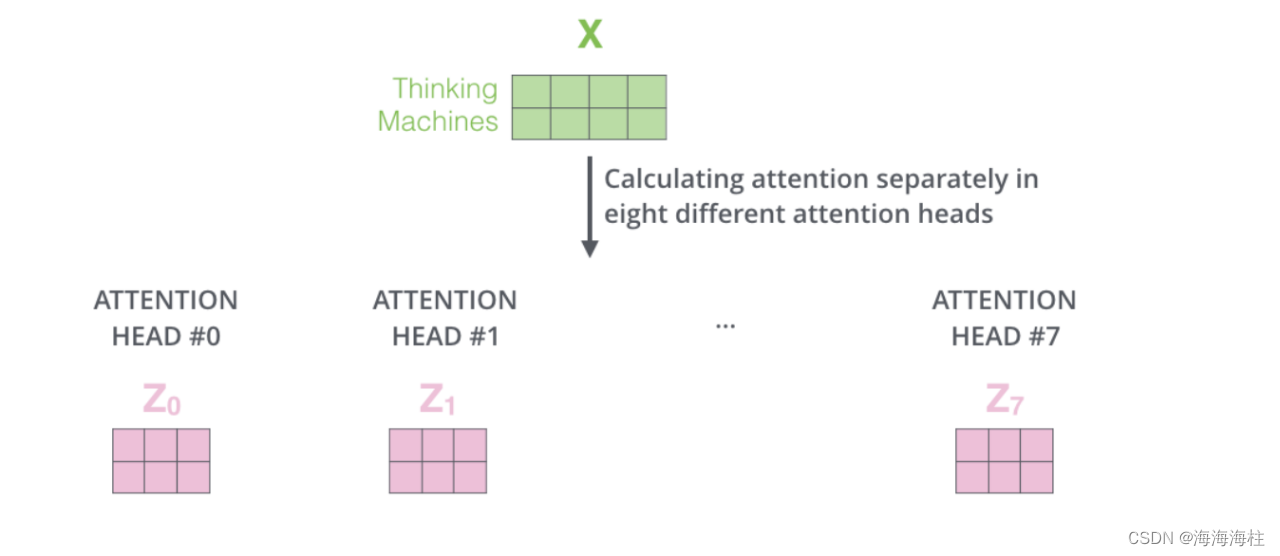
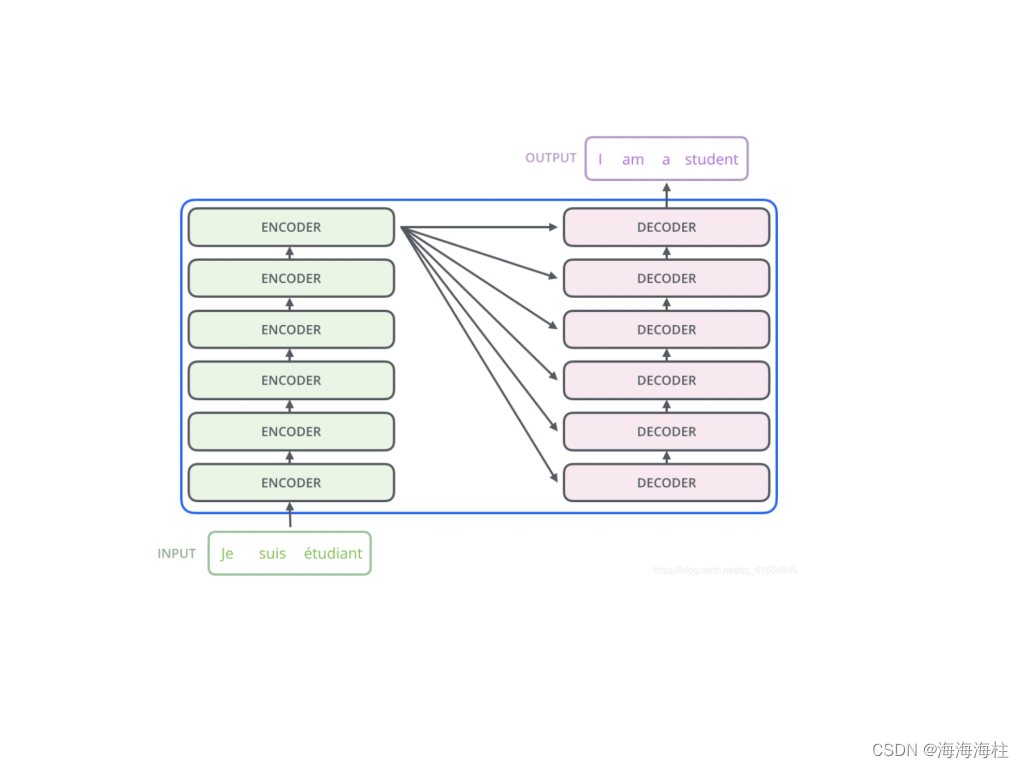
Transformer架构
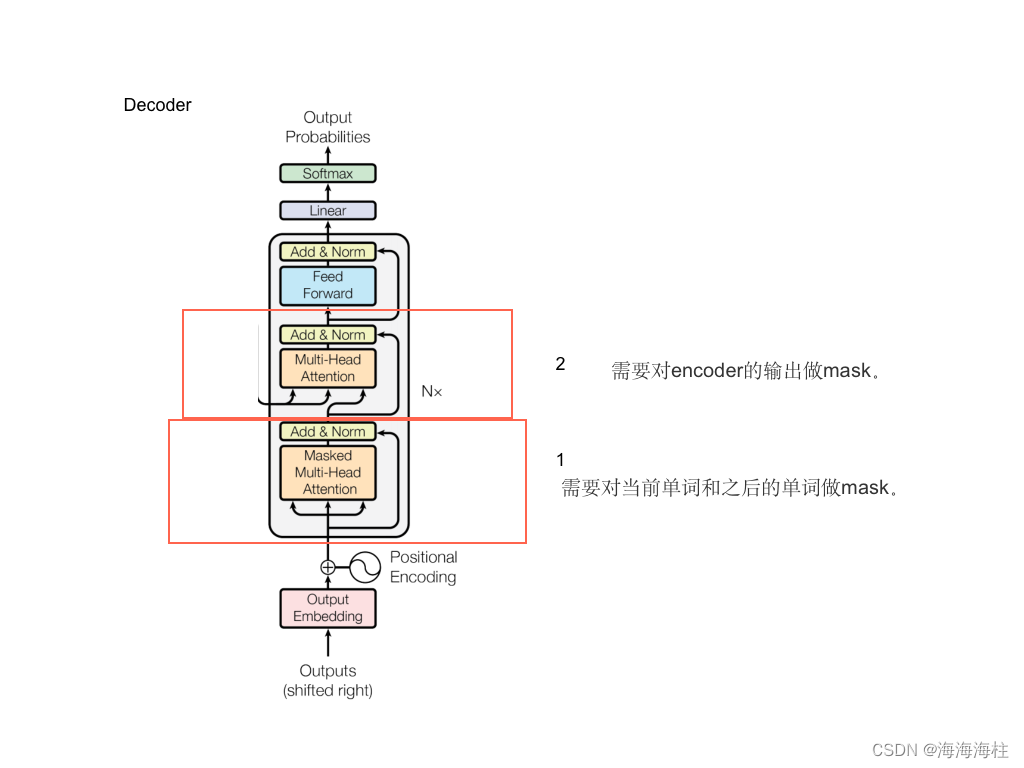
整个Transformer架构主要由编码器-解码器(Encoder-Decoder)架构组成,主要亮点有多头注意力机制(Multi-Head Attention)、位置编码(Positional Encoding)、残差连接、前馈神经网络,其中有三个地方用到了多头注意力机制; 编码器自身的多头注意力机制,解码器自身的MASK多头注意力机制和编码器-解码器的交互多头注意力机制
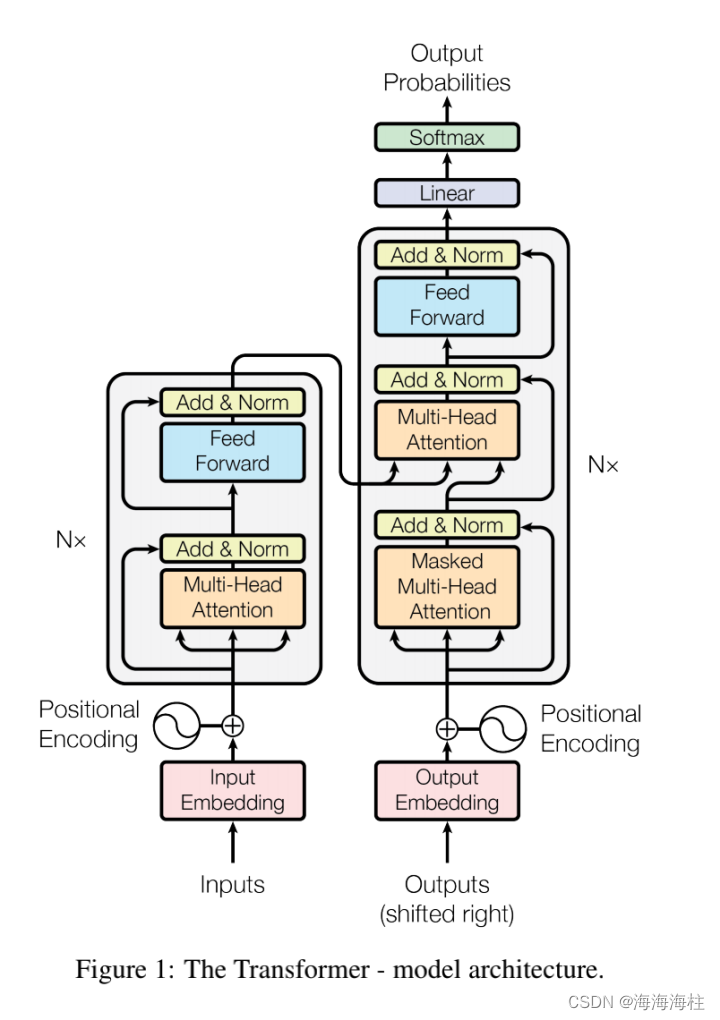
工作原理上大致如下:
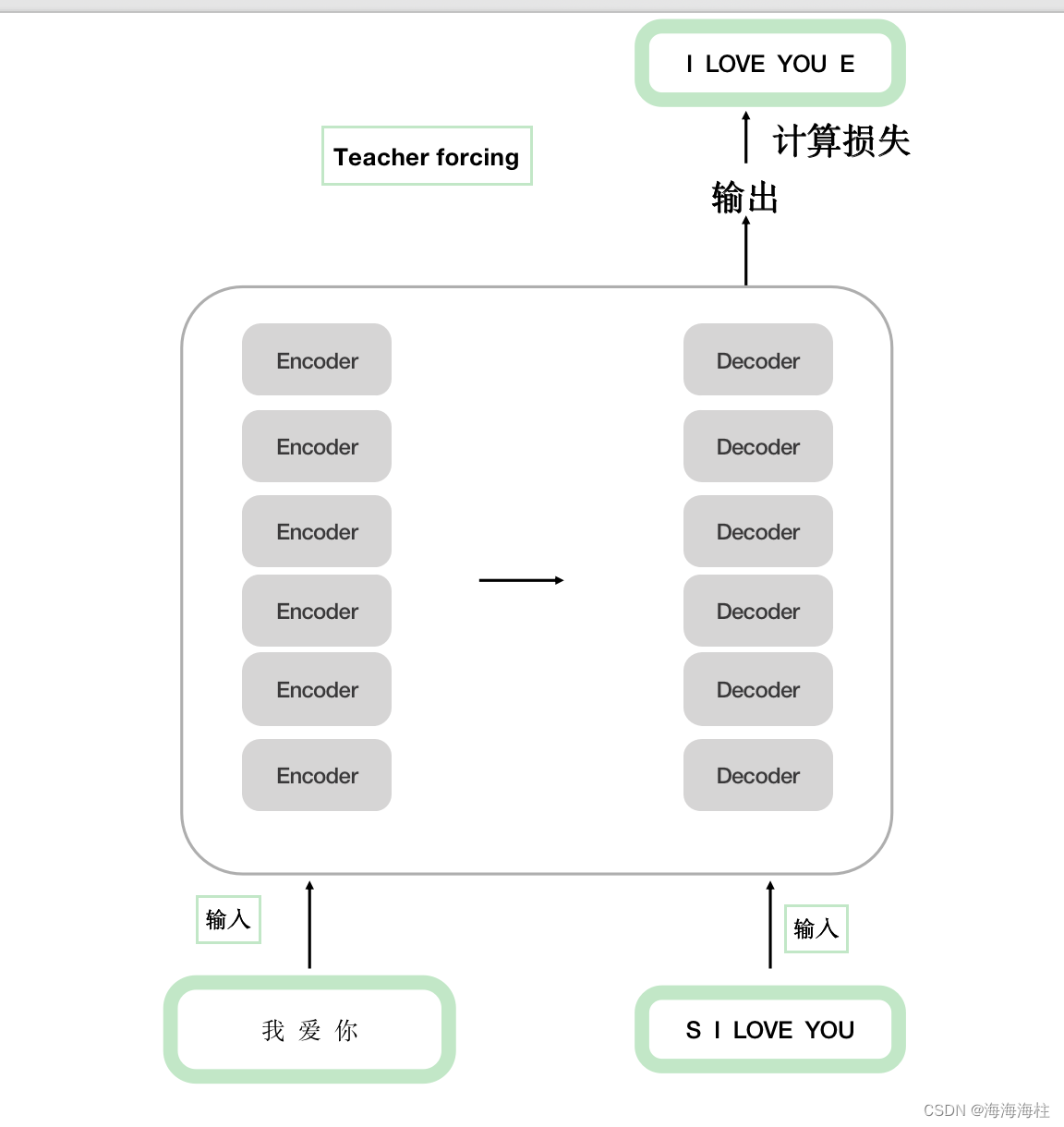
整体网络架构代码
前置条件
## 句子的输入部分,batchsize为1 ,3 ,src_len P为padding
sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E']
# Transformer Parameters
# Padding Should be Zero
## 构建词表
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6}
tgt_vocab_size = len(tgt_vocab)
src_len = 5 # length of source
tgt_len = 5 # length of target
## 模型参数
d_model = 512 # Embedding Size
d_ff = 2048 # FeedForward dimension 前馈神经网络的维度
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer 6个encoder
n_heads = 8 # number of heads in Multi-Head Attention 8个头注意力机制
model = Transformer()
整体结构
## 1. 从整体网路结构来看,分为三个部分:编码层,解码层,输出层
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder() ## 编码层
self.decoder = Decoder() ## 解码层
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
## 输出层 d_model 是我们解码层每个token输出的维度大小512,
##之后会做一个 tgt_vocab_size(词表大小) 大小的softmax
##tgt_vocab_size: 7
def forward(self, enc_inputs, dec_inputs):
## 这里有两个数据进行输入:
## 一个是enc_inputs 形状为[batch_size, src_len],主要是作为编码段的输入[1,5]
## 一个dec_inputs,形状为[batch_size, tgt_len],主要是作为解码端的输入[1,5]
##src_len tgt_len 为输入输出的最大长度 --max_len
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
## enc_inputs作为输入 形状为[batch_size, src_len],输出由自己的函数内部指定,
##想要什么指定输出什么,可以是全部tokens的输出,可以是特定每一层的输出;
##也可以是中间某些参数的输出;
## enc_outputs就是主要的输出
##enc_self_attns:QK转置相乘之后softmax之后的矩阵值
##代表的是每个单词和其他单词相关性;QKT
## dec_outputs 是decoder主要输出,用于后续的linear映射;
##dec_enc_attns是decoder中每个单词对encoder中每个单词的相关性;
##dec_self_attns类比于enc_self_attns 是查看每个单词对decoder中输入的其余单词的相关性;
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(
dec_inputs, enc_inputs, enc_outputs)
## dec_outputs做映射到词表大小
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)),
enc_self_attns, dec_self_attns, dec_enc_attns
Encoder
1.encoder主要分为下图三个部分,输入部分主要由embedding和位置编码(Positional Encoding)组成
2.多头注意力机制(Multi-Head Attention)
3.前馈神经网络
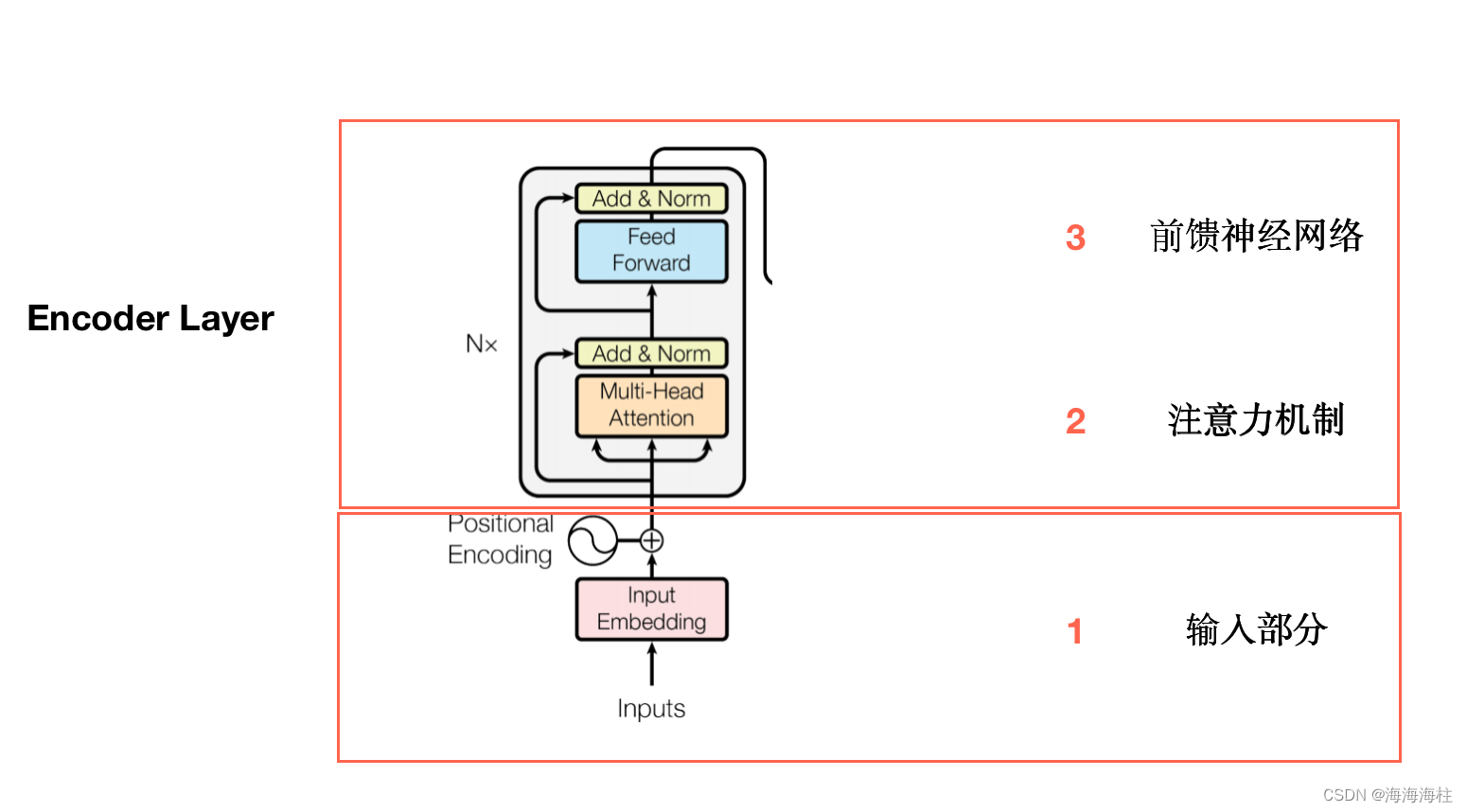
## 2. Encoder 部分包含三个部分:词向量embedding,位置编码部分,注意力层及后续的前馈神经网络
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
## 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_model 5*512
self.pos_emb = PositionalEncoding(d_model)
## 位置编码实现函数,这里是固定的正余弦函数,也可以使用类似词向量的nn.Embedding获得一个可以更新学习的位置编码
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
## 使用ModuleList对多个encoder进行堆叠,因为后续的encoder并没有使用词向量和位置编码,所以抽离出来;
def forward(self, enc_inputs):
## 这里我们的 enc_inputs 形状是: [batch_size x source_len][1,5]
## 下面这个代码通过src_emb,进行索引定位,enc_outputs输出形状是[batch_size, src_len, d_model] [1,5,512]
enc_outputs = self.src_emb(enc_inputs)
#Embedding的输入形状N×W,N是batch size,W是序列的长度,输出的形状是N×W×embedding_dim
## 这里就是位置编码,把两者相加放入到了这个函数里面,从这里可以去看一下位置编码函数的实现;3.
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) #[ batch_size, seq_len,d_model]
##get_attn_pad_mask是为了得到句子中pad的位置信息,给到模型后面,在计算自注意力和交互注意力的时候去掉pad符号的影响,去看一下这个函数 4.
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # batch_size x len_q x len_k
enc_self_attns = []
for layer in self.layers:
## 去看EncoderLayer 层函数 5.
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
位置编码(Positional Encoding)
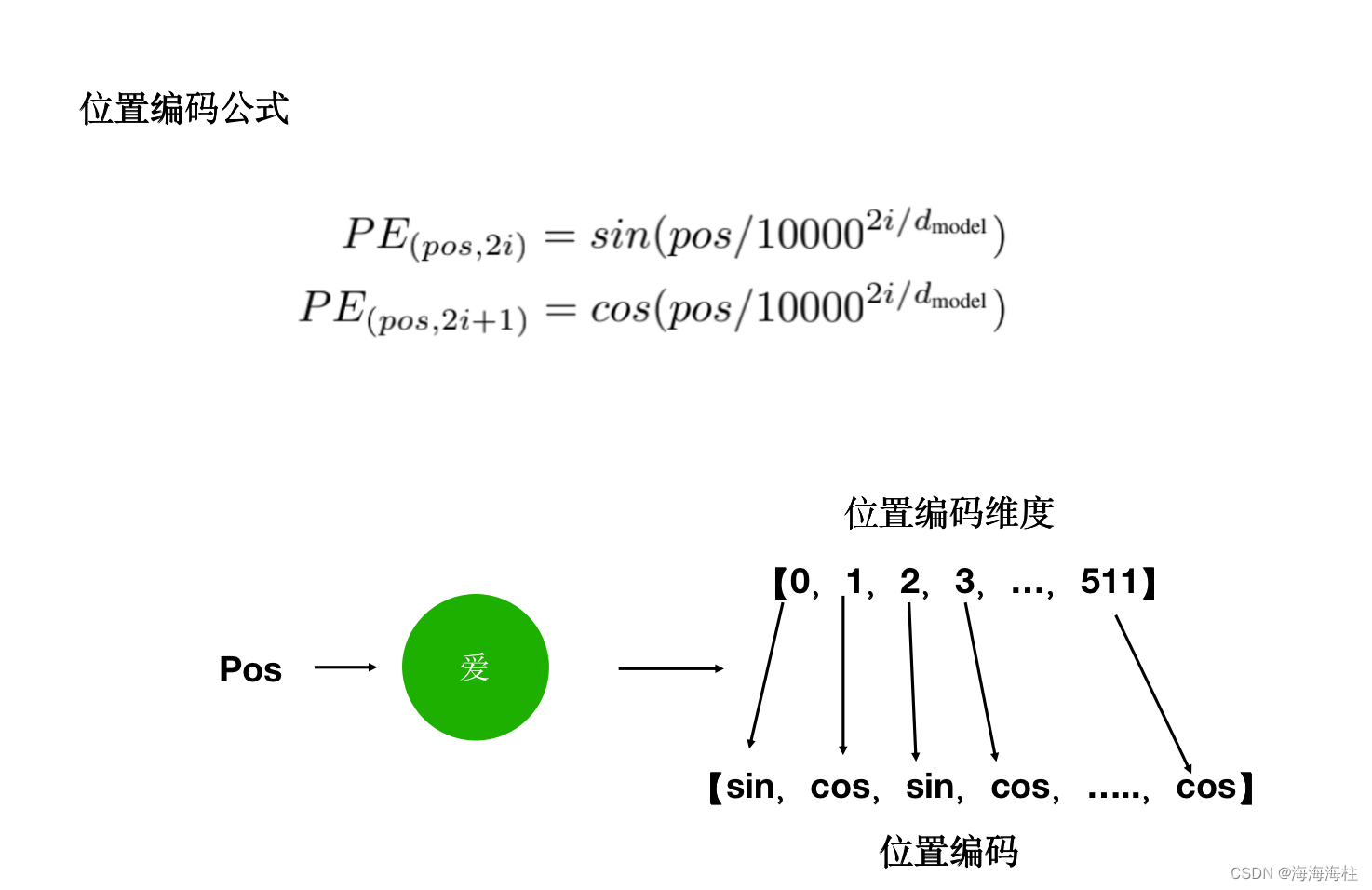

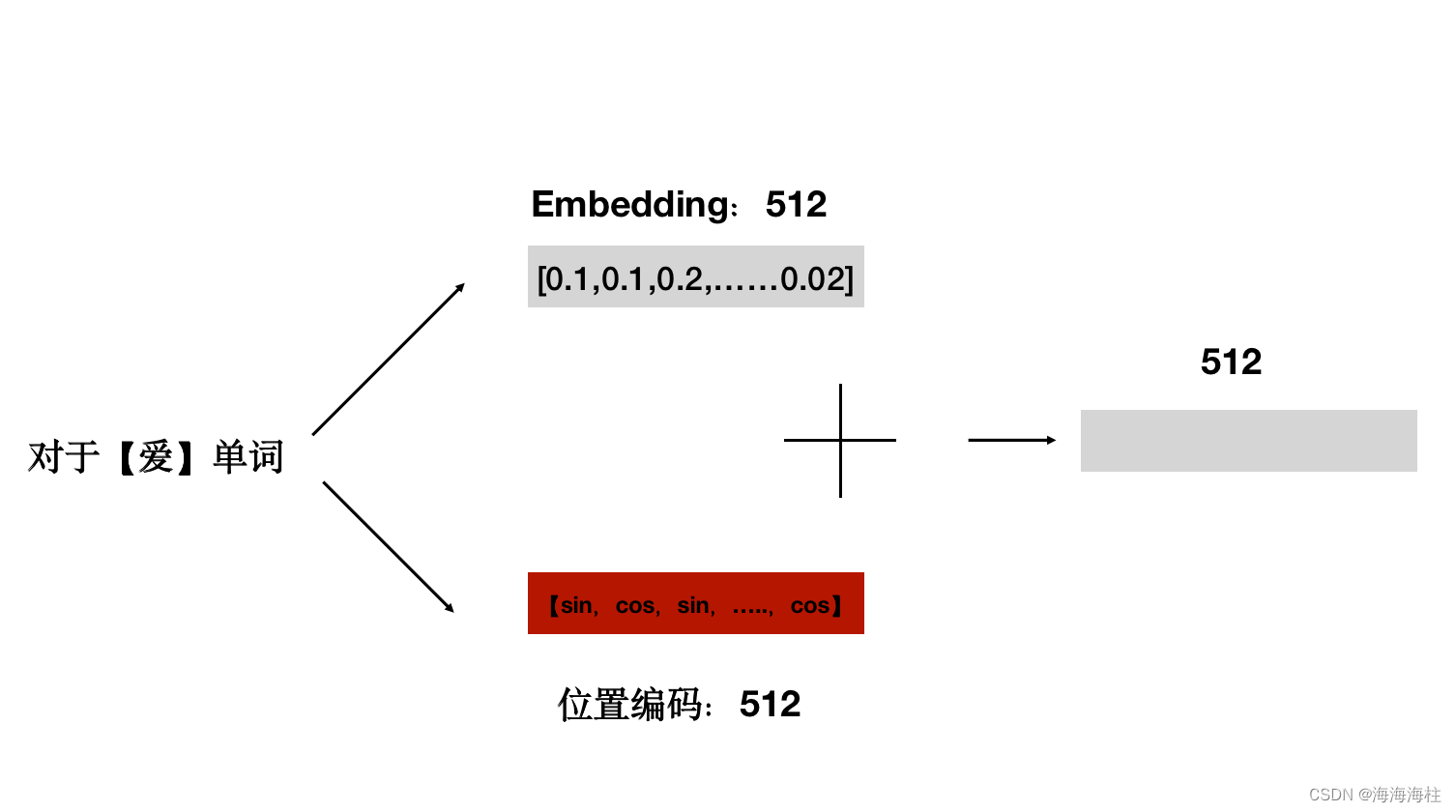
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
## 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;
## 从理解来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;
## pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127
##假设我的demodel是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4...510
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 指定维度插入一维度 max_len *1
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)## 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,补长为2,其实代表的就是偶数位置
pe[:, 1::2] = torch.cos(position * div_term)##这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,补长为2,其实代表的就是奇数位置
## 上面代码获取之后得到的pe:[max_len*d_model]
## 下面这个代码之后,我们得到的pe形状是:[max_len*1*d_model]
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe) ## 定一个缓冲区,其实简单理解为这个参数不更新就可以
def forward(self, x):
"""
x: [seq_len, batch_size, d_model] [5,1,512]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
获得Padding
## seq_q 和 seq_k 不一定一致,在交互注意力,q来自解码端,k来自编码端,
##所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的;
# q,k 自注意力层一致,交互注意力层不一致
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is masking 数字为0的地方为true 为1
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
## 5. EncoderLayer :包含两个部分,多头注意力机制和前馈神经网络
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
## 下面这个就是做自注意力层,输入是enc_inputs,形状是[batch_size x seq_len_q x d_model] 需要注意的是最初始的QKV矩阵是等同于这个输入的,去看一下enc_self_attn函数 6.
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V 最原始的QKV信息
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
return enc_outputs, attn
多头注意力机制
## 6. MultiHeadAttention
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
## 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk,Wv
self.W_Q = nn.Linear(d_model, d_k * n_heads) # 64*8
self.W_K = nn.Linear(d_model, d_k * n_heads) # 64*8
self.W_V = nn.Linear(d_model, d_v * n_heads) # 64*8
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
## 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;
##输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model], V: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
##下面这个就是先映射,后分头;一定要注意的是q和k分头之后维度是一致额,所以一看这里都是dk QK转置相乘 所以维度要相同
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
## 输入进行的attn_mask形状是 batch_size x len_q x len_k,然后经过下面这个代码得到 新的attn_mask : [batch_size x n_heads x len_q x len_k],就是把pad信息重复了n个头上
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
##然后我们计算 ScaledDotProductAttention 这个函数,去7.看一下
## 得到的结果有两个:context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
## 7. ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
## 输入进来的维度分别是 [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]
##首先经过matmul函数得到的scores形状是 : [batch_size x n_heads x len_q x len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
## 然后关键词地方来了,下面这个就是用到了我们之前重点讲的attn_mask,把被mask的地方置为无限小,softmax之后基本就是0,对q的单词不起作用
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores) # 每行softmax
context = torch.matmul(attn, V)
return context, attn
前馈神经网络层
## 8. PoswiseFeedForwardNet 前馈神经网络层
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1) # 2048
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return self.layer_norm(output + residual)
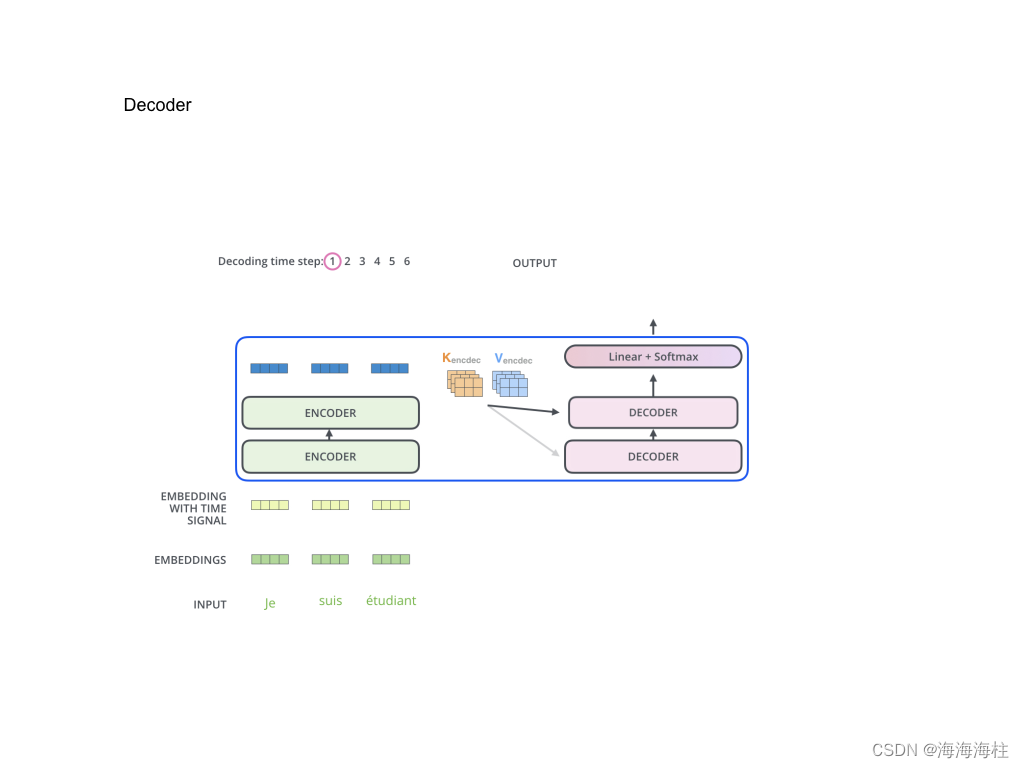
解码端
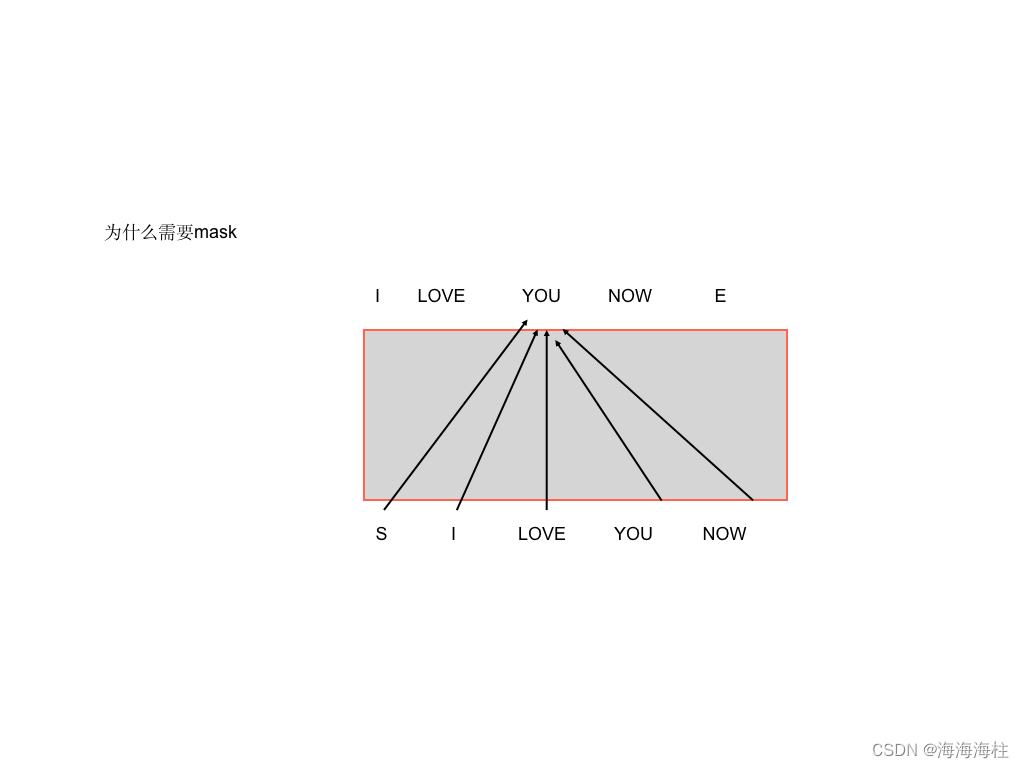
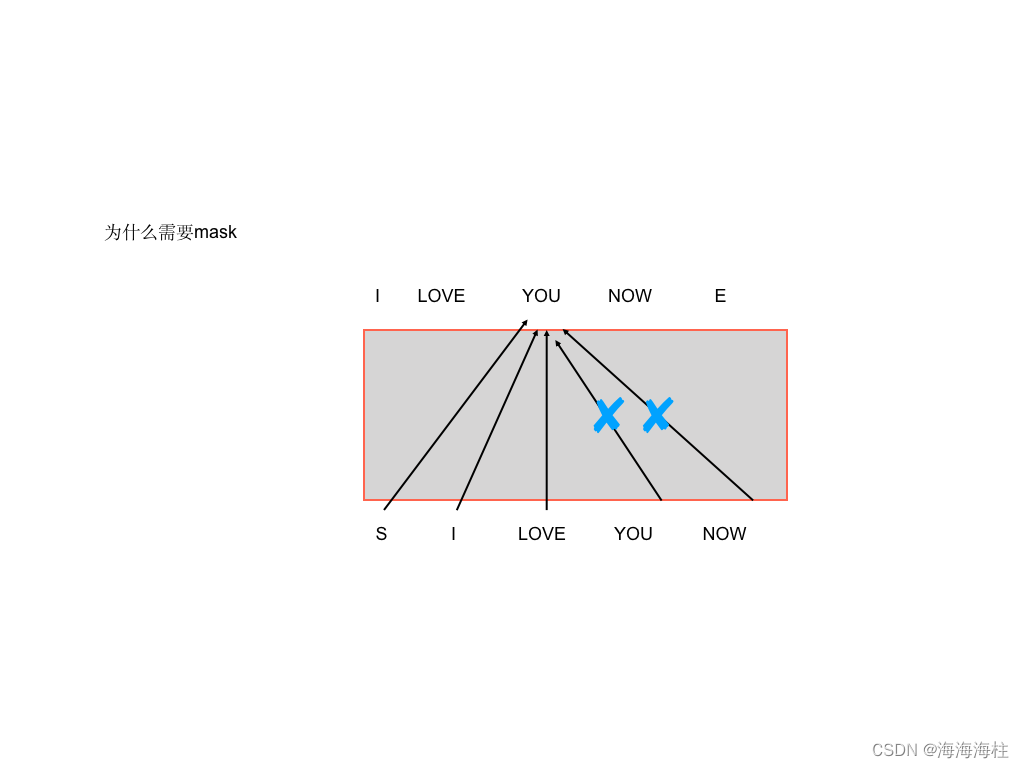
为什么需要mask

class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, tgt_len, d_model]
## get_attn_pad_mask 自注意力层的时候的pad 部分
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) #【1,5】
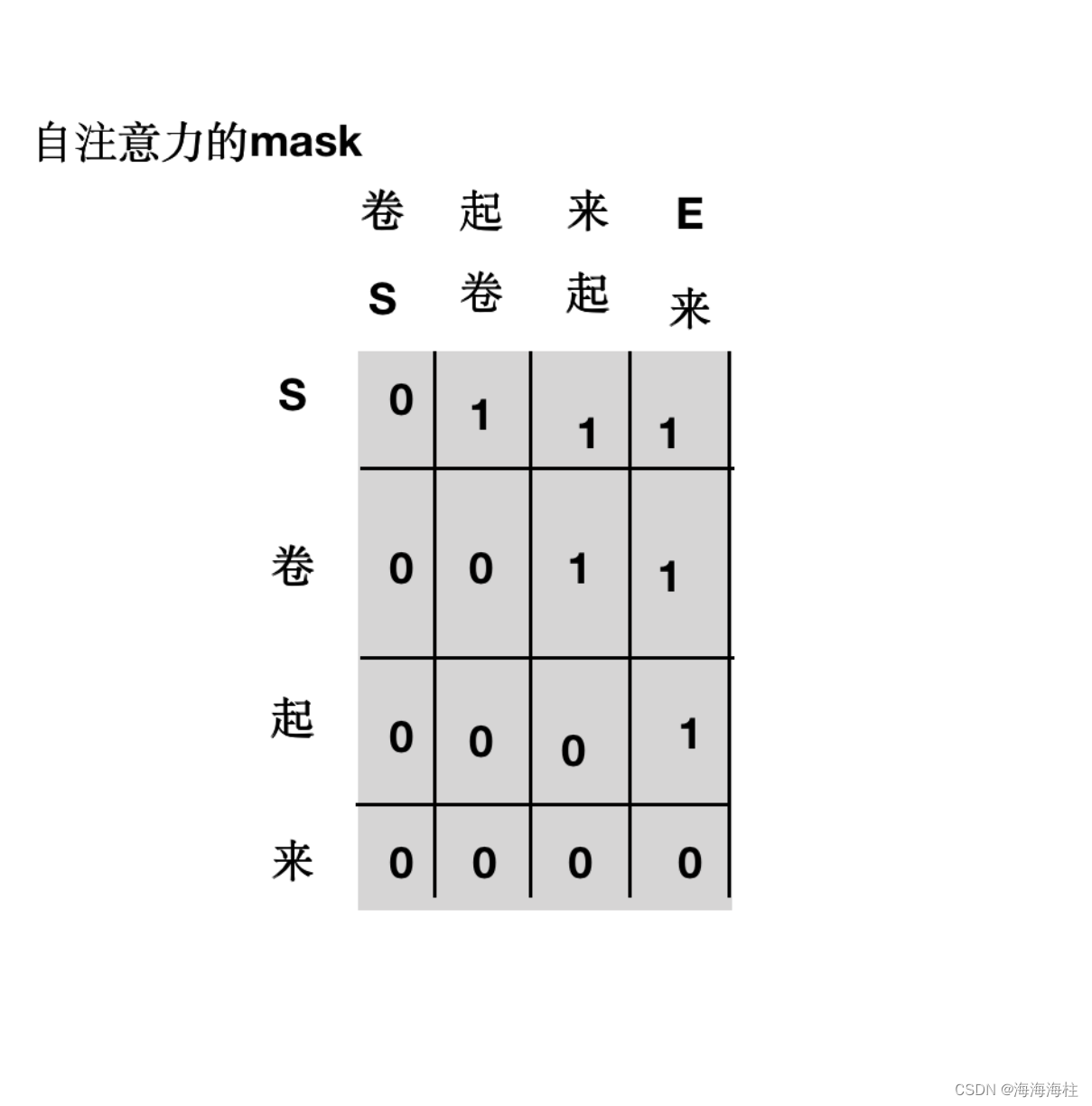
## get_attn_subsequent_mask 这个做的是自注意层的mask部分,就是当前单词之后看不到,使用一个上三角为1的矩阵
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)
## 两个矩阵相加,大于0的为1,不大于0的为0,为1的在之后就会被fill到无限小
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
## 这个做的是交互注意力机制中的mask矩阵,enc的输入是k,我去看这个k里面哪些是pad符号,给到后面的模型;注意哦,我q肯定也是有pad符号,但是这里我不在意的,之前说了好多次了哈
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
解码器自身的MASK多头注意力机制
## 10
def get_attn_subsequent_mask(seq):
"""
seq: [batch_size, tgt_len]
"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
# attn_shape: [batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成一个上三角矩阵
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask # [batch_size, tgt_len, tgt_len]

## 10.
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
编码器-解码器的交互MASK多头注意力机制
参考连接
1.Transformer全局讲解:https://www.bilibili.com/video/BV1Di4y1c7Zm?p=1&vd_source=0a7794c9a3c44085771f4bd95384e406
2.Transformer代码讲解:https://www.bilibili.com/video/BV1dR4y1E7aL/?spm_id_from=333.999.0.0
3,代码加ppt: https://pan.baidu.com/s/1sqIeFxSE4Gm1RhgtQPm5Vg 提取码: mnmr
链接:https://pan.baidu.com/s/1VX_GTFwjnQM-tVfjuHQGeA 密码:8vrb

















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









